
I gave a talk at react.geekle.us today about improving reliability of our React app.
Here are slides of that talk.
Here is transcript of the talk.
Hello all, my name is Prathamesh Sonpatki. I work at Last9 building a world class operational intelligence platform for SREs. The Last9 platform helps people find root cause of failures, increase efficiency and prevent failures with easy. Today I am going to talk how we improved reliability of our frontend codebase and made it manageable. This talk does not have any internals about React or related technologies but has practical tips that worked for us in a fast paced environment. The ideas are not revolutionary. In fact you will find that ideas are very simple in theory but applying them together does weave the magic, did for us.
Build mode
Every project starts with blank slate. We are happy as we are building something out of thin air. We are shipping features quickly and are happy. We also started with a simple Create React project. When a new project starts, we are always building and learning from customers and building, all of this happens together. First few months of a startup are of ideation phase where hypothesis are tested in real world, features are shipped and changed frequently.
But if we don’t pay attention to the codebase, it begins to rot. Adding new features becomes difficult. Nobody remembers why that line no. 338 exists in index.js or why that one single file has become tooo big. Fixing one bug creates other bugs. We get frustrated. Nobody wants to touch that piece of code. It adds mental overhead.
Reality
This is what happened with us after few months and the reality sunk in that this codebase is becoming difficult to manage. Rewriting everything was not an option that was available to us as our customers were already using the app and we didn’t have bandwidth to start from scratch.
So what do we do? Of course first step of fixing the mess is accepting that yes there is mess. Only after that we can start fixing it. Let’s talk about what is bad code. Here I am not talking in generic terms but what bad code meant for us in our application.
Our code was hardly extensible. Enhancing existing feature meant breaking something else. This resulted into code duplication. Code duplication resulted into bugs because things were updated at few places but not all. As a result of duplication, the codebase became hard to understand. It lacked consistency. It resulted into surprising bugs when an unrelated part of code was changed.
Bad code to Good code
Let’s talk about what Good code meant for us. From code reliability and management point of view, there are 3 things that I am looking for in a codebase.
- Confidence
- Safety
- Shared mental model
Let’s talk about each one of them in detail.
Confidence
Pure functions
Confidence is all about being certain about a piece of code doing one thing and doing it well. And also not doing anything else :) A lot of times we forget this last point of not doing anything else and try to put more logic into an existing function. This invariably results into more conditional code.
function validateTimestamp(atTimestamp) { if (atTimestamp > 0) { return true; }
return false;}function validateTimestamp(atTimestamp) { if (atTimestamp > 0) { dispatch(); return true; }
return false;}function validateTimestamp(atTimestamp, currentUser) { if (atTimestamp > 0) { if (currentUser.admin) { dispatch(); } return true; }
return false;}function validateTimestamp(atTimestamp) { if (atTimestamp > 0) { return true; }
return false;}
validTs = validateTimestamp(atTimestamp);
if (validTs && currentUser.admin) { dispatch();}To mitigate this, we try to write smaller pure functions. They take an input and produce an output. One other benefit of writing such parameterized functions is they are plain JavaScript functions. They have nothing to do about React. We can extract them outside of React components and just start reusing them.
Tests
Such functions are also easier to unit test. Tests also help us in having confidence in our code. Writing testable code is as important as writing new code. The pure functions that we discussed earlier help in writing unit tests. Our test coverage at the time of reality check in time was very low but every bug fix was coupled with a test and every pure function was accompanied with a test. 100% test coverage is a myth but we strived to add tests for every bug fix.
Unit tests and pure functions helped us in increasing reliability code by a margin. But we also wrote end to end integration tests using Cypress. These tests helped us test complicated user workflows. We were unsure about reliability of Cypress tests as sometimes such tests tend to be flaky but they turned out pretty well for us. We did caught some hard to unit test regressions.
Hooks
React 16.8 introduced new Hooks API that allows using state and other React features without writing classes. Though useEffect and useState are widely used and are popular, we also used two more hooks frequently.
useDidUpdateEffect
A lot of times, we did not want to trigger a useEffect on first load of the page. In such cases, we can use the custom hook which skips calling the callback on initial load.
useCallback
Another important hook is useCallback hook. Before talking about it, let’s see how. equality works in JavaScript.
true === true // truefalse === false // true1 === 1 // true'a' === 'a' // true{} === {} // false[] === [] // false() => {} === () => {} // falseconst z = {}z === z // trueSo objects such as arrays and maps are not going to equal to their previous versions during re-renders even when they contain exactly same content. This will result into re-renders when nothing has changed from our perspective.
When passing arguments to functions which are not going to pass referential equality such as arrays or objects, it’s better to wrap it in useCallback.
const isSelected = useCallback( (item) => selectedItems.includes(item), [selectedItems],);
return ( <List classes={{ root: classes.listRoot }}> {listItems.map((item) => ( <ListItem key={item} onClick={() => onSelect(item)} disableGutters classes={{ root: classes.listItemRoot, selected: classes.listItemSelected, }} selected={isSelected(item)} button > <ListItemText classes={{ primary: classes.listItemTextPrimary }}> {item} </ListItemText> </ListItem> ))} </List>);Here selectedItems is an array of items. If we did not wrap this function in useCallback it will get re-rendered all the time as selectedItems will always yield new object. So such functions should be wrapped in useCallback to avoid un-necessary re-rendering.
There is also another hook useMemo which is cousin of useCallback. useCallback works for functions whereas useMemo works for values.
react-hooks/exhaustive-deps
React hooks come with this ESLint rule which you should never disable in my experience. Even Dan Abramov says not to ignore the warning as it will bite us later.
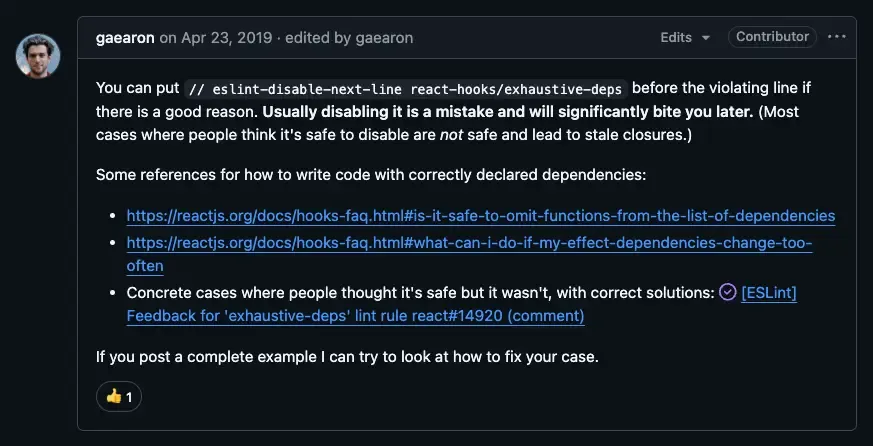
This warning basically tells us that our useEffect is missing some dependencies.
// Before
useEffect(() => { if (graphType === GraphType.Custom && views.length === 0) { setSelectedNodeIdents([]); }}, [views.length]);// After
useEffect(() => { if (graphType === GraphType.Custom && views.length === 0) { setSelectedNodeIdents([]); }}, [views.length, graphType]);Safety toolkit
While the steps that we took to be confident about our code helped, we also need to be diligent about not running into the broken window syndrome again. I call it a safety toolkit that can keep us on our course when we are tempted to deviate from it.
Typescript
Typescript is life saver. It is superset of JavaScript so existing code continous to work but we can add optional typing to ensure correctness of code. Let’s see some examples.
We define a custom type for a timestamp object. Then we reuse it in cases where it is not defined.
We define an enum as well which can map to our API so our API contracts are followed strictly.
export type Timestamp = number;
export type MaybeTimestamp = Timestamp| null | undefined;
export interface TimeRange { from: Timestamp; to: Timestamp;}
export enum ViewType { Custom = 'custom', Automatic = 'automatic',}This is how we can use the defined types.
function validateTimestamp(atTimestamp: Timestamp): boolean { ....}We can even extend the type interfaces for avoiding duplication.
export interface Query { where?: { name: string }; select?: { type: 'custom' | ‘automatic' };}
export interface QueryWithLimit extends Query { limit: number;}Once we started using Typescript strictly, a lot of things happened on its own. Code refactoring became easier. Because the code doesn’t compile until all calls of validateTimestamp function are changed. The code became more reliable and consistent with the API. There were no random surprises out of the blue at runtime. In fact net result was that our Sentry errors were reduced by over 80%.
Bugs started getting discovered early. Code readability and predictability improved. The only gripe I have is the compilation became lot slower than before due to various plugins running.
Converting existing JavaScript code to Typescript is possible and with powerful editor integrations.
ESLint & Prettier
ESLint and Prettier warnings should not be ignored :) Similar to the exhaustive-deps rule discussed earlier, there are various other rules which make our lives as developers easier.
We treat even warnings as errors which fail the CI build. This is achieved by using following lint command.
eslint --fix --ext .js,.jsx,.ts,.tsx src --color --max-warnings 0The max-warnings 0 flag fails the build even when there is one warning. This helped us proactively fix the warning upfront and keep the code quality in check.
Shared mental model

knowledge structure(s) held by each member of a team that enables them to form accurate explanations and expectations
In distributed environment when multiple teams work on different parts of the project, having a common ground on what are we building and how it is getting built is of utmost importance. It allows everyone in the team be on same page so an backend API developer can understand how the API she is building can be consumed by looking at a diagram or document instead of having to read every line of frontend code.
We are bullish on code documentation and treat it as first class citizen. Code documentation is not just comments but workflow diagrams, sequence diagrams. They give more clarity to developers before writing a line of code and also act as bridge between frontend and backend teams.
We also write code comments as and when required for business decisions in the code as nobody can remember the code they have written after a month or so :)
With confidence, safety tool kit and shared mental model, we rescued the codebase and made it more reliable. Now adding features and changes no longer feels like a burden. We are happy again :)
If this resonates with you, do let me know in comments and questions. You can reach out to me on Twitter or Email.

