

The importance of structured communication in the world of SRE
How you communicate helps build your 9s. In the world of Site Reliability Engineering, this is crucial. How do you do it?
Saurabh Hirani
Best Practices Using and Writing Prometheus Exporters
This article will go over what Prometheus exporters are, how to properly find and utilize prebuilt exporters, and tips, examples, and considerations when building your own exporters.
Last9
The difference between DevOps, SRE, and Platform Engineering
In reliability engineering, three concepts keep getting talked about - DevOps, SRE and Platform Engineering. How do they differ?
Prathamesh Sonpatki

Thanos vs Cortex
In-depth comparison of Cortex and Thanos, what specifically they help teams do, challenges in implementing both, and how to think about what’s right for your team.
Sahil Khan

Introduction to DORA Metrics
DORA metrics, what they are, why they are important, and best practices for measuring them.
Prathamesh Sonpatki
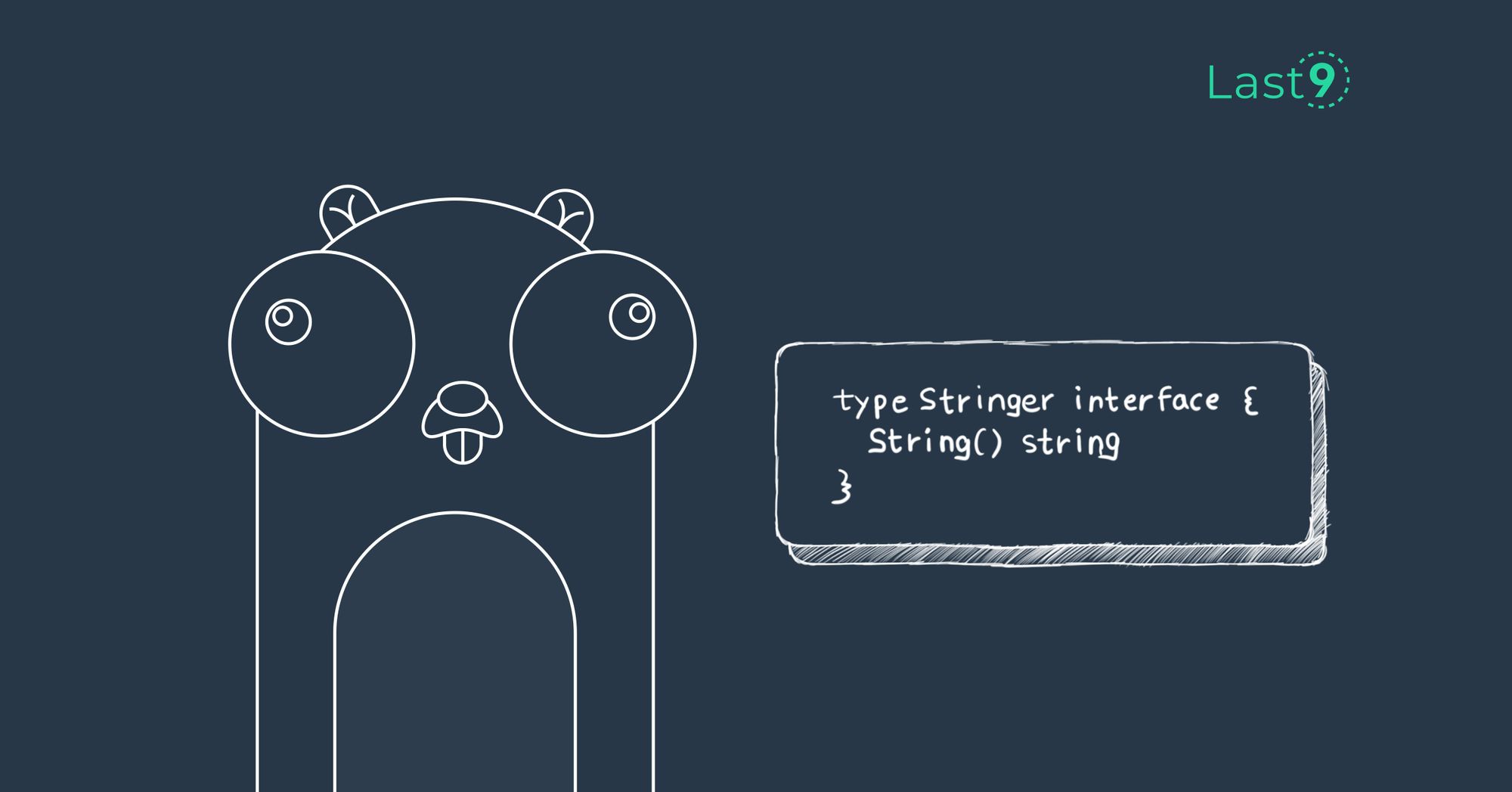
Golang's Stringer tool
Learn about how to use, extend and auto-generate Stringer tool of Golang
Arjun Mahishi
How to improve Prometheus remote write performance at scale
Deep dive into how to improve the performance of Prometheus Remote Write at Scale based on real-life experiences
Saurabh Hirani
Prometheus vs InfluxDB: Side-by-Side Comparison
What are the differences between Prometheus and InfluxDB - use cases, challenges, advantages and how you should go about choosing the right tsdb
Anjali Udasi
India vs Pakistan: SRE and the Shannon Limit
How does one ‘detect change’ in a complex infrastructure, so you don’t lose out on critical revenues — A short SRE story
Satyajeet Jadhav