

This is the Robocar. In 2019, it set the record for the fastest-ever autonomous car, reaching a top speed of 282km/hour. For context, an F1 car’s top speed has crossed 400km/hour. Given how nascent the self-driving car industry is, this is a remarkable achievement.

There’s a sense of inevitability around self-driving cars. There’s no doubt we need better infrastructure in modern cities. We’ve all wasted countless hours in mind-numbing traffic. Not only is this a colossal waste of time, it’s immensely frustrating. Not to mention all the hazards of poor human judgment while driving cars.
I find autonomous vehicles incredibly fascinating. So much so they’re so entwined with the industry I work in, Site Reliability Engineering (SRE). Think about it.
SRE → Untangles Complex infrastructure
Self-driving cars → Untangles complex infrastructure
And, I could go on.
Self-driving cars ‘observe’ their surroundings and interpret them to navigate from Point A to B. Observation of data leads to action. This is precisely what the world of SRE looks like. Hell, we even refer to this space as, ‘Observability’!
While the world of autonomous vehicles have a set standard of understanding milestones they need to hit to become fully autonomous, SREs don’t have a clear map. I thought it’d be interesting to chart out parallels between the two. You’d be surprised to learn how closely intertwined they are. 😉 Let’s delve deeper into this analogy of self-driving cars and SRE.
Levels — The topology of a complex industry
Comparing the different levels of self-driving cars and SRE.
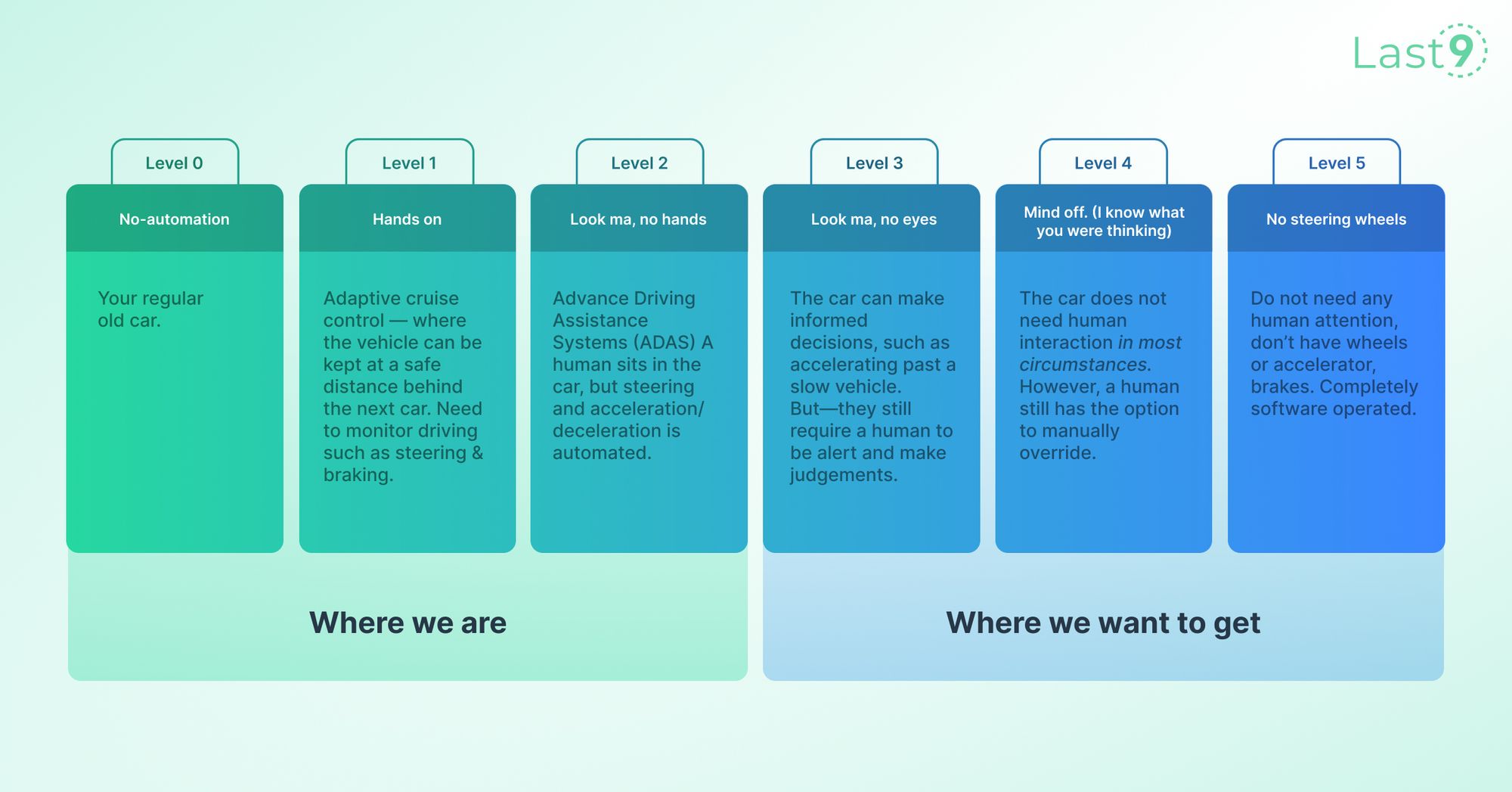
What does this analogy look like for SREs? 👇
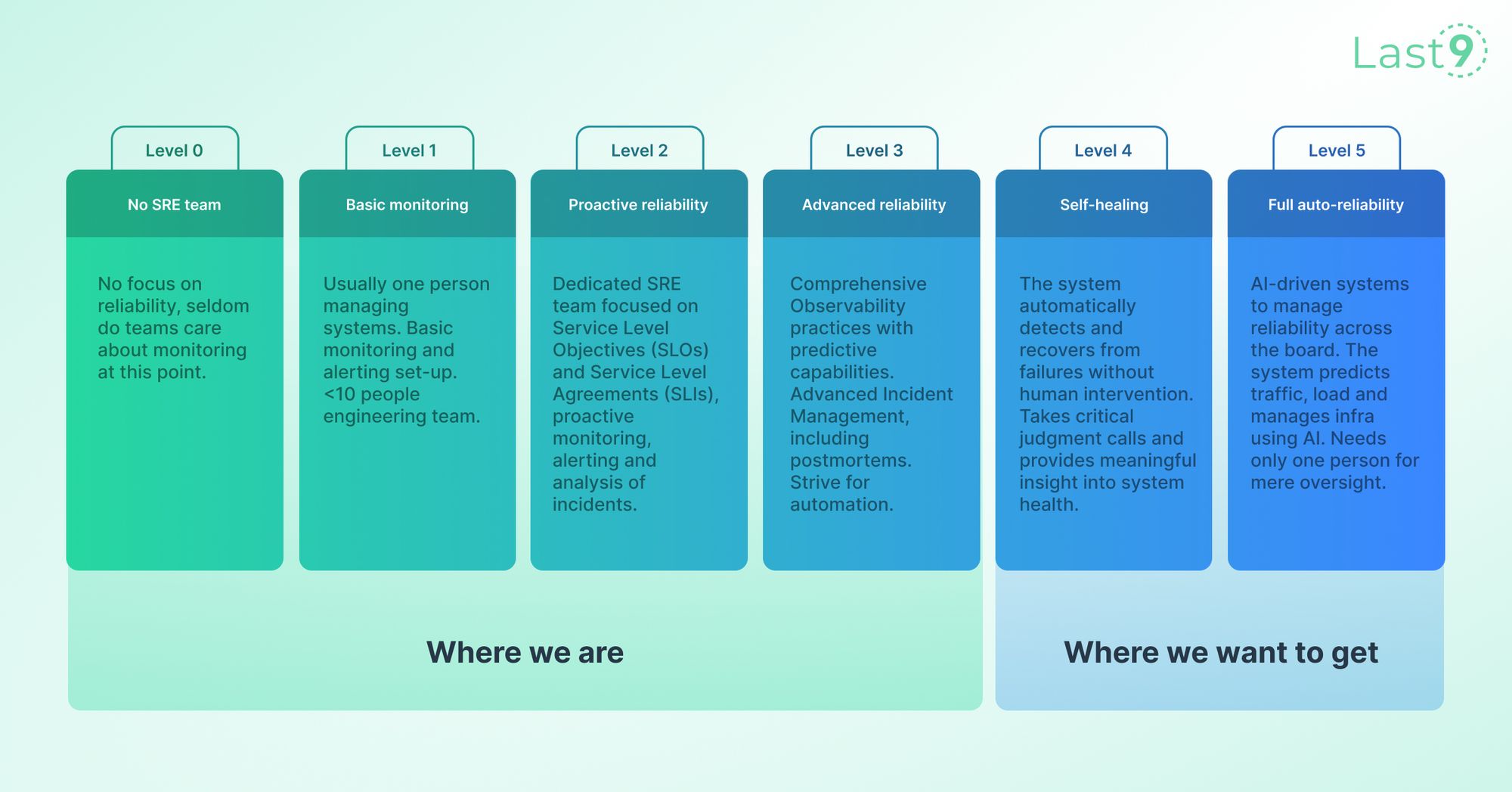
Let’s take some common needs and understand how they’re inter-operable across both these industries:
Monitoring and Alerting Systems:
- Self-driving cars: Sensors and cameras constantly monitor the environment, detecting obstacles, traffic signals, and other vehicles to make appropriate decisions.
- SRE: Monitoring tools and alerting systems to track application performance, system health, and infrastructure to identify potential issues and take corrective action.
Incident Management:
- Self-driving cars: When a potential incident is detected, the self-driving system can take evasive action to prevent an accident, or minimize impact.
- SRE: Incident management processes help SREs identify, respond, and resolve issues efficiently. This minimizes downtime and service disruptions.
Automation:
- Self-driving cars: Automation is at the core of self-driving technology, allowing vehicles to navigate, accelerate, brake, and perform other functions without human intervention.
- SRE: Automation is crucial in SRE. It helps manage deployments, infrastructure, monitoring, and incident response, reducing manual effort. This reduces the potential for human error.
Continuous Improvement:
- Self-driving cars: Machine learning algorithms and continuous data collection help self-driving systems learn from past experiences and improve over time, enhancing safety and performance.
- SRE: Continuous improvement is a key aspect of SRE, with postmortems, root cause analysis, and iterative enhancements aimed at refining processes and systems for better reliability.
💡 For better automation, you need adequate data and patterns to set rules. Continuous Improvement seems like a trivial, non-issue, but a good SRE team puts in enough effort to do ‘pattern recognition’ and work with the Business Intelligence team to improve uptime in an org.
Resilience and Redundancy:
- Self-driving cars: Redundant systems and fail-safes are built into self-driving cars to ensure that a single failure doesn’t result in a catastrophic event.
- SRE: SRE principles emphasize the importance of building resilient systems with redundancy, ensuring that failures can be tolerated and mitigated without causing significant disruption.
Reliability — Chasing 9s
There’s a huge cost to pay for human intervention. Be it self-driving cars or SRE. Both suffer from poor human judgment; both are unpredictable and can be fairly catastrophic. Mapping the topology of your Observability charter helps you gauge where you stand vs. others building different tools.
In the SRE space, the lack of unified standards means there’s enough chaos around best practices and ways to approach Reliability engineering. We’re still in the early days of understanding the deluge of data we’re sitting on and the costs associated with it.
I detest the word ‘Big Data’. But in this industry, orgs are sitting on a tonne of data, and paying for it with engineering overheads, lack of productivity, and ultimately out-of-control costs. The last point is especially pertinent. Infrastructure costs are off the roof, and poor tech instrumentation is only going to get worse as big data gets bigger. Here’s an important post from Nishant calling this out - here.
Achieving better 9s is about doing the simple, boring things and getting them right. The self-driving car industry is a fascinating study of how much they’ve been able to move the needle by mapping out the benchmarks automakers need to hit to take them to the promised land — fully autonomous vehicles. The SRE industry is at Level 3 now, and getting it to Level 4 is going to be the next big frontier to crack. Dare I say, watch this space. 😈
The Last9 promise — We will reduce your TCO by about 50%. Our managed time series
databasedata warehouse, Last9, comes with streaming aggregation, data tiering, and the ability to manage high cardinality. If this sounds interesting, talk to us.
Oh, also, join our Discord community to mingle with like-minded folks.

