

Companies that build cloud-native and distributed applications often want their systems to scale on demand. For instance, there is a need to ensure monitoring and alerting with Prometheus remains scalable and reliable to enable the collection and storage of all application data, as the number of VMs, microservices, and other integral components increases.
Luckily, there are multiple ways to build a scalable Prometheus backend solution that can keep up with the growth of its monitoring targets. Cortex and Thanos are two popular tools for scaling Prometheus.
Cortex is a horizontally scalable, highly available, and multitenant long-term storage tool that is built on top of Prometheus. Cortex offers a more powerful query language, infinite data retention capabilities, a rich HTTP API set for exposing services, configurable alerts depending on the metrics, and a lot more.
Built by Improbable, Thanos is an open source Prometheus extension that allows users to create highly available metric systems with long-term storage capabilities and unlimited retention of historical metrics. Thanos enables the storage of petabytes of data in a reliable and cost-efficient way while maintaining responsive query times for the same data. Thanos uses a single query API to easily access metrics from different Prometheus servers.
This article will present an in-depth comparison of Cortex and Thanos, the challenges and trade-offs in implementing both, and how to think about what’s right for your team while trying to build a robust monitoring system.
Why Do You Need to Scale Prometheus?
Scalability issues are minimal when Prometheus is used to monitor small or simple deployments. However, in distributed applications, the lack of visibility and the need for unified data add a layer of complexity and can lead to significant challenges when Prometheus is poorly scaled. Due to the large number of available metrics, which can use more than 100 GB of RAM, appropriate scaling of Prometheus is needed for visibility into distributed applications and their runtime environments, and to identify incidents and anomalies.
Key Differences between Cortex and Thanos
This section compares Cortex and Thanos under the following categories:
- Design
- Rollout
- Storage
- Features
Design
Cortex presents an out-of-the-box solution for highly demanding monitoring and observability scenarios. Designed for scalability (several microservices that can be scaled horizontally), Cortex can run across several machines in a cluster, overcoming the limitations of memory and storage in a single-machine setup. As a result, metrics from several Prometheus servers can be sent to a single Cortex cluster to achieve a single global view of data. On the other hand, Thanos components (metric sources, stores, and queriers) can be composed into a highly available Prometheus setup that supports long-term storage capabilities, operational simplicity, and metrics reliability.
Rollout
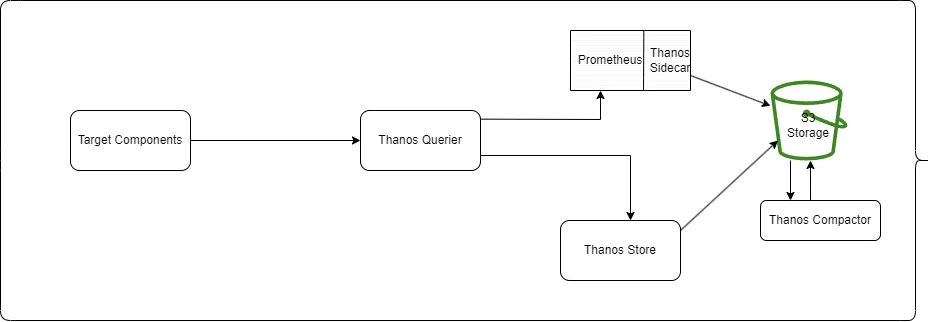
Thanos is built as a set of components—sidecar, Store Gateway, compactor, receiver, ruler, and query gateway—with each performing a specific role. These components can be deployed independently, thus providing a running subset of Thanos features ready for use and making complex gradual rollouts possible. Using the sidecar approach, Thanos can be rolled out incrementally alongside a Prometheus deployment. This approach also allows you to integrate Thanos with running Prometheus servers and have its data uploaded to your object storage of choice.
Cortex, however, can be rolled out as a single binary or as multiple independent microservices. The single-binary approach is simple and preferred for users who want to test Cortex. The microservices approach is intended for production usage, as it allows you to seamlessly scale services for storing and querying metrics as well as for isolating failures.
Storage
Thanos stores metrics it collects in configurable object storage clients, providing fast query latencies and cost efficiency when storing historical data. Thanos supports configuring object storage clients against its objstore.Bucket interface. Some of the currently supported object storage clients include Google Cloud Storage, Amazon S3, Azure Storage Account, and OpenStack Swift.
Cortex, on the other hand, uses block storage based on Prometheus TSDB to store and query its time series data. It can also be configured to use local storage, external Memcached, and Redis. Cortex also supports NoSQL.
Features
The features supported by the two tools are compared in the following sections.
Global Querying View across All Connected Prometheus Servers
Even in federated clusters, the two tools have different approaches when it comes to achieving a global querying view across all connected Prometheus servers. With Cortex, you’re required to manage a separate Cortex cluster and storage backend on top of your Prometheus deployment. Thanos, however, can rely on your existing deployment.
Thanos reuses your existing Prometheus deployment servers to achieve global querying. The sidecar component can fetch series from Prometheus through the StoreAPI, an integration point (generic gRPC API) that allows Thanos to fetch custom metrics from Querier. Querier performs an aggregate of multiple metric backends under a single Prometheus Query endpoint, evaluates the queries, and presents the result of all connected servers.
Conversely, Cortex follows a push-based model, wherein the servers use Prometheus’s built-in remote write capability to push data to a central, scalable Cortex cluster. The central Cortex cluster stores all the data, and it’s possible to seamlessly run globally aggregate queries from there.
Deduplication and Merging of Metrics Collected from Prometheus HA Pairs
Prometheus was built to run as a single process, which introduces gaps in metric monitoring whenever a runtime environment crashes or needs updates, forcing Prometheus to restart.
Therefore, Prometheus is limited in how it solves the gaps or even merges data from multiple HA pairs. A workaround for this involves using Thanos Querier to read from multiple replicas and aggregate the data into a single result. Thanos Querier can pull data from multiple storage points such as object storage, another querier, or even non-Prometheus systems.
Cortex uses a different approach. With the push-based model, replicas will push samples to the central Cortex cluster, where the incoming streams are deduplicated into a single copy.
Suppose you have two teams, T1 and T2, each running their own Prometheus instance and monitoring different services through HA pairs (T1.a and T1.b, T2.a and T2.b). Using Cortex, you can ingest only from one part of each pair.
You do this by electing a leader replica for each Prometheus cluster. As long as there is a leader, Cortex will drop samples pushed by the other member in the pair. For example, in the T1 pair, when T1.a is the elected leader, metrics sent by T1.b will be dropped, so only samples from a single replica are accepted.
Seamless Integration with Existing Prometheus Setups
Thanos is largely based on Prometheus. Thanos deployments use more Prometheus features in a seamless integration, making Prometheus an integral foundation for collecting metrics and alerting when using Thanos for scaling. Thanos bases itself on vanilla Prometheus (v2.2.1+), and there are plans to support all Prometheus versions as they are rolled out in the future.
As you’ve seen in the above sections, Thanos integrates with existing Prometheus setups through a sidecar process. The purpose of the sidecar is to have Prometheus data sent to a configured object storage bucket.
Query Optimization
Thanos downsamples historical data to significantly improve the speed of queries involving data with extended time intervals like years or months.
Cortex uses several optimization techniques to improve its query performance. Some of the techniques include using batch iterators for merging results, caching indexes, HTTP response compression, and JSON marshaling and unmarshaling. You can learn more about query optimization in Cortex here.
Data Format
Thanos supports reading and writing data as Prometheus TSDB blocks. It uses a time series database format and can send Prometheus TSDB blocks to supported object stores. A separate component, Thanos Store Gateway, is then used to perform queries against the blocks in object storage.
Cortex is also currently migrating individual Prometheus chunks to object storage to eliminate the use of NoSQL databases, which introduced operational complexities and cost factors while scaling Prometheus.
In another blog, we are comparing all the popular time series databases. Go check it out.
Conclusion
With the shift toward cloud-native practices, application backends are scaling rapidly, with an associated increasing need for monitoring systems to scale to match the new application requirements. This article presented an in-depth comparison of two popular tools for scaling Prometheus into a more robust monitoring tool, Cortex and Thanos. You’ve seen how the two weigh up in terms of design, scaling, storage, and other features.
Both are strong tools and easy to set up. However, if you’re building a resilient monitoring stack, you’ll need to have just one tool running. In most cases, where long-term health (adoption and community support), disaster recovery, long-term archiving, security, scalability, and high availability are all considered, Thanos would be more suitable than Cortex.
Alternatively, you can leverage Last9, a great platform that automates how you monitor your systems without the hassle of instrumentation. Having Last9 as part of your monitoring stack will provide you with visibility into any application, system, or platform, regardless of its size and architecture. This tool comes in handy to present all service and infrastructure metrics in a single pane of glass, detailing relationships, dependencies, and more, giving engineers more time to focus on building reliable features and products.
Many thanks to Elly Obare for contributing to this article.

