

I never paid as much attention to logs as my first-day on-call in my first experience as a DevOps Engineer. In the beginning, our logs were quite messy and underutilized. When you deal with support in a production application, you learn how valuable logs are. Supporting a production application can be like a detective game, where the clues are the millions of records from all the systems under your watch, but how do you find the piece of information you need to solve the mystery? How do you find a needle in a haystack?
Thankfully, things don’t have to be so complicated. In fact, with a bit of work, you can use logs to build a good understanding of your system’s state and quickly pinpoint the logs of a faulty system. Of course, all this comes with some upfront work in building a sound log management system and a working knowledge of analytics.
In this article, you will get an overview of what you need to know to get the most out of your logs with log analysis — giving you the peace of mind and confidence to rest, knowing that your systems will alert you if and when something goes wrong.
What is log analysis and how does it benefit you?
Logs are the finest and most detailed pieces of information provided by an application as it is executed. They provide a record or history of all events that have happened in the life cycle of an application or software.
Why do we stockpile that information in the first place?
Logs exist to meet a developer’s desire to see what is happening in real-time in a program with our own human eyes. By extension, we then want the ability to move back in time through those records to better understand how the application has performed. The issue is that the volume of logs grows exponentially with the number of users and applications, making it hard to interpret data and get the information we need.
This is where log analysis comes into play. You need a recipe to get the relevant information out of the hundreds or thousands of Gigabytes of log data. Ideally, you want a system to ask simple questions and get comprehensive answers based on the log messages. These questions might be something like this:
- What was the state of my system at X time?
- What actions have been performed between Xh and Yh?
- Did the error occur between Xt and Yt?
- Who accessed that specific information, and at what time?
Getting Log Management right!
Being able to successfully analyze your logs is the end goal. To get to that point, you need to successfully implement log management practices. Here are some practical stages of log management to get you started with best practices:
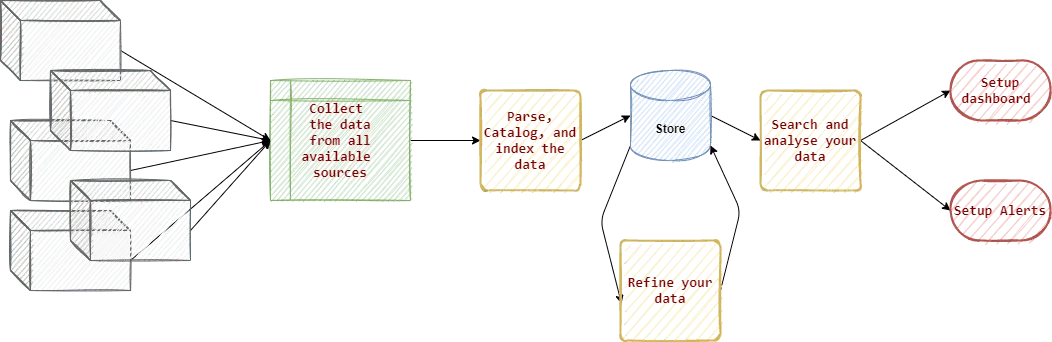
Collect Data from All Available Sources
Logs are commonly written into log files, which are stored on the host machine. It’s most common to install agents (provided by your log management solution) in your infrastructure to read those log files and send them to a centralized log management system.
Ageless setups using the Syslog protocol, for instance, are becoming more and more popular given that they allow you to be solution-agnostic. Syslog is designed for sending system logs and event messages and is supported out-of-the-box by most Unix-based systems.
Catalog and Index the Data
Logs shipped to your centralized log system are cataloged and indexed. The engine will parse those logs and try to make sense of them. The information collected is then stored in different datasets, and a search index is created to make future searches more efficient.
The parsing and indexation process can vary widely from one solution to another; however, adopting a standard log format helps to guarantee that logs are immediately comprehensible by any log management solution.
Search and Analyze Your Data
Once the logs have been indexed in your system, it’s time to put them into use, but first, you need to get to know the data.
Logs are typically segregated into several types, which are more or less consistent and standard across applications and infrastructures. Each type of log has a specific function and lets you answer a set of related questions:
- Application logs (logs provided by applications):
These logs are added by your team inside the portion of code you maintain. They are, in my opinion, the most important ones, as you have control over them. You can see them as an opportunity to leave clues, so you can more easily debug problems in your application - Server logs (provide a record of operations performed by the server):
Typically, this type of log does not collect any application or user-specific information. With these logs, you are primarily interested in error messages - System logs (provide a record of OS events):
This type of log is used to understand what happened at the lowest level of the system (hardware or software) - Access logs (an exhaustive list of all requests performed by a user or a system to access a file or a resource)
This type of log is mainly used for security forensics but can also quantify traffic - Change / Deployment logs (a record of the modifications that have occurred)
This log type is essential in identifying root causes such as software updates or application deployment.
An excellent first step here is to use the search engine to see if you can answer some basic monitoring questions:
- What is the number of users per hour on my website? (web traffic)
- What is the latency for login on my application? (performance metrics)
- Have any users tried to access many different resources in a short period of time? (security audit)
If you can’t answer those questions, you will need to improve the logging in your applications. It’s important that developers make a conscious effort to provide good logs.
Sometimes, analyzing logs requires you to adjust to the log level. Logs are categorized by level based on their degree of detail and criticality.
TRACE > DEBUG > INFO > WARN > ERROR > FATAL
(TRACE being the most detailed and FATAL the most critical)
By default, the application only provides INFO-level logs, as TRACE and DEBUG would generate too much data for you to process. As a result, it’s best to only use TRACE and DEBUG for the specific applications that you need to troubleshoot.
Refine Your Data
At this point, it is wise to create data pipelines to refine your datasets. Indeed, some operations can consume a lot of resources from your log management cluster and make the system slow. For instance, if you want to see the error rate for the past month, this may otherwise require your system to scan all of the logs ingested for that period of time.
Thus, most systems allow you to create an ingest pipeline to tally the metric you need at the time each data point was ingested. This makes your metric of interest much more efficient to gather. You could even keep relevant metrics for several years, as tallies occupy very little memory compared to the whole set of logs.
Set Up Alerts and Dashboards on Metrics of Interest
Once you know your data well, you can start to create dashboards and alerts.
Start by setting up a dashboard, as they are an easy way to get familiar with your data. They are also the best way to share information with your team and management level. Dashboards should mainly focus on historical data (time charts), or important thresholds (gauge charts), as they give you a glance at the state of your system.
Dashboards are not sufficient on their own, though, because you can’t just sit around and wait, hoping to notice when a problem occurs. For that, you need alerts.
When designing alerts, you have to be smart because they can very quickly exhaust your team, and you run the risk of not paying enough attention to them if they occur too often. This phenomenon is known as alert fatigue.
The most successful approach I have experienced for log analysis and alert management is our very favorite - Service Level Objectives.
With SLOs, you alleviate the problem with a budget-based approach toward errors. What frequency level of errors is acceptable? Your team determines the answer to this. As long as you haven’t consumed your error budget, your team won’t be interrupted by unnecessary metric alerts.
Driving Continuous Improvement with Log Analysis
I would argue that logs should not be stockpiled without reason. More logs do not necessarily equal better log analysis. On the contrary, too many logs lead to heavier infrastructure to manage, as well as financial waste due to stored data you never use.
Instead, it’s important to prioritize continually improving your log analysis processes. Here are some lessons I’ve learned in my experience with log analysis as a DevOps engineer:
- First and foremost, your entire team should adopt the same log standards
All developers should be sensitive to the log levels, and you should have a mechanism to adjust the log level on demand. That way, dashboards, and alerts can be easily shared and reused across the organization. Sharing problems and common issues stimulates discussion and collaboration in a DevOps environment. - Second, new team members and junior resources gain a lot of experience by spending time in the logs trying to identify problems.
By doing so, they often challenge the system’s understanding and get to screen parts of the code they may not have worked on. Whenever you have the opportunity, be sure to involve them in the log analysis. - Last, challenge your team to create a zero error/exception system.
It’s common in coding for errors to be thrown when something is wrong while no action is taken to fix the problem. Instead, create an alert that is triggered when an error is logged. If an error occurs, analyze it and think about ways to avoid that alert in the future. For instance, ask your team: Do we need a retry mechanism? Do we need to send an email or SMS to customer service?
Final Thoughts on Log Analysis
Log analysis is the core problem-resolution tool in software operations. Without those precious pieces of information, there would be little chance to solve any problem you are facing, especially in large distributed systems.
While the perspective of log analysis is very promising, there are a lot of prerequisites. You first need to set up a log management system, but thankfully these are included in most modern monitoring platforms nowadays.
Once all logs are processed and indexed in a centralized place, it’s time for you to get started with log analysis by creating a dashboard and alerts to industrialize the use of logs. I highly recommend centering your alerts around the SLI/SLO approach to avoid burning out your team with alert fatigue.
Too many similar sounding acronyms? Here is a guide to Service Level Indicators and Setting Service Level Objectives
Finally, it’s highly beneficial to view log analysis as a way to stimulate continuous improvement. You can push your team to the next step by leveling up junior resources and finding ways to make the system more resilient with the team’s incentive to not want to be perpetually consumed with fighting fires.
(A big thank you to Alexandre Couëdelo for his contribution to this article)

