
Product
Agents Monitoring
Monitor LLM and agent usage across your applications — conversations, token consumption, latency, cost, success rates, and active models — built on OpenTelemetry GenAI semantic conventions
Agents Monitoring gives you a single view of how your applications use large language models and AI agents: how many conversations they run, what they cost, how long calls take, how often they fail, and which models are actually in use.
The view is built on the OpenTelemetry GenAI semantic conventions. Any instrumentation that emits GenAI-convention telemetry feeds it — no Last9-specific SDK required.
Overview
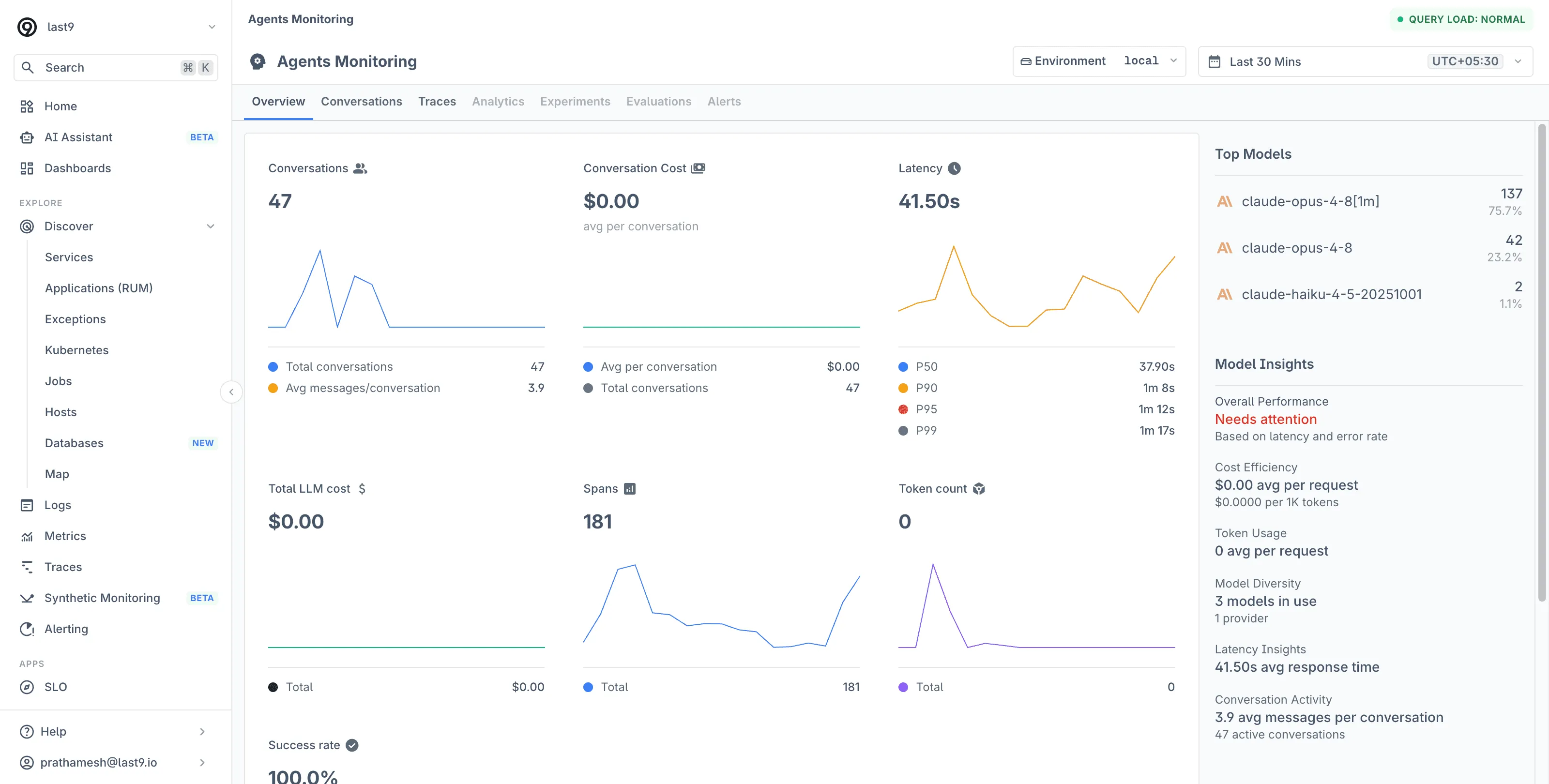
Open Agents Monitoring under the AI section of the sidebar. The Overview tab reports, for the selected environment and time range:
| Card | What it shows |
|---|---|
| Conversations | Total conversations and average messages per conversation |
| Conversation Cost | Average cost per conversation |
| Latency | P50, P90, P95, and P99 call duration |
| Total LLM cost | Spend across all calls in the range |
| Spans | Total LLM spans recorded |
| Token count | Total tokens consumed |
| Success rate | Success and error rate across all requests |
| Top Models | Models serving traffic, with request counts and share |
| Model Insights | Overall performance, cost efficiency, token usage, model diversity |
The Conversations tab lists individual conversations, and the Traces tab shows the underlying LLM spans — a slow or failing call links to the full request trace: the endpoint that triggered it, retries, and downstream work.
Metrics
The overview is backed by GenAI semantic-convention metrics in your Last9 workspace — gen_ai_client_token_usage_total for tokens and the gen_ai_client_operation_duration_seconds histogram for request counts and latency, with gen_ai_request_model and error.type labels. The same series are queryable with PromQL in dashboards, alerts, and ad-hoc queries.
Getting Data In
Instrument your application with any library that emits GenAI semantic-convention telemetry. See the AI integrations for supported options, including the Python GenAI SDK for LLM observability in Python applications.
Troubleshooting
- The overview is empty: no GenAI-convention telemetry has arrived yet. The empty state links to the integrations to set one up. Verify your instrumentation exports
gen_ai_*metrics by checking the metrics explorer forgen_ai_client_token_usage_total.
Please get in touch with us on Discord or Email if you have any questions.