
This is a mini guide to the Service Level Objective(SLO) process that SREs and DevOps teams can use as a rule of thumb. This guide not necessarily automates the SLO process but gives a direction to use SLOs effectively.
The process essentially involves three steps.
- Identify the level of the Service.
- Identify the correct type of the SLO
- Set the SLO Targets
Before diving deep into it, let’s understand a few terminologies in the Site Reliability Engineering and Observability world.
Did you know Service Level Objectives trace back to Sewage management industry in the United States?
SLO Terminologies
Service Level Indicator(SLI)
A Service Level Indicator (SLI) measures the service level provided by a service provider to a customer. It is a quantitative measure that captures critical metrics, such as the percentage of successful or completed requests within 200 milliseconds.
Service Level Objective(SLO)
A Service Level Objective is a codified way to define a goal for service behavior using a Service Level indicator within a compliance target.
Service Level Agreement(SLA)
A Service Level Agreement defines the level of service users expect in terms of customer experience. They also include penalties in case of agreement violation.
Let’s go through the SLO process now.
Identify the level of Service.
Customer-Facing Services
A service running HTTP API / apps/ GRPC workloads where the caller expects an immediate response to the request they submit.
Stateful Services
Services like a database. It is common to confuse a database as not being a service in a microservices environment where multiple services call the same database. Try answering this straightforward question next time you are unable to decide.
My service HAS a database OR my Service CALLS a database.
Asynchronous Services
Any service that does not respond with the request result instead queues it to be processed later. The only response is to acknowledge whether the service successfully accepted the task; the service will process the actual result/available later.
Operational Services
Operational Services are usually internal to an organization and deal with jobs like Reconciliation, Infrastructure bring-up, tear-down, etc. These jobs are typically asynchronous. But with a greater focus on accuracy vs. throughput. The Job may run late, but it must be correct as much as possible.
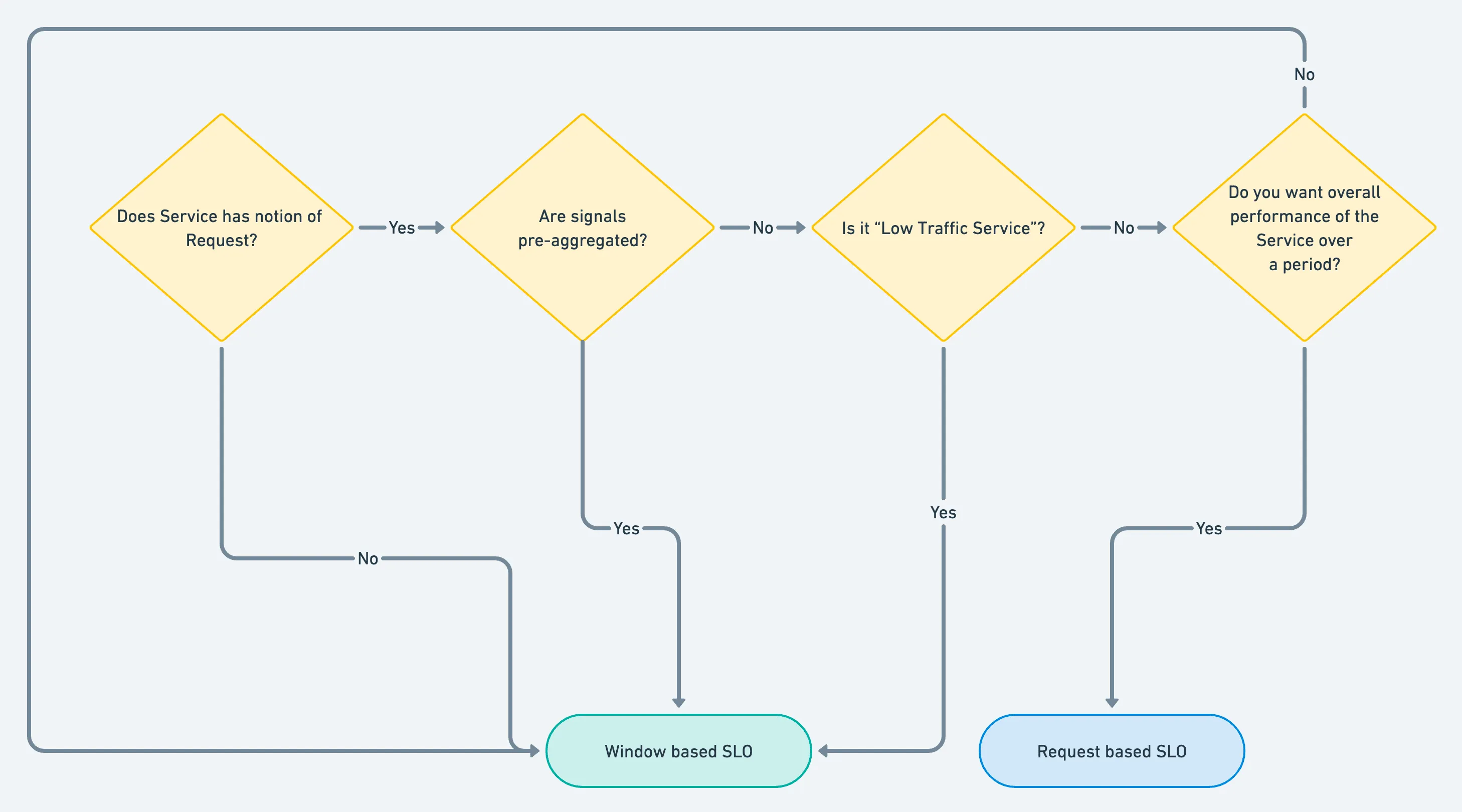
Identify the correct type of the SLO
Request Based SLO
Request-based SLOs perform some aggregation of Good requests vs. The total number of requests.
- First, there is a notion of a Request. A request is a single operation on a component that succeeds or fails in generic terms.
- Secondly, the SLIs have to be not pre-aggregated because Request SLOs perform an aggregation over some time. One can’t use pre-aggregated metrics(e.g. Cloudwatch / Stackdriver, which directly returns P99 latency rather than total requests and latency per request) for Request SLOs.
- Additionally, Request SLOs can be noisy for low-traffic services because they can keep flapping even when a tiny % of requests fail. E.g., if your throughput is 10 rpm in a day, setting a 99% compliance target does not make sense because one request will bring down the compliance to 90%, depleting the error budget.
Window Based SLO
Window-based SLO is a ratio of Good time intervals vs. total time intervals. For some sources, the requests are not available.
For example, in a Kubernetes Cluster, the availability of a Cluster is the percentage of pods allocated vs. pods requested. Sometimes, you may not want to calculate the SLO as the service’s overall performance over time.
E.g., in the case of a payment service, even if only 2% of requests fail in a window of 5 minutes, it is unacceptable because it is a critical service for my business. Even though overall performance has not degraded, that 2% of requests none of the payments were successful. Window-based SLOs are helpful in such cases.
Using the above guidelines, we can create a rough flowchart to decide which type of SLO to choose depending on certain decision points.
Set the SLO Targets
When you start thinking about setting objectives, some questions will arise:
Should I set 99.999% from the start or be conservative?
- Start conservatively. Look at historical numbers and calculate your 9s or dive right in with the lowest 9, such as 90%.
- The baseline of the service or historical data of the customer experience can be helpful in this case.
- Keep your systems running against this objective for some time and see if there is no depletion of the error budget.
- If there are, improve your system’s stability. If there aren’t, move up to the next ladder of service reliability. From 90% go to 95 %, then to 99%, and so on.
- Keep in mind Service Level agreements or SLAs that you may have with customers or third-party upstream services that you depend on. You can’t have a higher compliance target than a third-party service giving you a lower SLA.
What should be the compliance window?
- Generally, this is 2x of your sprint window so that you can measure the performance of the service in a significant enough duration to make an informed decision in the next sprint cycle on whether to focus on new features or maintenance.
- If you are unsure, start with a day and expand to a week. Remember that the longer your window, the longer the effects of a broken / recovered SLO.
How many ms should I set for latency?
- It depends. What kind of user experience are you aiming for? Is your application a payment gateway? Is it a batch processing system where real-time feedback isn’t necessary?
- To start out, measure your P50 and P99 latencies, give yourself some headroom, and set your SLOs against P99 latency. Depending on the stability of your systems, use the same ladder-based approach as shown above and iterate.
Service Level Objectives are not a silver bullet
Let us take a simple scenario.
A user makes a request to a web application hosted on Kubernetes served via a load balancer. The request flow is as follows:

Instead of setting a blind SLO on the load balancer and calling it a day, ask yourself the following questions:
- Where should I set the SLO — ALB, Ambassador, K8s, or all of them? Typically SLOs are best set closest to the user or something that represents the end user’s experience, e.g., in the above example, one might want to set an SLO on the ALB, but if the same ALB is serving multiple backends, it might be a good idea to set the SLO on the next hop — Ambassador.
- If I set a latency SLO, what should be the correct latency value? Look at baseline percentile numbers. Do you want to catch degradations of the P50 customer experience, the P95 customer experience, or a static number?
- Do I have enough metrics I need to construct an SLI expression? AWS Cloudwatch reports latency numbers as pre-calculated P99 values, i.e. if you want to set a request-based SLO with the expression, you can’t do that because the data is pre-aggregated. So you cannot set request-based SLOs; you can only use window-based SLOs.
- Suppose you set an availability SLO on Ambassador with the expression.
availability = 1 - (5xx / throughput). - What happens if the Ambassador pod crashes on K8s and does not emit
5xx/throughputsignal? - Does the expression become
availability = 1 - 0 / 0oravailability = undefined? - For a payment processing application, there might be a lag between the time the transaction was initiated v/s the time it was completed.
- How does
availability = 1 - (5xx / throughput)it work now? - How do I know
5xxthat I got was for a request present in the current throughput or was it a previous retry that failed?
This is not an exhaustive list of questions. Real-world scenarios will be complicated, making setting achievable reliability targets involving multiple stakeholders and critical user journeys tricky.
So does this mean all hope is SLOst?
Of course not! SLOs are a way to gauge your system’s health and customer experience over a time period. But they are not the only way. In the above scenario, one could:
- Set a request-based SLO on the Ambassador.
- Set an uptime window SLO or an alert that checks for no-data situations for signals always ≥ 0, e.g., Ambassador throughput.
- Set relevant alerts to catch pod crashes of the application.
- Set alerts on load balancer 5xx to catch scenarios where ALB had an issue, and the request was not forwarded to the Ambassador backend.
Want to know more about Last9 and how we make using SLOs dead simple? Check out last9.io; we’re building SRE tools to make running systems at scale fun and embarrassingly easy. 🟢


