

I’ve been meaning to write this for a while now. My parents and friends keep asking me what it is that I do, and I struggle to explain my job. The funny thing is, engineers I know struggle quite a bit too. There are differences in how we interpret so many terms; this whole space is pretty filled with jargon. So... here’s an, Explain It Like I’m 5. (ELI5) — Had to start with what ELI5 is, right? 😉
So, here goes nothing.
Caveat: I’m going to take some liberties and simplify things so I can adhere to ELI5. Use this post as a starting point to do your own deep dives. ✌️
There’s this company called Google. No biggie. Just $1.18 trillion big or so... They came up with this term called SRE (Site Reliability Engineering). That’s the space I operate in. 👋
Think of SRE as a movement, a philosophy, a mindset, a practice, or maybe even a set of principles. It’s a simple thing really. As Google scaled, they wanted an effective way to combat the numerous problems between developers who wrote code, and operators who executed this code. Voila, SRE was born.
Wait, wait, wait. What do you mean by “operators who executed code”? 🤔 Well, you see, building an app where you can stream a Formula 1 race is not as easy as it seems. Multiple teams come together to make this happen. I'm not talking about marketing, finance, product, et al. Even within core engineering, multiple teams have to come together to make this happen.
At the absolute basic, someone writes the code for an app. And ‘Operations’ is responsible for running that code. The duality between Developers and Operations started becoming something of a nightmare as companies grew and there was a lot of code to manage. And I mean A LOT! In comes this movement called DevOps — DeveloperOperations.
WTF is DevOps?
DevOps is a cultural movement emphasizing the need for folks who write code, and Operators who execute the code to work together as one team. By doing this, you could ship products faster, communicate efficiently, unlock productivity, etc…
You see, the separation between folks who wrote code (Software Development) and Operators (think IT teams) eventually reached a bottleneck. This started breaking because of the sheer volume of code and tooling upkeep as teams and products grew. So, the DevOps movement kicked off in 2007.
Fundamentally, DevOps wanted these two folks to work together better and reduce the time to write and execute code. But… (And there’s always a but. 😜) this movement has its own detractors. While theoretically, it makes sense, its practical implications were haphazard.
Think of it like this — developers want to release new features in a product. Operations want to ensure these features work and don’t break a system. They both want the same thing, but because of the fundamental nature of the problems in scale, they’re at loggerheads.
Mind you, DevOps does not have a defined set of principles or a clear manifesto. It’s a rallying cry for a cultural change in approaches to engineering. And these are always messy when it’s interpreted in multiple ways. In comes SRE to the rescue.
WTF is SRE?
The actual, real-world implementation of DevOps practices is Site Reliability Engineering. Remember, the DevOps movement started off in 2007 as a framework. But Google had been running these practices since 2003 in their engineering efforts and coined the term SRE. So, the actual implementations became all the more important.
Site Reliability Engineers took DevOps practices and ‘productized’ them in an organization. The SRE team is now responsible for a system's health and works across the org to ensure end customers don’t have any problems with their products.
Ok, now that you’ve understood some basics, let’s get to the crux of what it is I do.
The Reliability Universe
One has to measure how efficient a piece of software is to make it reliable. We usually assign a percentage score to calculate this. For example, 99% means “two nines.” This means your system was down 1% of the time in a given period. It doesn’t seem like much, right?
What if I told you that a 99% impressive score means my system was down for 3.65 days in a year!! Imagine not being able to access your bank account for 3.65 days, hail a cab, get food delivered, or watch a sporting event for that long. Suddenly, this seems insane, right?
My job is to fight these 9s.
99.999% ("five nines") means 5.26 minutes of failures in a year. And I work to ensure I can ‘add more 9s’ to any software. After all, failure in software engineering is inevitable. Any system will fail. It’s the job of SREs, to mitigate this failure.
Oh, fun tidbit, that’s why the name “Last9” — The company I work for. No one can promise 100%, but fight to climb the ladder of 9s - 99.9999% reliability. Hence Last9. We’re in the business of adding 9s to your reliability.
With me so far? Phew. 😁
Ok, so now, the bare bottoms. In my universe, there are five essential tools to understand this entire space. Again, I’m taking some liberties here, but hey, ELI5, so go easy on me.
The five tools to build ‘Reliable’ systems
- Time Series Database (TSDB)
- Composer (Visualisation Dashboard)
- Change Intelligence
- Promises: SLO/SLAs
- Policies
These five tools sum up the world of SRE in all. This has hundreds of nuances and layers, but let’s begin here. Folks have different terms for all of this too, by the way. 😒
1. Time Series Database (TSDB)
It’s a data-driven world, as every other person likes to remind us. Data is stored in many formats, and one of them is a ‘time series’ format.
Time series means there’s a time stamp, a metric, and a value. So when a machine emits data, it stores data as 11 am, CPU percentage, instance id, and a few other identifiers for the CPU which emitted this — this shows up as a chart.
This is time series data. 👇
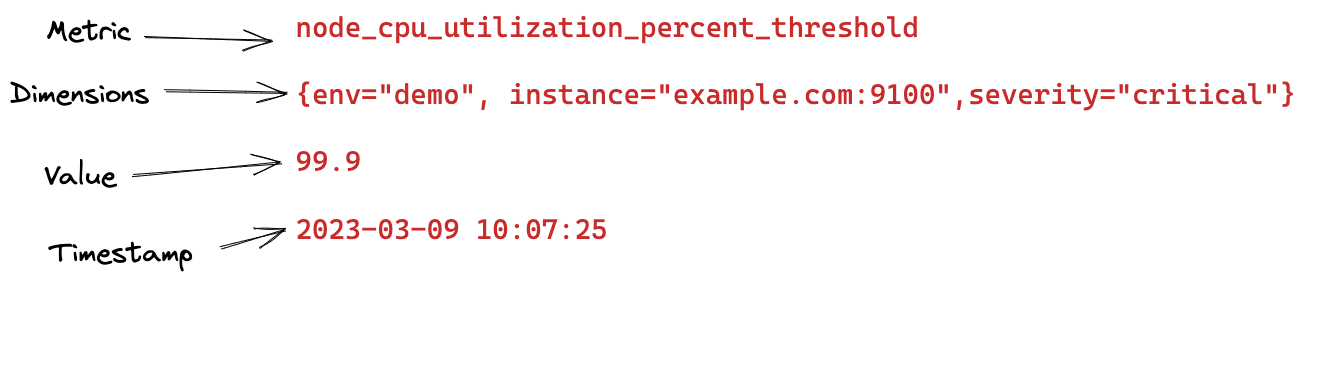
Today, the Open Source world has many TSDBs. The popular ones are Prometheus and Victoria Metrics (VM).
Prometheus is among the most famous of all. VM is the challenger and has made significant inroads into the market. m3db is the more recent upstart and was birthed at Uber.
At Last9, built our own managed TSDB. But to be sure, this is not merely a TSDB. Last9 does more than just data storage. More on this later.
2. Composer
Ok, now that you understand what a TSDB is, the logical progression is understanding how to ‘see’ this data.? One has to ‘visualize’ it and ultimately make meaning out of this data. So you ‘compose’ different charts to make sense of the emitted data. This is the language layer to make meaning out of data.
Enter Grafana.
Grafana is the visualization layer for any database. It can sit on top of any TSDB to visualize the data. Grafana is the most prominent Open Source visualization player in the market. A few other popular ones are not Open Sourced and require an ecosystem buy-in, such as DataDog, and New Relic.
3. Change Intelligence
This is where things start shaping up.
With TSDB, you store data. With Composers, you visualize said data.
But what good is visualizing the data if you can’t make decisions based on what it says? This is where Change Intelligence comes in.
- Change: Reporting an anomaly in the system.
- Intelligence: Telling us something is not right and what this means for others dependent on this system (Think of these as correlations — dominoes that break when one thing goes wrong.)
Creating dashboards is easy. Making meaning out of them? Super hard. (Here's another ELI5 on that)
This is where the magic happens — allowing organizations to reduce costs, improve productivity, and get a holistic view of their system’s health. Think of a typical engineering “war room”. These exercises happen when a system breaks and folks scramble to understand, ‘what just happened?’ These are puzzle-assembling exercises because there’s no way to correlate multiple failures.
4. Promises (SLO/SLAs)
These are promises we commit to customers/clients. For example, My payments system should be up 99.99% of the time yearly. This means I have to have a clear objective on how I will achieve this and how I can measure failures. With each decimal point knocked off, companies lose customers, money, and reputation.
SLA: Service Level Agreement.
An agreement that we will help with 99.99% uptime.
SLO: Service Level Objective.
Creating Objectives internally to help in the 99.99% uptime by having a 99.9999% SLO to achieve the external SLA.
5. Policies
This is unchartered territory. Very few organizations have these advanced tools. Essentially, policies create a set of rules/behaviors from rich data.
For example, the traffic in my application should be load balanced between two load balancers. How can I compare two things and say this should be their stable state? I cannot say this to the system today — I have to keep querying it, but the system cannot speak. But ‘Policies’ are a way to tell the system what I expect as behavior. If the behavior diverges, tell me.
These policies are possible only when you have a strong understanding of all the above tooling and patterns.
Conclusion
This is an ELI5 version of everything Reliability engineering. Ask me tomorrow, and I’ll probably have a different take on what Change Intelligence should ideally mean. 😛
I aimed to keep this simple so folks could understand this complicated, jargon-filled space. There are about 100 nuances I’ve skipped, given how vast this field is. But, as stated, this is a good start to go down your rabbit hole to understand Reliability engineering.
Bouquets and brickbats here — @mohandutt134 ;)
SRE tools

