
Logs Query Builder
Advanced logs query builder mode to parse, filter, transform, and aggregate logs without writing LogQL
Introduction
The Logs Explorer Query Builder provides a visual interface for constructing log analysis queries through a series of stages or operation blocks. Each stage represents a specific data manipulation function.
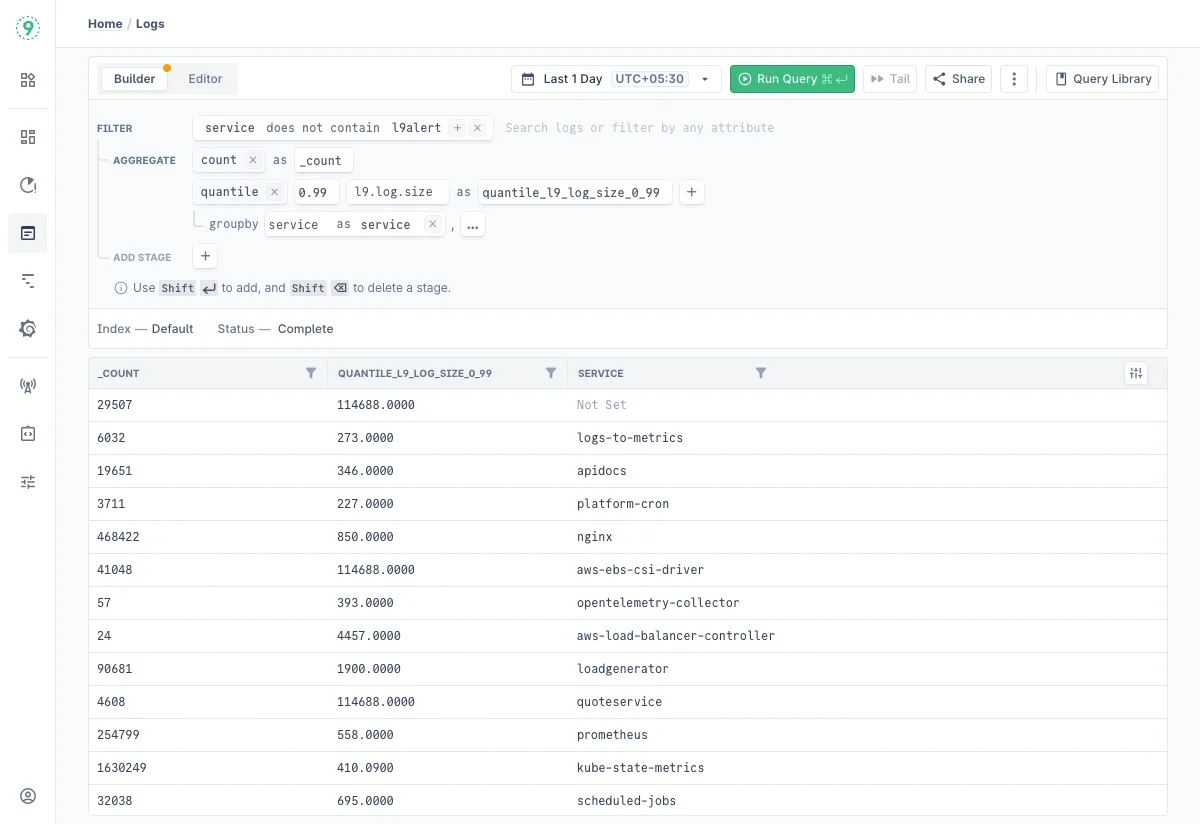
Core Stages
Filter
The FILTER stage allows data filtering based on conditions using various operators:
Supported Operators:
| Operator | Description |
|---|---|
= | Exact match |
!= | Not equal to |
contains all | Partial or exact match of all arguments (AND) |
contains any | Partial or exact match of any argument (OR) |
contains all words | Exact word match of all arguments (AND) |
contains any words | Exact word match of any argument (OR) |
matches | Matches a pattern/regular expression |
does not match | Negative regex match |
Parameters:
- Field name: The field to apply the filter on
- Operator: One of the supported operators
- Value: The comparison value or pattern
A single field and operator can have multiple values. These values are “ORed”. To get the equivalent of AND, use multiple filter stages.
Examples:
resource_source = "kubernetes/infosec/trufflehog"repository != "https://github.com/brightcove/trufflehog.git"message contains all "error", "timeout"message contains any "error", "warning", "critical"body contains all words "connection", "refused"body contains any words "error", "exception", "failed"email matches ".*@company\.com"Contains Operators Comparison
Choose the right operator based on your search needs:
| Operator | Behavior | Example | Matches | Does Not Match |
|---|---|---|---|---|
contains all | Substring match, ALL terms must appear | body contains all "error", "db" | ”database error occurred" | "error in cache” |
contains any | Substring match, ANY term can appear | body contains any "error", "warn" | ”error found”, “warning issued" | "info: success” |
contains all words | Exact word match, ALL terms must appear | body contains all words "error", "db" | ”error from db" | "errors from database” |
contains any words | Exact word match, ANY term can appear | body contains any words "error", "warn" | ”an error here" | "errors and warnings” |
Key differences:
contains all/contains any: Match terms as substrings anywhere in the text. “error” would match “error”, “errors”, “error-handler”.contains all words/contains any words: Match complete words only at word boundaries. The search value is split on non-alphanumeric characters, and each word must match exactly.
How word splitting works:
| Search Value | Words Extracted | Matches | Does Not Match |
|---|---|---|---|
error | ["error"] | ”an error occurred" | "errors found” |
error-message | ["error", "message"] | ”error: invalid message" | "error-messages” |
user@example.com | ["user", "example", "com"] | ”user at example dot com" | "user@example.org” |
Sample RegEx Patterns with matches Operator
The matches operator supports full regular expressions for complex pattern matching on any log attribute, resource attribute, or log body. The field names shown below (email, client_ip, filename, etc.) are examples — you can apply these patterns to any field in your logs.
Here are common patterns:
-
Email Patterns:
# Email addressesemail matches "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"# Specific domainsemail matches ".*@(gmail|yahoo|outlook)\.com$" -
IP Address Patterns:
# IPv4 addressesclient_ip matches "^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$"# Private IP rangesclient_ip matches "^(10\.|172\.(1[6-9]|2[0-9]|3[0-1])\.|192\.168\.)" -
HTTP Status Patterns:
# Error status codes (4xx, 5xx)status matches "^[45][0-9]{2}$"# URLs with API pathsurl matches "^https?://[^/]+/api/v[0-9]+/" -
File and Message Patterns:
# Log files (on any filename attribute)filename matches "\\.log$"# Error messages (on message attribute or body)message matches ".*(error|exception|failed).*"body matches ".*(error|exception|failed).*"# UUID format (on any UUID field)uuid matches "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}$"
Tips:
- Use
^and$to match start/end of field - Escape special characters:
\.,\(,\) - Test patterns at regex101.com
Parse
The PARSE stage supports multiple parsing methods:
-
JSONP
-
Parameters:
- from: Source field to parse. Default is the log body
- fields: Optional comma-separated list of fields to extract
-
Example: json from body fields DetectorName as credential_type
-
-
REGEXP
-
Parameters:
- from: Source field to apply regex on. Default is the log body
- pattern: Regular expression pattern with one or more capture groups
- into: Target field names, one for each capture group in the regex pattern
-
Examples:
regexp from finding ((?i)client[_-]?id[=\s\'\"]+([\'\"]*(\w|<|>|;|${})+)) into client_idregexp from finding ((?i)[^A-Za-z0-9]([A-Za-z0-9]{40}?)[^A-Za-z0-9]) into liveapikey
-
Transform
The TRANSFORM stage provides several data transformation methods:
-
splitByString
-
Parameters:
- from: Source field
- on: Delimiter character
- select part: Part number to select
- as: Output field name
-
Example:
splitByString from link on # select part 1 as real_link
-
-
replaceRegex
-
Parameters:
- from: Source field
- pattern: Regex pattern to match
- with: Replacement string
- as: Output field name
-
Example:
replaceRegex from user_email /[<>]/, with - as user_email
-
-
concat
-
Parameters:
- from: First field to concatenate
- Additional fields/literals to concatenate
- as: Output field name
-
Example:
concat real_link, '#', line_number as link
-
-
if
-
Parameters:
- Condition:
isEqual,!isEqual,isEmpty,!isEmpty - then: Value if condition is true
- else: Value if condition is false
- as: Output field name
- Condition:
-
Example:
if !isEmpty client_id then client_id else finding as finding
-
Aggregate
The AGGREGATE stage supports various statistical computations with optional grouping:
-
Zero or One Argument Functions:
- count
- Usage without argument: count as total_count
- Usage with argument: count field_name as field_count
- count
-
Single Argument Functions:
-
sum: Calculate sum of values
-
min: Find minimum value
-
max: Find maximum value
-
avg: Calculate average
-
median: Find median value
-
stddev: Calculate sample standard deviation
-
stddev_pop: Calculate population standard deviation
-
variance: Calculate sample variance
-
variance_pop: Calculate population variance
-
Usage Syntax: function_name field as result_name
-
-
Two Argument Functions:
-
quantile: Calculate approximate quantile. Quantile value is between 0 to 1.
-
quantile_exact: Calculate exact quantile. Quantile value is between 0 to 1.
-
Usage: quantile(0.99, bytes_transferred as bytes_p99)
-
Additional Features:
- groupby: Group results by specified fields. Similar to a SQL groupby
- Example: groupby user_agent as user_agent, service as service
Note:
Each aggregation stage limits available fields to those defined in the as clause of the previous stage.
Field Handling
Field Aliasing
Use the as keyword to create aliases for fields:
SourceName as event_idRaw as findingNested Fields
When filtering or selecting fields in the Query Builder, you can access nested JSON data using dot notation and array indexing. These field paths work in filter conditions, column selection, and parse stages.
Dot Notation (Objects)
Use dots to navigate through nested objects:
SourceMetadata.Data.Github.emailSourceMetadata.Data.Github.repositoryrequest.headers.UserAgentArray Indexing
Use bracket notation with zero-based indices to access array elements:
context[0]servers[2]events[0]Combined Access (Arrays + Objects)
Combine dot notation and array indexing for deeply nested structures:
context[0].request.methodcontext[0].request.headers.UserAgentevents[0].data.user.emailSourceMetadata.Data.files[0].pathExample: To filter logs where the first context entry has an HTTP POST request:
- Field:
context[0].request.method - Operator:
= - Value:
POST
The Query Builder automatically creates a JSONP parse stage to extract the nested array value before applying the filter.
Keyboard Shortcuts
The Query Builder supports several keyboard shortcuts for efficient query construction:
| Shortcut | Description |
|---|---|
Shift + Enter | Add a new stage |
Shift + Delete | Remove the current stage |
Tab | Navigate to next field |
⌘/Ctrl + Z | Undo |
⌘/Ctrl + Shift + Z (Mac) / Ctrl + Y (Windows) | Redo |
For a complete list of shortcuts including navigation and toggle controls, see the Keyboard Shortcuts reference.
Query Construction Best Practices
-
Operation Order
- Start with FILTER operations to reduce data volume
- Follow with PARSE operations to extract needed fields
- Apply TRANSFORM operations last for final data shaping
- Apply AGGREGATES operations last for final data shaping
- Applying FILTER after TRANSFORM and AGGREGATE, is a common pattern
-
Field Naming
- Use descriptive names for output fields
- Maintain consistent naming conventions
- Avoid special characters in field names
-
Error Prevention
- Use !isBlank checks before transformations
- Validate regex patterns before using them (You can use something like https://regex101.com/)
- Check field existence before accessing nested data
-
Performance Optimization
- Keep time ranges reasonable
- Use = on Service for much faster query executions
- Filter early in the query chain
- Prefer querying on pre-extracted attributes rather than operations on Body. Use the control plane to extract from body during ingestion.
Troubleshooting
Please get in touch with us on Discord or Email if you have any questions.