


Extracting Account-Level CDN Metrics from Akamai Logs with Last9
Learn how to extract and analyze account-level CDN metrics from Akamai logs using Last9 for real-time insights and better customer tracking.
Prathamesh Sonpatki
Aditya Godbole
Last9’s Single Pane for High Cardinality Observability
Last9’s Telemetry Warehouse now supports Logs and Traces, offering a unified view for high cardinality observability to simplify monitoring and troubleshooting.
Sahil Khan

Think Data Warehouse, NOT Database.
The software monitoring world is broken because of a TSDB. We deserve a TSDW
Aniket Rao

What needs to change in software monitoring?
A wishlist of things that need to change in the world of software monitoring
Aniket Rao

Back to the Future: The R-C-A of alerting
Dissecting the RCA of Alerting - Reliability, Correlations, Actionability
Aditya Godbole

Software Monitoring — Stuck in the 00s
A short history of software monitoring, from the 00s. What has changed? Why are things so arcane?
Piyush Verma

Why your monitoring costs are high
If you want to bring down your monitoring costs, you need to shake up a decision paralysis in engineering
Aniket Rao

The unresolved cost of High Cardinality
Fulfill all your food delivery orders this December 31st by taming High Cardinality data with Last9 😉
Prathamesh Sonpatki

Why you need a Time Series Data Warehouse
What is a Time Series Data Warehouse? How does it help in your monitoring journey? How does it differ from a Time Series Database? That and more
Rishi Agrawal
Real-Time Canary Deployment Tracking with Argo CD & Last9
Use Last9's powerful change events to track success of canary rollouts via ArgoCD
Preeti Dewani
Monitor Google Cloud Functions using Pushgateway and Levitate
How to monitor serverless async jobs from Google Cloud Functions with Prometheus Pushgateway and Last9 using the push model
Aniket Rao

Golang Concurrency Masterclass by Swati Modi at Gophercon 2023
Talk on Golang Concurrency Masterclass by Swati Modi at Gophercon 2023
Last9

Do more with your metrics by Piyush Verma
Piyush Verma's talk at GopherCon India 2022 on Do More with Your Metrics with Last9
Last9
Unwiring High Cardinality - SRE Day 2023
Report from SRE Day 2023, where Piyush Verma - CTO Last9, gave a talk on Unwiring High Cardinality
Last9

How to restart Kubernetes Pods with kubectl
A simple reckoner on how to restart a Kubernetes pod with kubectl
Anjali Udasi

Levitate: Last9’s Managed TSDB Now on AWS Marketplace
Levitate - Last9's managed Prometheus Compatible TSDB is available on AWS Marketplace
Prathamesh Sonpatki

PromQL Macros in Levitate
Define PromQL Macros to standardize complex PromQL queries in Last9
Prathamesh Sonpatki

GCP Managed Service For Prometheus vs. Levitate
A detailed comparison of Levitate and Google Managed Prometheus - Cost, Scale and Ease of Use
Prathamesh Sonpatki
A case for Observability outside engineering teams
Observability is being built by engineers for engineers. In reality, o11y is for all.
Aniket Rao
Understanding the Rasmussen model for failures
What does the Rasmussen model teach us about Site Reliability Engineering?
Nishant Modak

How we tame High Cardinality by Sharding a stream
Using 'Sharding' to tame High Cardinality data for Last9 - Our Time Series Data Warehouse
Piyush Verma

1979, a nuclear accident and SRE
Deep diving into the 'Normal accident' theory by Charles Perrow, and what it means for SREs
Aniket Rao

How we tame high cardinality in time series databases
Engineering innovation to solve high cardinality with Last9 - a multi-part series
Piyush Verma
Swati Modi

What Site Reliability Engineering Needs: A Swarm of Bees
If all companies are software companies, all companies need better Observability to understand how performative their software is
Aniket Rao

Take back control of your Monitoring
Take back control of your Monitoring with Last9 - a managed time series data warehouse
Nishant Modak

Observability is a practice, not a job
Engineering organizations that ship fast have Observability as part of their core DNA.
Aniket Rao

Using a Golang package in Python using Gopy
Using Golang package in Python using Gopy: A simple way to leverage the power of Golang packages in Python applications.
Arjun Mahishi

Who should define Reliability — Engineering, or Product?
Whoever owns Reliability should define its parameters. But who owns the Reliability of a Product? Engineering? Product Management? Or the Customer success team?
Piyush Verma

Observability—OSS vs Paid vs Managed OSS
The Reliability industry needs a managed, non-vendor lock-in answer to spiraling costs, high cardinality and the toil of managing a tsdb
Satyajeet Jadhav

Learnings integrating jmxtrans
JMX metrics give solid insights into the workings of your application. Integrating them with Last9 (our time series data warehosue) required us to jump some hoops with vmagent.
Saurabh Hirani

The neglected tech arctic winter — Internal SaaS expenses
The current tech winter reveals a hard truth: spending on internal tools for tech infrastructure is bloated—and this isn't just a passing cycle.
Nishant Modak

Understanding “Cricket Scale”
How does a DevOps/Site Reliability Engineer plan for "Cricket scale"? How do you warm systems' about to witness 30+ million concurrent users?
Aniket Rao

What is MTBI?
Everything you need to know about Mean Time Between Incidents (MTBI) and how it can help Site Reliability Engineers
Last9
Rethinking Anomaly Detection: Focus on business outcomes
From the trenches at Games24x7 — Sanjay, on how Reliability engineering should drive core business metrics
Sanjay Singh
Observability is dead, long live observability
No tool can magically offer you 99.999s. Observability is largely about the basics. And basics are boring. But, boring is hard. Boring is battle tested.
Aniket Rao
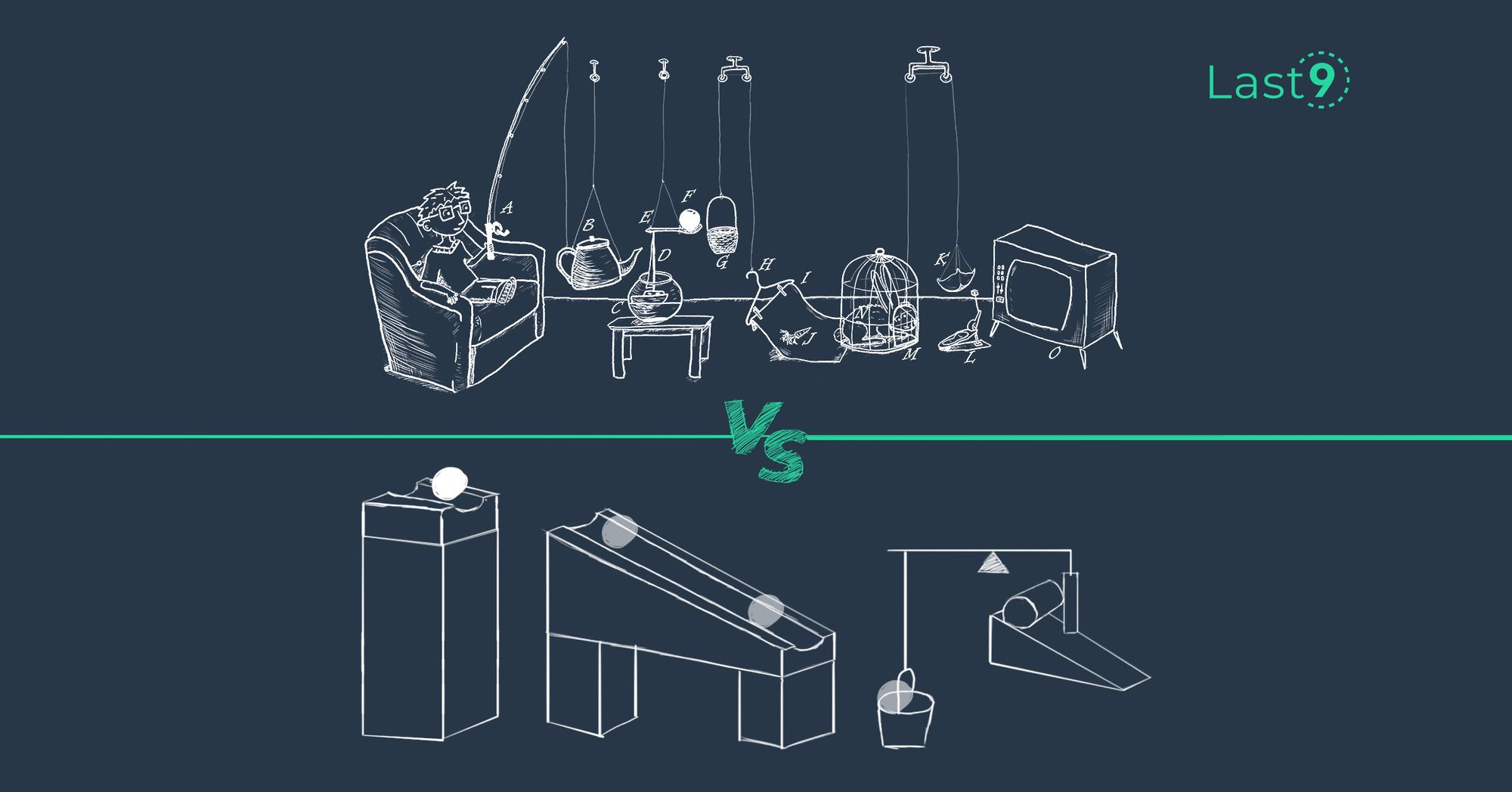
Self-managed Prometheus vs Managed Prometheus
What are the differences between Self-managed Prometheus vs Managed prometheus? How do you choose what works for you?
Last9
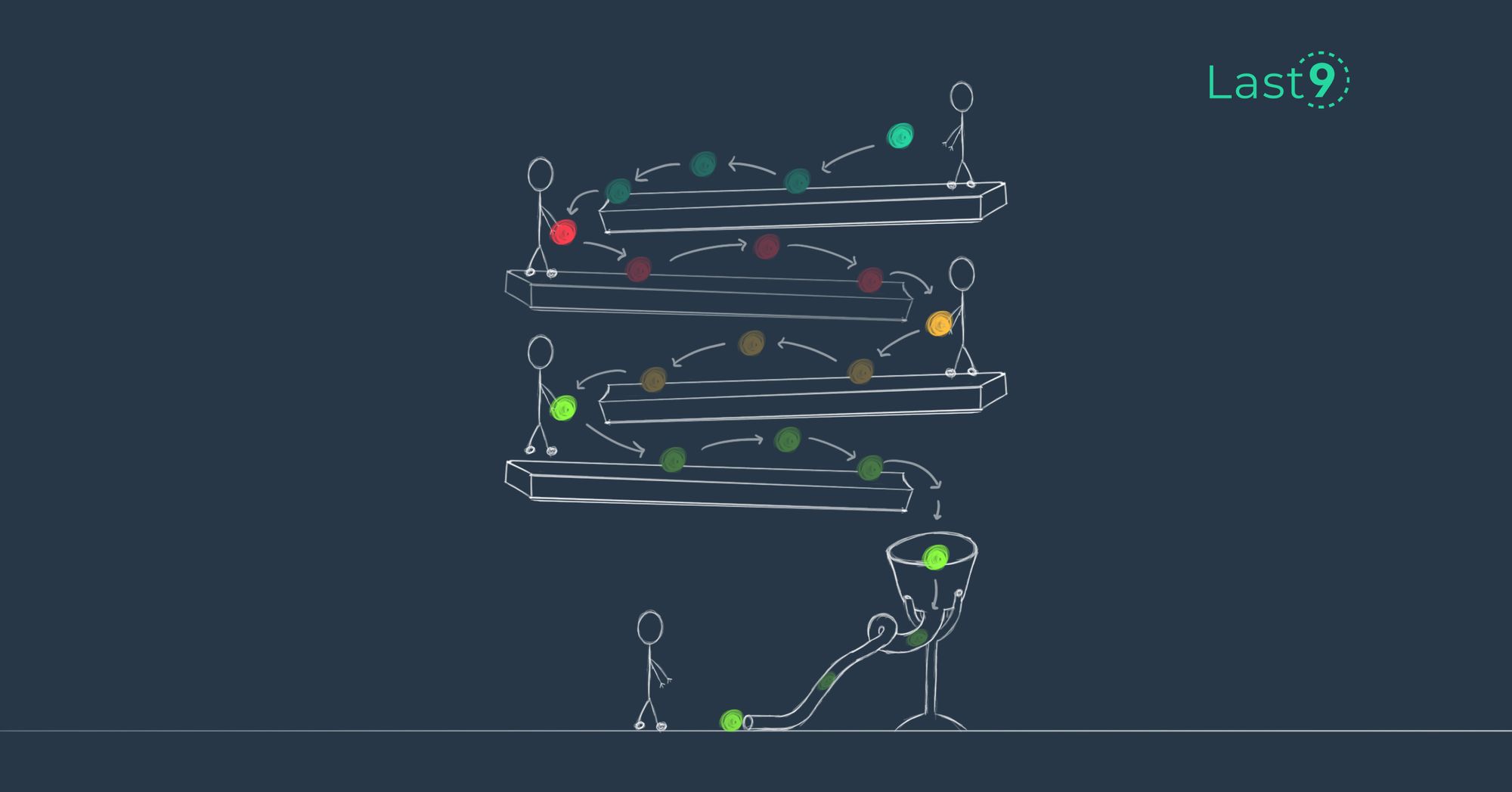
The importance of structured communication in the world of SRE
How you communicate helps build your 9s. In the world of Site Reliability Engineering, this is crucial. How do you do it?
Saurabh Hirani
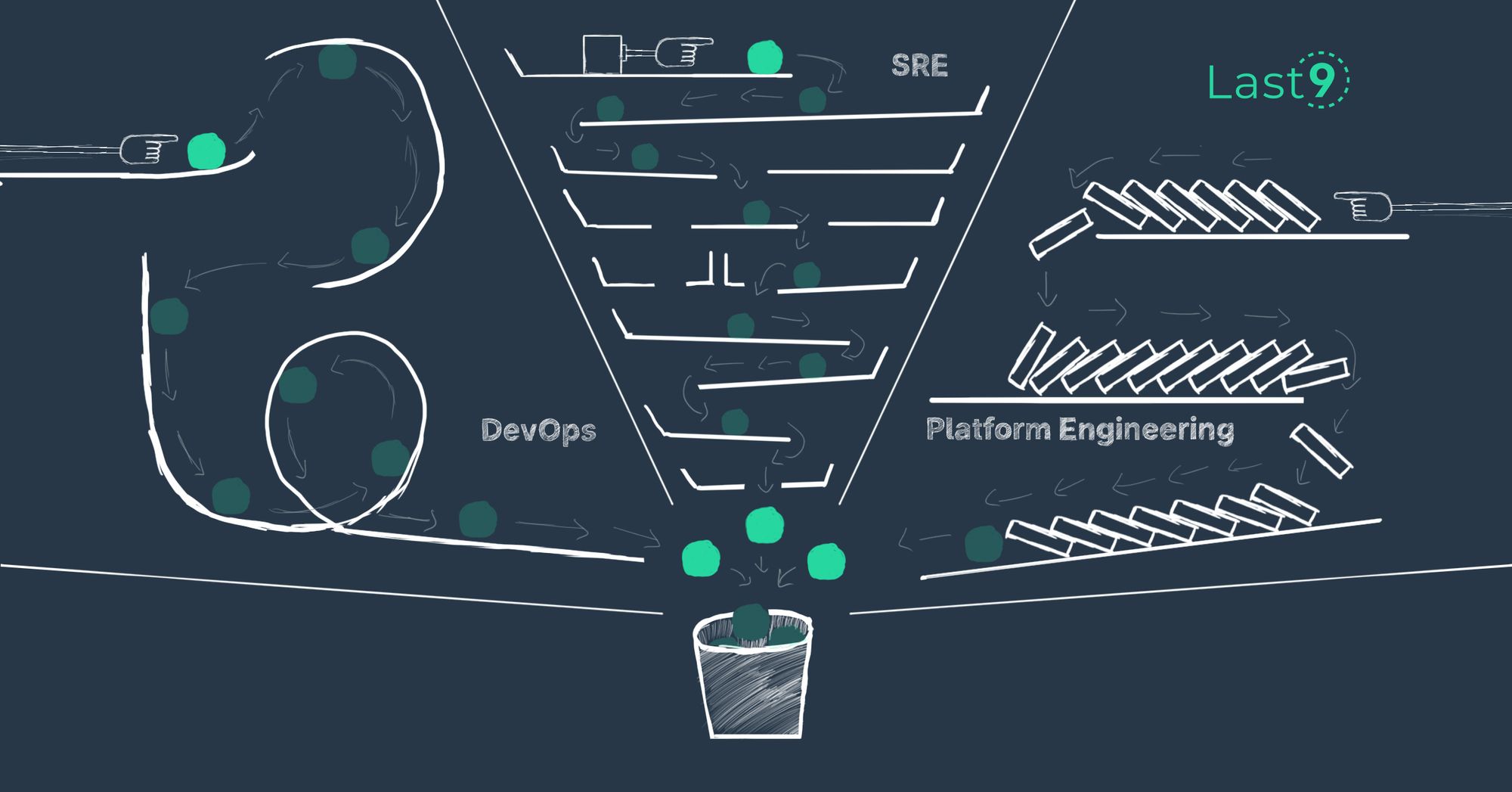
The difference between DevOps, SRE, and Platform Engineering
In reliability engineering, three concepts keep getting talked about - DevOps, SRE and Platform Engineering. How do they differ?
Prathamesh Sonpatki
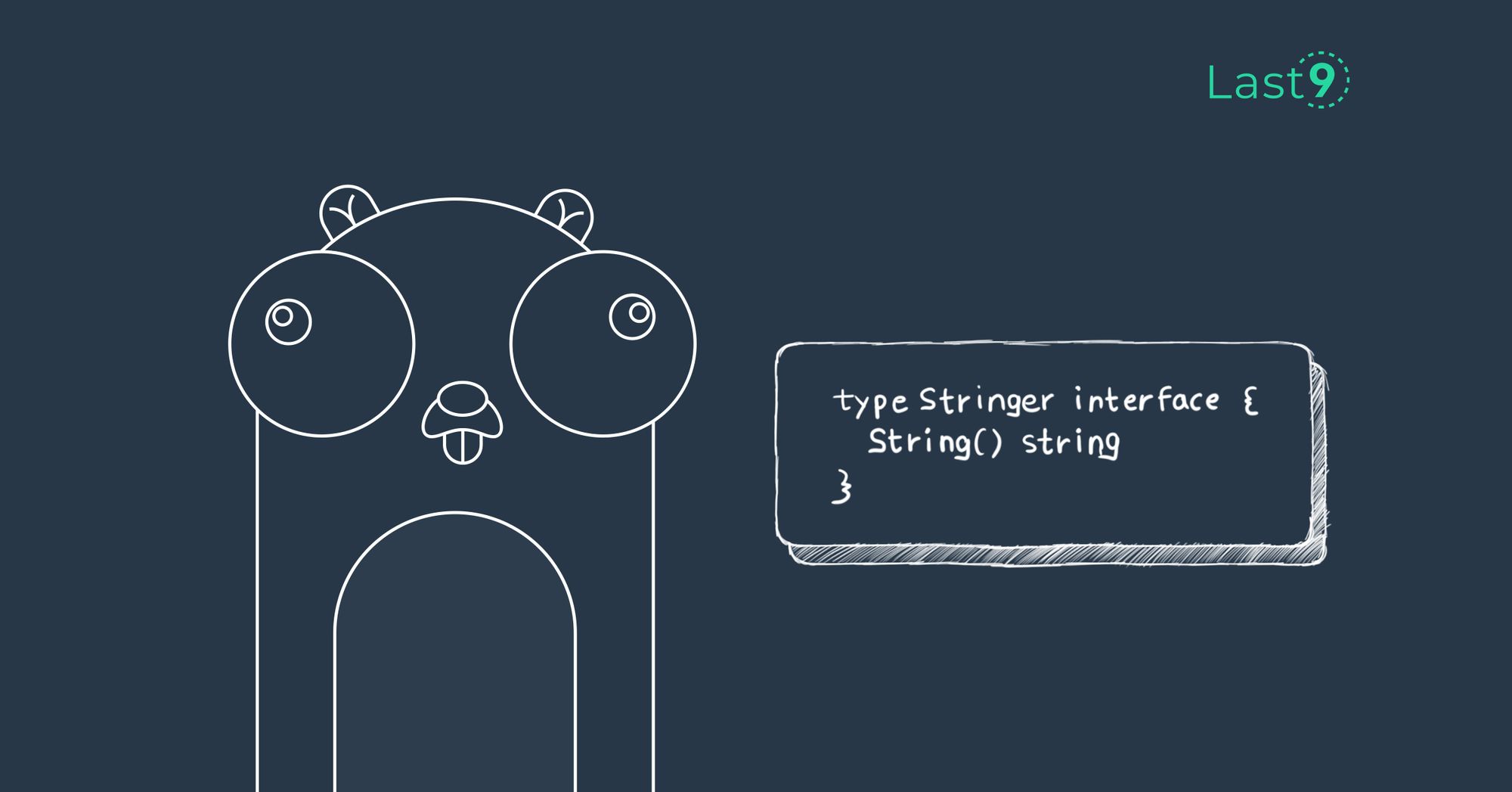
Golang's Stringer tool
Learn about how to use, extend and auto-generate Stringer tool of Golang
Arjun Mahishi
How to improve Prometheus remote write performance at scale
Deep dive into how to improve the performance of Prometheus Remote Write at Scale based on real-life experiences
Saurabh Hirani
India vs Pakistan: SRE and the Shannon Limit
How does one ‘detect change’ in a complex infrastructure, so you don’t lose out on critical revenues — A short SRE story
Satyajeet Jadhav
Battling Alert Fatigue
What is Alert Fatigue and techniques to reduce it
Last9
SLOs, SLIs, and SLAs: Understanding Key Service Metrics
A guide to set practical Service Level Objectives (SLOs) & Service Level Indicators (SLIs) for your Site Reliability Engineering practices.
Last9

Kubernetes Monitoring with Prometheus and Grafana
A guide to help you implement Prometheus and Grafana in your Kubernetes cluster
Last9
Why We Auto-Delete Slack Messages at Last9
At Last9, we auto-delete Slack DMs after 2 days. This pushes teams to improve documentation, reduce tribal knowledge, and own accountability.
Nishant Modak

Static Threshold vs. Dynamic Threshold Alerting
What's the difference between Static Threshold vs Dynamic Threshold Alerting? Do you really know when and how to use each threshold type?
Last9

How we won Dukaan over
5 meetings. 1 month. Subhash and his team’s velocity on decision-making, moving fast, and radical candor, are a breath of fresh air in the Indian startup ecosystem.
Aniket Rao
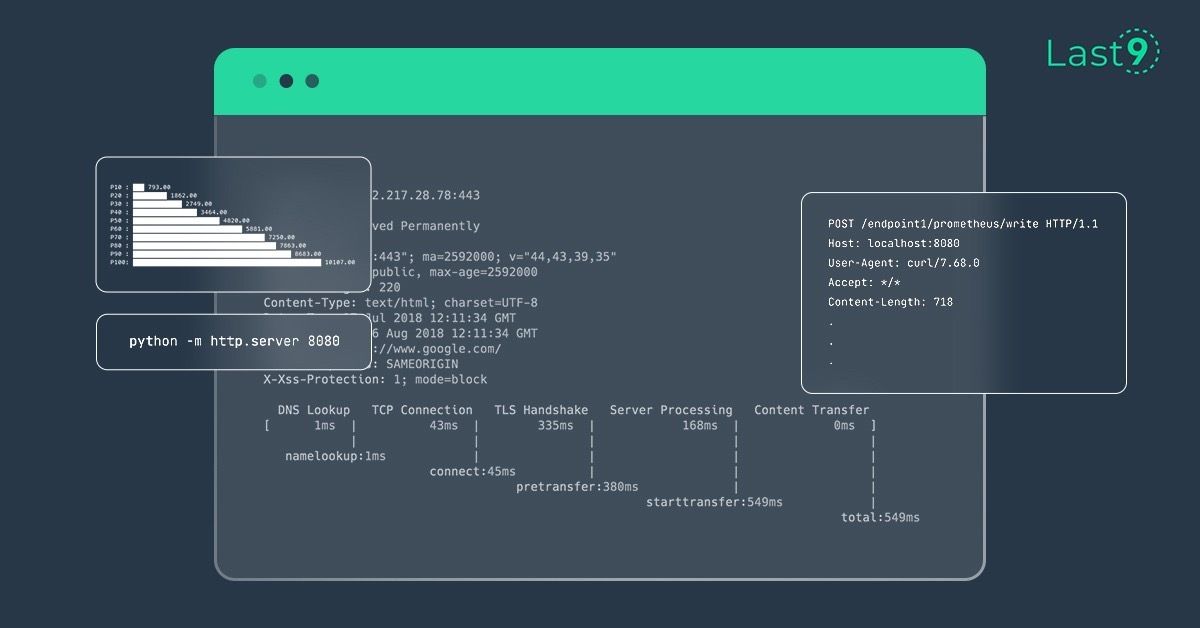
How to calculate HTTP content-length metrics on cli
A simple guide to crunch numbers for understanding overall HTTP content length metrics.
Saurabh Hirani

Choosing Effective SLIs
Practical advice to choose an effective SLI.
Akshay Chugh

Running a Database on EC2 is Slowing It Down
Learn everything about the advantages of EC2, it's use cases and how to optimize EC2 further.
Jayesh Bapu Ahire
Akshay Chugh

Doing SRE the Right Way!
A well-thought-out approach to SRE, which will help site reliability engineers and software engineers develop and maintain a useful, consistent, and effective SRE strategy for their products!
Piyush Verma

Microservices - Tracking Dependencies
Quick primer into microservices architecture and the importance of tracking dependencies
Akshay Chugh
Jayesh Bapu Ahire

SLOs eased
You can either love running or hate running, but you will definitely love this analogy - take a fresh look at SLOs!
Piyush Verma
Saurabh Hirani

Rescuing a SPAghetti React project
Practical tips for rescuing a SPAghetti React JS project. With confidence and a shared mental model, we made the codebase reliable and easier to manage.
Prathamesh Sonpatki

One year at Last9
Celebrating one year at Last9! From uncertainty to growth, it's been an amazing journey with an inspiring team and exciting challenges.
Prathamesh Sonpatki