

Software systems are getting more complex by the day, and there are more components to a software system than ever before. Though that’s not necessarily bad, it can make it more challenging to ensure that the system you create is performant, available, and reliable — essentially, applicable to the end users.
This article will show you how to effectively use service levels to get a good grip on your system’s performance, availability, and reliability, including a deep dive into the best methods for defining Service Level Indicators (SLIs) for different types of services.
First, let’s get started with a quick refresher on SLIs. An SLI measures the level of service provided by a system or part of a system. It is a quantitative measure that captures key metrics, like the percentage of successful requests or completed requests within 200 milliseconds, for example. Once you have clearly defined SLIs, you can define your Service Level Objectives (SLOs), which make up an overview of a company’s goals and set a target of the SLIs for your team to follow. Finally, you can promise your end-users the level of service you will provide. This promise is realized through a Service Level Agreement (SLA). Breaching the agreement has consequences for the service provider.
Do checkout out our quick primer on everything SLOs!
A simple example is a video streaming service that charges its users $12/month and promises that its service will not be unavailable for more than a cumulative amount of fifteen minutes per month. It won’t charge a user for the next month if it breaches the agreed service level. The internal targets of the teams are often more aggressive, however. They might be internally targeting fewer than five minutes of downtime a month. In this example,
- SLI is the availability of the streaming service
- SLO is the target of fewer than fifteen minutes of allowed downtime per month (or the internal target of fewer than five minutes of downtime per month) is the SLO, and,
- SLA will be the consequences for the service provider if the SLO is breached
Intriguing, isn’t it? Head over to SLA vs SLO where the differences are explained in detail
The Need for SLIs
Building observability in your application isn’t just meant to ease a developer’s job in writing and debugging code; it also facilitates looking at the system from different angles at all times with varying degrees of detail.
Well-defined SLIs can provide continuous insight into a system and its services using observability data. Aside from monitoring the availability of services, you can achieve many use cases by defining good SLIs and ensuring that their objectives are met.
Consider a few use cases that demonstrate the importance of SLIs:
Gauging Customer Experience
It isn’t easy to precisely recreate the experience your customers have had from observability data alone. Still, the aggregated data from service level indicators prove to be quite valuable, especially when combined with other ways of gauging customer experience, such as A/B testing, surveys, etc.
The core idea behind creating service levels is to enhance the user experience by identifying bottlenecks, service degradation, and other issues. This is why your service promises to your customers are a great starting point for building your SLIs.
Improving Graceful Degradation
Service levels provide a great way to gauge end-user experience; however, the benefit of defining service levels is not limited to that. You can use the observability data combined with the service level data to figure out which services within your system are being gracefully degraded after failure and which essential services aren’t performing as well as expected.
Suppose you cannot identify degraded user experience. In that case, it may be because some of the critical SLIs are missing, and you might be monitoring things that don’t matter.
Enhancing Resource Efficiency
While the latency, throughput, and response time metrics are directly related to the availability of the application, these metrics also say a lot about the efficiency of the system design and the hardware resources used by the application. Using service-level metrics, you can quickly identify the network, disk, and cache bottlenecks.
In combination with some other OS-level metrics from the resources, you can also use this data to determine if you have under-provisioned or over-provisioned your resources.
Driving Engineering Decisions
Finally, if the SLIs are defined correctly, identifying areas for improvement in your application is relatively easy. Using all this data about customer experience, service levels, and more, engineering teams can better allocate resources and budgets to the things that matter, such as fixing known issues that hamper good customer experience.
Depending on the maturity of your application, there might be many other factors to consider for deciding where to allocate resources. Still, you can always benefit from consulting user experience data and SLIs for insights.
Choosing SLIs Effectively
You must take several steps to choose excellent and effective SLIs for your application. The following four steps are critical to that end:
1. Identifying System Boundaries
You can expose system metrics for your application at two different levels. The most granular exposure of data is inefficient writing and debugging of code, but that is not necessarily required to comply with service levels.
The other is the exposure to metrics defined at the system boundaries—i.e., the application points with which the customer can interact directly.
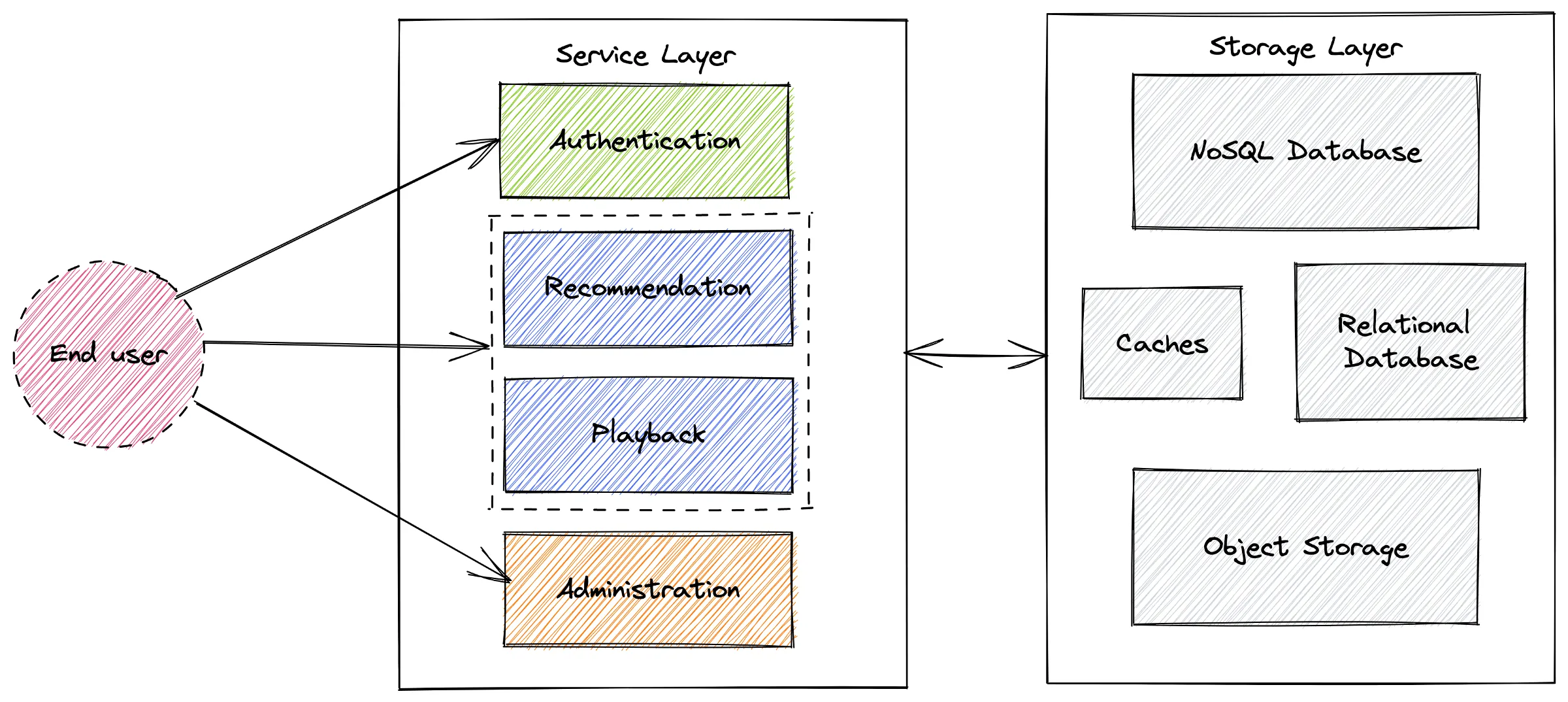
So, the first order of business in choosing SLIs is identifying the system boundaries. This will be followed by several other steps to get to the right SLI. In the streaming platform example referenced above, many services have been grouped within three broad system boundaries — authentication, recommendation and playback, and administration.
In this example, the authentication system boundary would contain all the services related to logging in, forgetting or resetting the password, signing up for SSO sign-in, and more. The recommendation and playback services are part of the same workflow, so they have been grouped. The administration services will include everything from payments and memberships to security, privacy, and more. The end-user can interact with these three service groups directly, acting as the system boundaries to help you set your SLIs.
2. Differentiating Service Types
There are two types of services that you can use in an application: synchronous and asynchronous services, which are distinguished by the way they fulfill requests.
Synchronous services respond to a request immediately, whereas asynchronous services put your request into a queue and respond to it when its turn comes.
These two service types will have different ways of measuring SLI metrics. The most prominent metric that differs is latency. For instance, latency for synchronous services is the percentage of requests served in less than 200 ms. However, latency can be defined as the percentage of requests in a queue served in less than 200 ms for asynchronous services.
Synchronous services are mainly used where the end-user needs immediate feedback—for example, placing an order, making a payment, or logging in and out of a system.
Asynchronous services are used for more data-intensive workloads, such as downloading an archive of your data, downloading your watch history, or getting a tax report from an investment application. Consider the payment administration services in the video streaming application example discussed earlier. Making a payment would be a synchronous service, but getting a detailed receipt of the order might be asynchronous.
Since synchronous services provide immediate feedback, they are often critical for in-app user experience. When you’re paying for a subscription or buying a product, what you care about the most is that your order goes through successfully. Whether you get a confirmation email or an invoice within three seconds or fifteen seconds, or a minute doesn’t matter. Because different things are expected of these services, different indicators will be required to judge their performance.
3. Identifying Relevant Metrics
This step requires you to pinpoint the user’s features via a system boundary. The idea is to drive SLIs around the functionality and capabilities of the features. Once these features are identified, you need to establish what their availability means for the customer.
In addition, the service type also plays a vital role in helping you decide what to track. Based on these two factors, you can determine what availability metrics to use and define them in a way that makes the most sense for the system boundary.
As you are expecting an immediate response to a request from a synchronous service, you can define availability and latency metrics as follows:
- Availability — the percentage of requests served successfully, i.e.,
100 * (total requests served successfully / total valid requests) - Latency — the percentage of requests served within 200 ms, i.e.,
100 * (total requests served / total valid requests)
Meanwhile, for asynchronous services, we have to think in terms of throughput, not only in terms of latency. As mentioned earlier, asynchronous services mainly deal with compute-intensive work, such as image processing, PDF generation, archive download, etc. Thus, the amount of data processed per unit of time is a better indicator of the service than the latency because latency will tell you how much of the work has been done from the queue. That alone will not be enough to gain insights into the end-user experience. In addition to latency, you can define metrics such as throughput as follows:
- Throughput — the percentage of time where bytes served per second were greater than a particular threshold, i.e
100 * ((time where bytes served > threshold) / total time with bytes served)
This is especially useful in audio and video streaming platforms, as streaming platforms rely heavily on buffering, which is an asynchronous operation.
4. Monitoring and Tuning Metrics
Once the system boundaries and metrics are defined and implemented, you can start tracking the metrics.
The first thing to do here would be to establish a baseline in keeping with your application’s resources. You can also use other telemetry data to enhance your system’s efficiency in using the provided resources. This baseline will then help you tune your SLIs accordingly.
As you can see, setting SLIs is not a one-off process. Although the major work is always done at the beginning in identifying system boundaries and metric definitions, there’s always some room for improvement after looking at the data for these metrics.
On the one hand, it is good to tweak and tune SLIs over time to get a better user experience perspective. On the other, it is also important not to change the definitions too frequently, as this may cause you to lose the historical perspective of the metric, leaving you unable to compare it to past data properly. Thus, a balanced approach is required.
Conclusion
Identifying effective SLIs for your application is an essential exercise. It gives insight into customer experience and helps you drive architectural decisions and resource allocation. Having a good understanding of the different factors that make good SLIs is essential to identify them correctly. This article showed you the various things you need to consider while deciding on your SLIs and the benefits of defining good and effective SLIs to your application.
(A big thank you to Kovid Rathee for his contribution to this article)

