

Monitoring a Kubernetes cluster isn’t just about keeping an eye on CPU and memory usage. It’s about understanding system health, detecting anomalies before they cause outages, and ensuring applications run smoothly.
With so many tools available, choosing the right one can feel overwhelming. This guide covers the best Kubernetes monitoring tools, their use cases, and key factors to consider.
Why Kubernetes Monitoring Matters
Kubernetes simplifies deploying and managing containerized applications, but it introduces complexity when it comes to observability. A robust monitoring strategy helps with:
- Early issue detection: Identifying performance bottlenecks before they escalate.
- Efficient resource utilization: Preventing over-provisioning or under-utilization.
- Improved troubleshooting: Faster root cause analysis and debugging.
- Compliance and security: Ensuring clusters meet industry regulations.
Key Features to Look for in Kubernetes Monitoring Tools
Not all monitoring tools are created equal. When evaluating options, consider:
- Metrics collection: Support for Prometheus, OpenTelemetry, or other metric-gathering standards.
- Log aggregation: Centralized logging with efficient querying and visualization.
- Tracing: End-to-end request tracking across services.
- Alerting and notifications: Customizable alerts with integrations for Slack, PagerDuty, and other tools.
- Auto-scaling insights: Recommendations for scaling applications based on traffic patterns.
10 Best Kubernetes Monitoring Tools
1. Prometheus
Why use it?
Prometheus is widely regarded as the gold standard for Kubernetes monitoring. It’s open-source, battle-tested, and highly extensible, making it the go-to choice for developers and DevOps teams looking for flexibility.
Key Features:
- Time-series Database: Stores and queries time-series data, optimized for high-dimensional metrics.
- PromQL: A powerful query language for extracting detailed insights from your metrics.
- Native Kubernetes Integration: Automatically discovers services and clusters, making it easy to monitor Kubernetes environments.
- Alerting: Integrated alert manager to notify you about performance issues.
Best For:
- Developers and DevOps teams looking for a robust, open-source solution with customizability.
- Teams with high-volume, high-cardinality environments that need flexible and scalable monitoring.
Limitations:
- Steep learning curve for new users, especially with PromQL.
- Limited out-of-the-box visualizations (this is where Grafana steps in).
2.Grafana
Why use it?
Grafana is a visualization tool that works easily with Prometheus. It’s essential for teams looking to make sense of their data and present it clearly through dashboards.
Key Features:
- Rich Visualizations: Offers various dashboard options like graphs, heatmaps, and more to make metrics understandable.
- Prometheus Integration: Visualize Prometheus metrics effortlessly.
- Alerting: Built-in alerting system to notify teams when thresholds are breached.
- Multi-source Support: Can integrate with various data sources, not just Prometheus (e.g., Elasticsearch, InfluxDB).
Best For:
- Teams requiring clear, real-time visualizations of their metrics.
- Organizations that want a free, customizable way to make sense of their data.
Limitations:
- It’s primarily a visualization tool and doesn’t provide the actual data collection; that’s Prometheus’ job.
- Can become complex when managing large, multi-tenant dashboards.
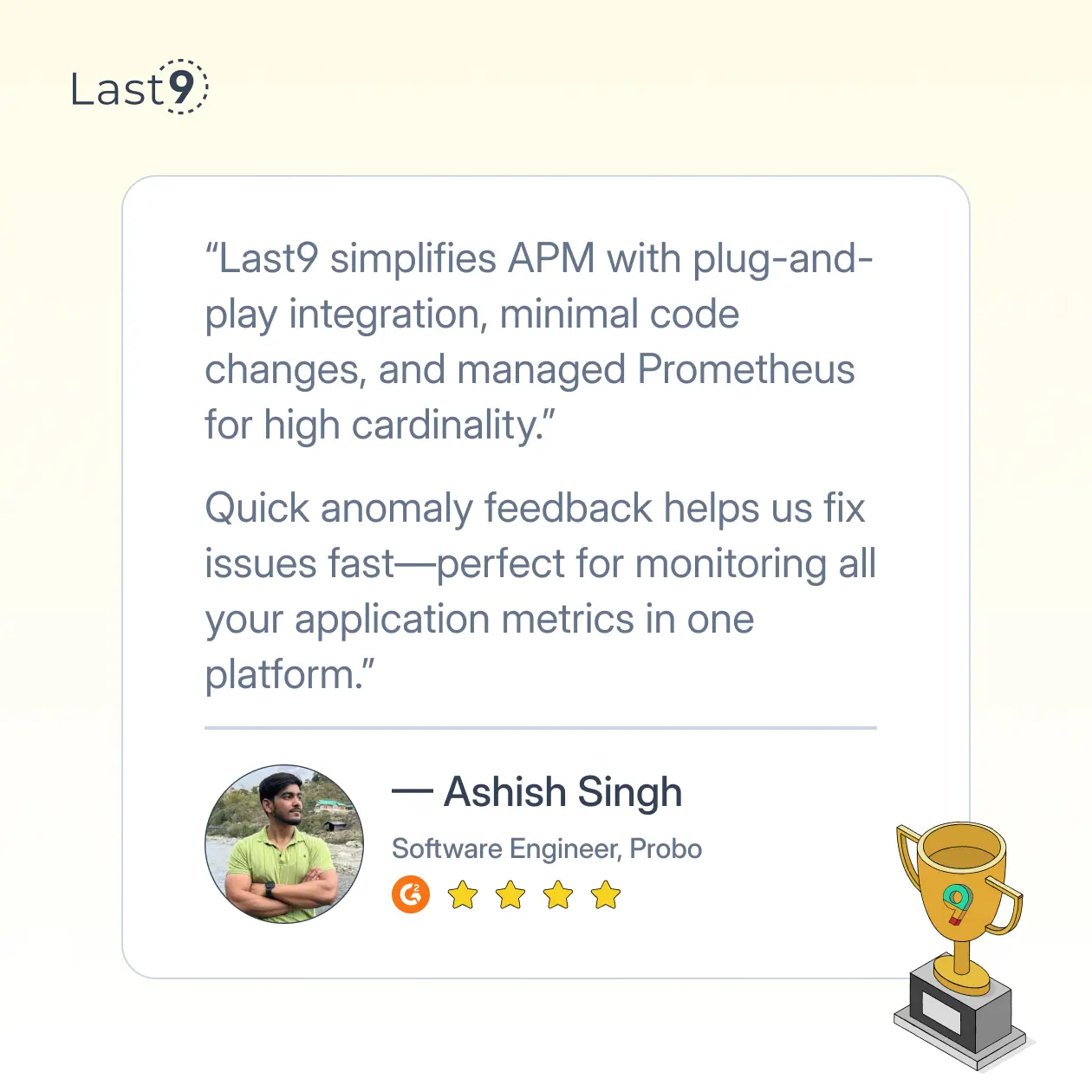
3. Last9
Why use it?
Last9 is a telemetry data platform designed with reliability in mind, making it great for teams focused on SRE practices and struggling with high cardinality.
Key Features:
- High-Cardinality Support: Handles high-cardinality data with ease, essential for monitoring large-scale Kubernetes deployments.
- Anomaly Detection: Detects anomalies and issues proactively to help teams stay ahead of potential problems.
- Customizable Alerting: Set up custom alerts that fit your operational needs.
- Simplified UI: Intuitive interface for easy monitoring, even for less technical users.
Best For:
- Enterprises and large teams need a comprehensive, reliability-focused monitoring solution.
- Organizations implementing Site Reliability Engineering (SRE) practices.
Limitations:
- While feature-rich, the tool may require some initial setup and configuration to get the most out of its features.
4. Datadog
Why use it?
Datadog is a comprehensive monitoring solution that covers the full stack, offering robust integration with Kubernetes and powerful anomaly detection.
Key Features:
- Auto-Detection of Kubernetes: Automatically discovers and monitors services, pods, and workloads.
- Full-Stack Observability: Monitors infrastructure, applications, and logs all in one place.
- AI-Powered Alerts: Detects anomalies with AI-driven alerting to prevent downtime.
- Dashboards and Visualizations: Rich dashboards with pre-built templates for Kubernetes monitoring.
Best For:
- Teams managing large-scale, complex Kubernetes deployments who need centralized monitoring.
- Organizations looking for a full-stack observability solution for their cloud-native environments.
Limitations:
- Can become expensive as your infrastructure grows.
- Some advanced features require a paid plan.
5. New Relic
Why use it?
New Relic provides advanced observability with a strong focus on distributed tracing and Kubernetes monitoring.
Key Features:
- Deep Kubernetes Observability: Offers full visibility into your clusters, nodes, and workloads.
- Distributed Tracing: Built-in tracing for microservices, with no code changes required.
- AI-Powered Anomaly Detection: Uses AI to detect unusual behavior in your clusters and alert the team.
- Full-Stack Monitoring: Combines metrics, logs, and traces to provide comprehensive insights.
Best For:
- Enterprises that need deep observability in complex, multi-cloud environments.
- Teams focused on tracing and resolving microservices issues.
Limitations:
- New Relic can be quite costly, especially at scale.
- Learning curve for fully using its features.
6. ELK Stack (Elasticsearch, Logstash, Kibana)
Why use it?
The ELK Stack is a powerful set of tools for centralized logging and analytics. It’s ideal for teams looking for real-time log monitoring and search capabilities.
Key Features:
- Elasticsearch: A search engine that allows for fast searching of large volumes of log data.
- Logstash: Collects, processes, and stores logs from various sources.
- Kibana: Provides a powerful visualization layer for Elasticsearch, enabling you to create dashboards and perform data analysis.
Best For:
- Teams focused on log monitoring and searching through large volumes of log data.
- Organizations looking for a powerful centralized logging solution.
Limitations:
- Requires substantial resources to run at scale.
- Complex to configure and maintain.
7. Fluentd/Fluent Bit
Why use it?
Fluentd and Fluent Bit are log forwarding and aggregation tools that help you gather logs from different sources and push them to a central location like Elasticsearch or other monitoring platforms.
Key Features:
- Log Aggregation: Collects logs from Kubernetes pods, nodes, and other sources.
- Flexible Configuration: Highly customizable to suit various logging needs.
- Lightweight (Fluent Bit): Fluent Bit is a more lightweight alternative, designed for high-performance log forwarding.
Best For:
- Teams that need a lightweight, high-performance log aggregation solution.
- Organizations looking to collect and forward logs to multiple backends like ELK, Splunk, or others.
Limitations:
- Not a complete monitoring solution on its own (requires integration with other tools like ELK, and Prometheus).
- Complex setup for large-scale environments.
8. Jaeger
Why use it?
Jaeger is an open-source distributed tracing system used to monitor and troubleshoot microservices-based architectures.
Key Features:
- Distributed Tracing: Provides deep insights into the performance of microservices by tracing requests as they travel across services.
- Visualization: Offers rich visualization for understanding service dependencies and bottlenecks.
- Highly Scalable: Can scale to handle large microservice architectures.
Best For:
- Teams focused on microservices and need in-depth tracing for troubleshooting performance issues.
- Organizations that require distributed tracing as part of their observability stack.
Limitations:
- Doesn’t provide metrics and logs, so it’s typically used in conjunction with other tools like Prometheus or ELK.
- Can require substantial resources when scaling for large environments.
9. cAdvisor
Why use it?
cAdvisor (Container Advisor) provides container-level monitoring, especially useful for tracking resource usage like CPU, memory, and disk utilization.
Key Features:
- Container Metrics: Offers in-depth metrics for containers running in Kubernetes.
- Resource Usage Tracking: Tracks CPU, memory, disk, and network usage at the container level.
- Easy to Use: Simple installation with no complex configuration.
Best For:
- Teams that need granular insights into the resource usage of individual containers.
- Developers and DevOps teams focusing on optimizing container performance.
Limitations:
- Doesn’t provide a complete monitoring solution (lacks log and tracing support).
- More suited for resource metrics rather than full-stack observability.
10. kubewatch
Why use it?
Kubewatch is a Kubernetes watch tool that focuses on notifying you about changes in your Kubernetes resources, like deployments and pods.
Key Features:
- Real-time Notifications: Notifies you about changes in Kubernetes resources (e.g., new deployments, pod scaling).
- Slack Integration: Can send notifications directly to Slack channels.
- Simple Setup: Easy to set up and start receiving notifications right away.
Best For:
- Teams that need to stay informed of changes within their Kubernetes clusters.
- Organizations looking for a lightweight notification system for Kubernetes resource changes.
Limitations:
- Doesn’t offer in-depth monitoring (lacks metrics and logging).
- Limited features compared to more comprehensive solutions like Prometheus or Datadog.
Less-Known but Powerful Kubernetes Monitoring Tools
While the big names dominate the space, a few lesser-known tools provide unique advantages. These tools focus on specific aspects of Kubernetes monitoring, offering lightweight yet powerful features.
Kube-state-metrics
Why use it?
Kube-state-metrics is a simple service that listens to the Kubernetes API and generates metrics about the state of Kubernetes objects.
Unlike Prometheus, which collects time-series data, Kube-state-metrics focuses on exposing raw metrics related to Kubernetes objects, such as pod statuses, node conditions, and deployment availability.
Key Features:
- Detailed Kubernetes Object Metrics: Provides detailed visibility into Kubernetes components like pods, nodes, daemon sets, and deployments.
- Lightweight: Runs as a simple service, reducing additional overhead on your cluster.
- Hassle-free Integration with Prometheus: The metrics can be easily scraped by Prometheus and visualized with Grafana.
- Cluster Health Monitoring: Helps teams understand cluster health by monitoring resource availability, pod scheduling failures, and other state-related information.
Best For:
- Teams that need deep insights into Kubernetes state without adding significant resource overhead.
- Organizations already using Prometheus but require additional Kubernetes-specific data.
- DevOps teams troubleshooting Kubernetes deployments and cluster performance issues.
Limitations:
- Doesn’t collect application-level metrics, only Kubernetes object-level data.
- Requires integration with other tools like Prometheus for alerting and visualization.
Vector
Why use it?
Vector is a lightweight, high-performance observability pipeline for collecting, transforming, and routing logs and metrics. It’s optimized for Kubernetes environments, making it an excellent choice for teams looking for a flexible and efficient log aggregation solution.
Key Features:
- High-Performance Log Processing: Handles large volumes of log data with minimal resource usage.
- Built for Kubernetes: Native Kubernetes support with easy deployment as a DaemonSet, sidecar, or aggregator.
- Multiple Data Sources and Sinks: Collects logs from various sources (Docker, journald, Kubernetes logs) and forwards them to multiple destinations like Elasticsearch, Prometheus, and Loki.
- Low Latency & High Efficiency: Optimized for speed, making it faster than traditional log processors like Fluentd.
- Customizable Processing Pipelines: Allows users to transform, filter, and enrich logs before sending them to their final destination.
Best For:
- Teams looking for a lightweight but powerful log aggregation solution.
- Organizations that need fast and efficient log processing with minimal CPU and memory consumption.
- DevOps teams dealing with high-velocity log data in Kubernetes environments.
Limitations:
- Requires some configuration effort to integrate with existing observability stacks.
- Not as feature-rich as Fluentd when it comes to extensive plugins and integrations.
Goldpinger
Why use it?
Goldpinger is a unique Kubernetes tool designed to provide real-time network connectivity insights between Kubernetes nodes and services. It visualizes pod-to-pod connectivity, making it an excellent debugging and troubleshooting tool for network-related issues.
Key Features:
- Real-Time Network Monitoring: Continuously checks and visualizes connectivity between Kubernetes nodes.
- Automatic Discovery: Uses Kubernetes APIs to automatically detect and monitor pods and services.
- Web-Based Dashboard: Provides an easy-to-use UI that displays connectivity issues at a glance.
- Lightweight & Non-Intrusive: Runs as a simple daemonset without introducing significant load.
- REST API for Automation: Exposes a REST API that allows users to integrate connectivity checks into their CI/CD pipelines.
Best For:
- Debugging network issues within Kubernetes clusters.
- Ensuring smooth intra-cluster communication between services.
- Teams implementing service meshes or multi-cluster Kubernetes environments that require reliable networking.
Limitations:
- Primarily focused on networking; does not provide application-level or system-level monitoring.
- Requires visualization tools or additional automation for large-scale cluster insights.
How Kubernetes Dashboard Helps in Cluster Monitoring
The Kubernetes Dashboard is like your cluster’s personal dashboard—easy to use, intuitive, and right at your fingertips. It’s a web-based interface that helps you keep tabs on your Kubernetes clusters without having to dive into command lines all the time.
With the Dashboard, you can quickly see how everything’s doing in your cluster. From pod health to resource usage, it shows you all the key details without the headache of piecing things together. It's perfect for:
- Checking on the health of your nodes and pods
- Keeping track of how much resource each app is using
- Viewing logs and events, so you can easily spot issues
- Managing deployments and services with just a few clicks
The best part? It makes managing your Kubernetes environment feel less like navigating a maze and more like having everything you need in one place—ready for you to troubleshoot or tweak things as needed.
How to Choose the Right Monitoring Tool
The best tool depends on your specific needs:
- For large enterprises: Last9, Datadog, or New Relic provide comprehensive observability.
- For open-source flexibility: Prometheus + Grafana is a powerful combination.
- For deep Kubernetes insights: Kube-state-metrics or Goldpinger add valuable context.
Conclusion
Kubernetes monitoring is essential for maintaining a reliable, high-performing infrastructure.
Whether you choose an open-source solution like Prometheus or an enterprise-grade platform like Last9, the key is to implement a monitoring strategy that aligns with your operational needs.

