

When your Python app starts slowing down, maybe queries are taking longer, memory keeps creeping up, or API calls are lagging-basic server metrics won’t tell you why. You need to see what’s happening inside the application itself. That’s the role of Application Performance Monitoring (APM). It gives you a breakdown of database queries, external API calls, memory usage, error rates, and more, so you can connect the dots between code and performance.
In this blog, we’ll look at how to set up Python APM, compare popular tools for different needs, and discuss how to instrument your code without introducing unnecessary overhead.
What Python APM Monitors
Python APM captures application-level telemetry-granular performance data that traditional host monitoring can’t see. Infrastructure metrics like CPU, memory, and disk I/O tell you how the system is behaving overall, but they don’t explain why a specific request slowed down or why a user’s action triggered a spike in resource usage.
APM bridges that gap by breaking performance down into the individual transactions, code paths, and service interactions that make up each request.
Here’s what that typically includes:
- Transaction traces – Detailed, end-to-end records of each request, showing exactly where time is spent across functions, services, and middleware. This helps identify whether delays come from the application logic, external dependencies, or network layers.
- Database performance – Metrics on query execution time, connection pool saturation, lock contention, and slow-running statements, making it easier to pinpoint database bottlenecks.
- External service calls – Latency measurements for API calls, along with timeout and error rates, so you can quickly spot unhealthy upstream or downstream dependencies.
- Error tracking – Collection of exception data, stack traces, and recurring error patterns to help reproduce and resolve issues without relying solely on logs.
- Throughput and response times – Requests per second paired with detailed percentile breakdowns (p50, p95, p99), so you can measure both average performance and outlier impact.
The real value emerges when these metrics are correlated. If your p95 response time jumps at the same moment query execution time increases, you’ve likely found the bottleneck-and can focus directly on the database layer instead of troubleshooting the entire stack.
For a broader look at how APM fits into overall observability, see our Application Performance Monitoring overview.
Step-by-Step Process to Set Up Elastic APM with Python
Elastic APM is often a first choice for teams already using the Elastic Stack. If your logs are in Elasticsearch and you’re visualizing data in Kibana, adding APM closes the loop-you can see application performance metrics, request traces, and logs in one environment. It’s open source, supports multiple runtimes, and gives you control over data retention and indexing strategies.
For Python applications, the agent supports popular frameworks like Django, Flask, and FastAPI with minimal changes. It automatically instruments common operations, captures execution times, and correlates them with infrastructure data.
When paired with Last9, Elastic APM fits into a broader observability strategy. By forwarding traces through the OpenTelemetry Collector, you can:
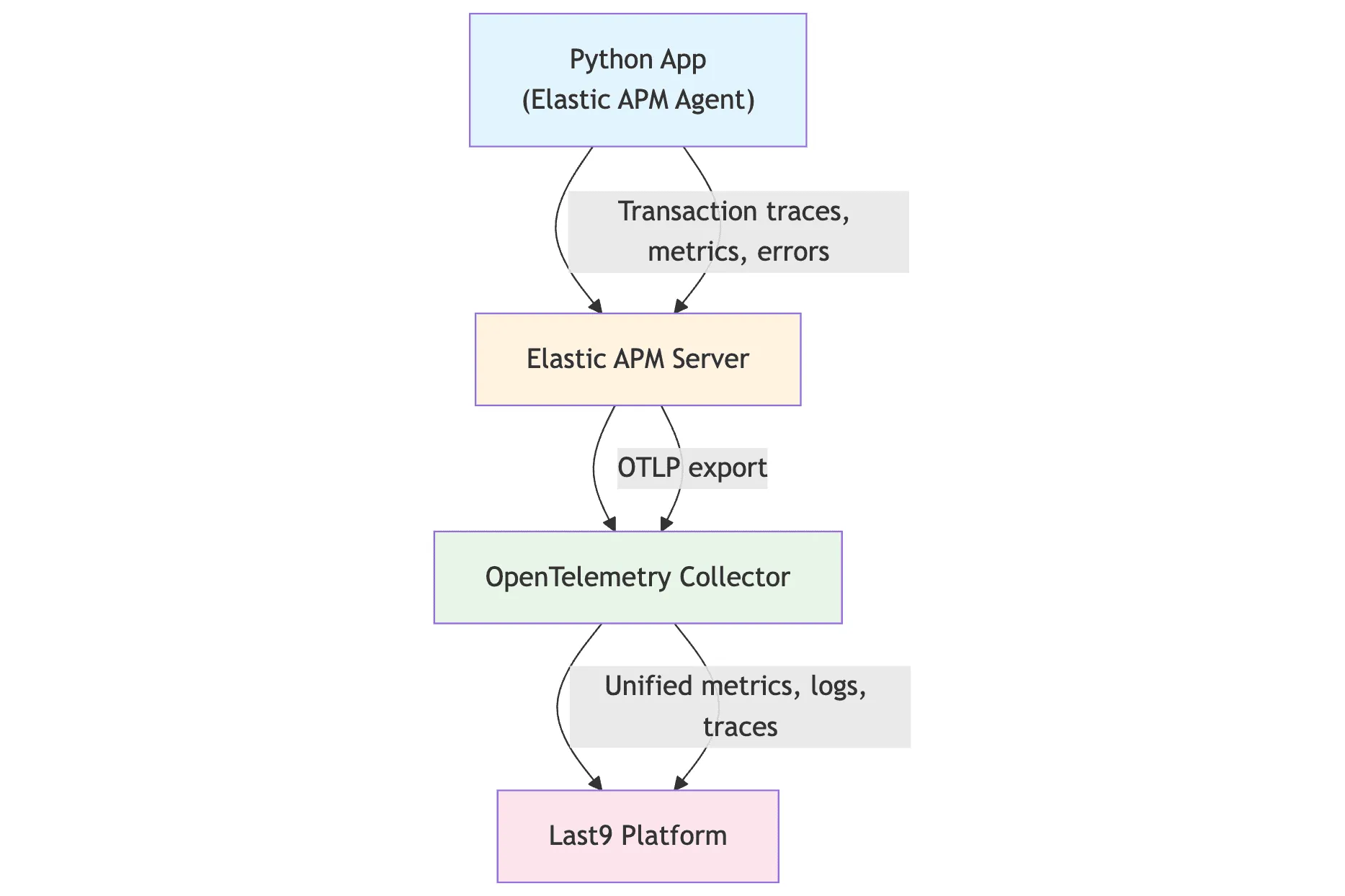
- Correlate latency spikes with slow database queries, infrastructure metrics, or downstream API issues.
- Retain high-cardinality trace data without sampling.
- Query metrics, logs, and traces in one place-reducing context switching during investigations.
1. Install the Python Agent
pip install elastic-apm2. Configure Your Django Application
# settings.pyINSTALLED_APPS = [ 'elasticapm.contrib.django', # other apps]
MIDDLEWARE = [ 'elasticapm.contrib.django.middleware.TracingMiddleware', # other middleware]
ELASTIC_APM = { 'SERVICE_NAME': 'your-python-app', 'SECRET_TOKEN': 'your-secret-token', 'SERVER_URL': 'https://your-apm-server:8200', 'ENVIRONMENT': 'production',}3. Configure Flask Applications
from elasticapm.contrib.flask import ElasticAPMfrom flask import Flask
app = Flask(__name__)app.config['ELASTIC_APM'] = { 'SERVICE_NAME': 'flask-app', 'SECRET_TOKEN': 'your-secret-token', 'SERVER_URL': 'https://your-apm-server:8200',}
apm = ElasticAPM(app)4. Use Environment Variables for Cleaner Deployment
export ELASTIC_APM_SERVICE_NAME=python-apiexport ELASTIC_APM_SERVER_URL=https://apm.yourdomain.com:8200export ELASTIC_APM_SECRET_TOKEN=your_secret_tokenexport ELASTIC_APM_ENVIRONMENT=productionThe agent detects these automatically, keeping your configuration out of the source code and making deployments across staging, QA, and production simpler.
5. Forward Elastic APM Data to Last9
To bring Elastic APM traces into Last9 alongside your Prometheus metrics and logs, configure the OpenTelemetry Collector:
receivers: otlp: protocols: grpc: http:
exporters: last9: api_key: <YOUR_LAST9_API_KEY>
service: pipelines: traces: receivers: [otlp] exporters: [last9]With this in place, Elastic APM traces are available in Last9 for correlation, retention, and cost-efficient analysis, giving you a complete view from code to infrastructure in one platform.
Custom Instrumentation for Better Visibility
Auto-instrumentation covers frameworks and popular libraries, but it won’t always capture the steps that matter most for your application. For workflows with domain-specific logic, background jobs, or performance-critical code paths, adding manual spans ensures you have visibility into exactly where time is spent.
Use a Decorator to Wrap a Function
import elasticapm
@elasticapm.capture_span("user.data.process")def process_user_data(user_id: str): result = expensive_calculation(user_id) return resultThis approach is ideal for frequently used functions where you want timing data and execution context without rewriting the function body. By using a consistent span name, you can group these operations in dashboards and quickly spot anomalies.
Break Down a Workflow with Manual Spans
import elasticapm
def complex_workflow(order_id: str): with elasticapm.capture_span("db.prepare"): prepare_database_connection()
with elasticapm.capture_span("partner.api.fetch"): external_data = fetch_from_api(order_id)
with elasticapm.capture_span("business.rule.apply"): return apply_rules(external_data)Manual spans let you divide a request into multiple measurable steps. Each span shows up separately in the trace view, making it easier to identify which part of the workflow contributes most to total execution time. This is especially useful when a single request spans multiple systems or integrations.
Add Custom Context for Trace Filtering
import elasticapm
@elasticapm.capture_span("user.operation")def handle_user_request(user_id: str, operation_type: str): elasticapm.set_custom_context({ "user.id": user_id, "operation.type": operation_type, "feature.flag": get_feature_flag(user_id), "region": current_region(), }) return do_work(user_id, operation_type)Custom context fields make it possible to filter traces by user ID, operation type, feature flag, or deployment region. This is particularly valuable when investigating incidents that only affect a subset of users or a specific environment.
Preserve Trace Context in Async Code
import elasticapmimport asyncio
@elasticapm.capture_span("notify.prepare")async def send_notifications(batch): async with elasticapm.async_capture_span("render.templates"): rendered = await render(batch)
async with elasticapm.async_capture_span("queue.publish"): await publish_to_queue(rendered)
return len(rendered)When working with asynchronous code, spans must be created using async context managers to maintain trace continuity. This ensures that each awaited call is recorded in sequence, even if operations run concurrently.
Capture Exceptions Within Spans
import elasticapm
def bill_customer(invoice_id: str): try: with elasticapm.capture_span("billing.charge"): charge(invoice_id) except Exception: elasticapm.capture_exception() raiseCapturing exceptions within a span links error details, stack traces, and request context together. This makes it easier to understand not only what failed, but also which part of the request caused the failure.
Add Status Labels to Spans
import elasticapm
def reserve_inventory(sku: str, qty: int): with elasticapm.capture_span("inventory.reserve") as span: ok = try_reserve(sku, qty) span.context = {"labels": {"inventory.result": "ok" if ok else "fail"}} return okLabels such as inventory.result allow you to segment performance data by success or failure. This can highlight patterns, such as retries taking longer than successful requests, without requiring a deep dive into each trace.
For a comparison between open, vendor-neutral instrumentation and legacy APM platforms, check out this OpenTelemetry vs. Traditional APM Tools post.
Top 5 Python APM Tools
Your choice of Python APM solution depends on your current observability stack, how much control you want over infrastructure, and whether you prioritize cost predictability, vendor flexibility, or ecosystem integrations.
Elastic APM
An open-source APM solution that integrates directly with the Elastic Stack. If you already use Elasticsearch for logs and Kibana for dashboards, Elastic APM extends your setup with application traces, transaction timing, and error tracking.
- Strengths: Tight Elastic integration, auto-instrumentation for Django, Flask, and FastAPI, and good out-of-the-box visualizations.
- Considerations: Requires self-hosting and scaling Elasticsearch for large trace volumes, which can become resource-heavy over time.
Last9
A telemetry data platform that helps teams ship fast and triage faster with:
- Unified telemetry platform – Metrics, logs, traces, APM, and RUM in one place.
- AI Control Plane – Manage observability costs in real time, with no post-ingestion billing surprises.
- High-cardinality scalability – 20M+ cardinality per metric without sampling, so you can retain detailed labels and trace context.
- Cost efficiency – Up to 70% lower observability costs compared to incumbent vendors.
- Native integrations – Works seamlessly with OpenTelemetry and Prometheus, making it simple to send Python APM data alongside metrics and logs.
- Proven adoption – Used by Probo, CleverTap, Replit, and more to debug faster and avoid unpredictable monitoring bills.
OpenTelemetry (Framework)
OpenTelemetry (OTel) is not a backend or visualization tool - it’s a vendor-neutral instrumentation framework. It defines APIs, SDKs, and semantic conventions for generating telemetry data.
- Use case: Instrument Python applications once, and send the same data to any backend (Last9, Elastic, Grafana Tempo, Jaeger, etc.) without rewriting your code.
- Flexibility: Lets you avoid vendor lock-in while standardizing telemetry formats across services and languages.
- Integration tip: Pair OTel with a storage and query platform like Last9 to make telemetry data actionable.
Example OTLP exporter configuration in Python:
from opentelemetry import tracefrom opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporterfrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.export import BatchSpanProcessor
trace.set_tracer_provider(TracerProvider())tracer = trace.get_tracer(__name__)
otlp_exporter = OTLPSpanExporter(endpoint="http://localhost:4317")span_processor = BatchSpanProcessor(otlp_exporter)trace.get_tracer_provider().add_span_processor(span_processor)Sentry Performance
Sentry is widely known for error tracking, but its Performance module adds APM-like capabilities for Python applications. It’s particularly useful if you want to monitor slow transactions and errors in the same interface without running a separate APM stack.
- Strengths: Simple setup, unified view of errors and performance, SaaS-based with minimal operational overhead.
- Considerations: Less feature depth than full APM suites for large-scale distributed tracing, but ideal for teams already using Sentry for error monitoring.
AppSignal
A lightweight, developer-friendly APM service that offers performance monitoring, error tracking, and server metrics. It supports Python alongside Ruby, Elixir, and Node.js.
- Strengths: Straightforward installation, clean UI, good for small-to-mid-sized teams looking for quick insights.
- Considerations: Feature set is simpler than enterprise-grade APMs, but more than enough for many mid-scale production workloads.
Deploy Python APM in Docker and Kubernetes
Containerized and orchestrated environments are common in modern Python deployments, and your APM configuration should follow the same patterns. Running the agent in Docker and Kubernetes ensures consistent instrumentation across environments, avoids drift in local vs. production settings, and makes scaling or redeploying the application simpler.
Docker Configuration
A Dockerfile can include your APM environment variables so every container has the same configuration when it starts:
FROM python:3.11-slim
COPY requirements.txt .RUN pip install -r requirements.txt
COPY . /appWORKDIR /app
ENV ELASTIC_APM_SERVICE_NAME=python-apiENV ELASTIC_APM_ENVIRONMENT=production
CMD ["gunicorn", "--bind", "0.0.0.0:8000", "app:app"]Here, the APM service name and environment are set during the image build, ensuring that any container started from this image reports telemetry with consistent metadata. Sensitive settings, such as the APM server URL or secret token, should be passed at runtime rather than baked into the image.
Kubernetes Deployment
In Kubernetes, you can inject the same environment variables via a deployment manifest, using ConfigMap or Secret objects to keep them centralized:
apiVersion: apps/v1kind: Deploymentmetadata: name: python-appspec: replicas: 3 template: spec: containers: - name: app image: your-python-app:latest env: - name: ELASTIC_APM_SERVICE_NAME value: "python-api" - name: ELASTIC_APM_SERVER_URL valueFrom: configMapKeyRef: name: apm-config key: server-urlThis approach keeps APM settings consistent across replicas while allowing you to update them without rebuilding images. Tokens can be stored in Secrets for secure handling, and you can point different clusters to different APM backends without changing application code.
To see how pairing APM traces with logs can speed up your Python troubleshooting, check out APM & Logs for Faster Debugging.
Performance Considerations and Data Storage
Application Performance Monitoring adds extra work to your application at runtime. Each incoming request must be traced, relevant events must be timed and labeled, and the collected telemetry has to be batched, serialized, and sent to the backend. For Python agents, this processing usually results in 1–3% additional CPU usage and a small increase in memory consumption.
The extra CPU comes from three main operations:
- Capturing timestamps and attributes for every span.
- Serializing telemetry data into the backend’s supported format.
- Performing asynchronous exports while keeping request latency low.
While this cost is relatively low, it scales with transaction volume and instrumentation depth. Many teams handle this by introducing sampling-tracing only a fraction of requests to reduce load and data volume. But that trade-off means you lose some visibility, especially for low-frequency or intermittent issues.
Last9, avoids this compromise. Instead of dropping data to control cost, Last9 is built to handle high-cardinality telemetry at scale-so you can keep full-fidelity traces and still keep storage predictable.
Sampling Configuration
Sampling helps control both runtime overhead and the volume of telemetry sent to the backend. Instead of tracing every request, you capture a fraction-while still collecting full details for error cases.
ELASTIC_APM = { 'SERVICE_NAME': 'python-app', 'TRANSACTION_SAMPLE_RATE': 0.1, # Capture 10% of transactions 'CAPTURE_BODY': 'errors', # Only capture request bodies when errors occur}This configuration keeps most request paths light while still giving you representative performance data and complete context when something fails.
Using Redis for Session Data in Traces
Some performance investigations benefit from knowing whether a request came from a first-time or returning user. Instead of querying the database for this metadata on every request, you can store it in Redis and enrich spans on the fly:
import redisfrom elasticapm.contrib.django.middleware import TracingMiddlewareimport elasticapm
class CustomTracingMiddleware(TracingMiddleware): def __init__(self, get_response): super().__init__(get_response) self.redis_client = redis.Redis(host='localhost', port=6379, db=0)
def process_request(self, request): session_data = self.redis_client.get(f"session:{request.session.session_key}") if session_data: elasticapm.set_user_context({'session_type': 'returning'}) return super().process_request(request)By adding this context, you can filter traces to analyze performance patterns across different user segments-without adding significant latency to each request.
Build Effective Dashboards
APM data is most useful when patterns are easy to spot. A good dashboard should make it clear which parts of your application are healthy and which need attention. Focus on these core views:
- Transaction Overview – Response time percentiles, error rates, and throughput by endpoint.
- Database Performance – Slow queries, connection pool usage, and query execution patterns.
- External Dependencies – Third-party API latency, error rates, and timeout occurrences.
- Error Analysis – Error frequency, new error types, and which user segments are impacted.
Most APM platforms let you create alerts from these metrics. Choose thresholds that surface issues before they affect users, such as triggering an alert when the 95th percentile response time breaches your SLA.
If you’re already using Grafana, you’ll feel right at home with Last9 Hosted Grafana-the same dashboarding experience without the operational overhead of running it yourself.
And for teams that want everything in one place, Last9 includes its own logs and traces UI, built to work seamlessly with your metrics so you can go from “something’s wrong” to “here’s why” without leaving the platform.
Unified Observability in Last9
Dashboards are far more useful when APM data, metrics, and logs live in one place. In Last9, Python APM traces are correlated with metrics and application logs, so you can move from symptom to root cause without switching tools.
Here’s what that looks like in practice:
- Correlated insights – View a latency spike and, in the same query, see the related database metrics and application logs.
- Live service map – Last9’s Discover Services automatically generates and updates your service topology from traces-no manual diagrams.
- Shows throughput, latency percentiles, and error rates per endpoint.
- Updates in real time as services or dependencies change.
- Full-fidelity traces – Retain high-cardinality telemetry without sampling, so you can debug rare or intermittent issues without data loss.
- Dependency-aware troubleshooting – Follow a performance issue through the exact chain of services and APIs it touches.
- Predictable cost model – Keep detailed traces and metrics without worrying about post-ingestion surprises.
This combination turns Python APM data into a complete operational view-linking every trace, metric, and log to the right service and dependency, so you get from “something’s wrong” to “here’s why” much faster.
Start for free today, or book time with us to see how Last9 can simplify your observability and make it more impactful.
FAQs
How much overhead does Python APM add?
Most Python APM agents add 1–3% CPU overhead and minimal memory usage. The exact impact depends on your transaction volume and how much custom instrumentation you add.
Can I use APM with async Python frameworks like FastAPI?
Yes. Modern APM tools support async frameworks, and both Elastic APM and OpenTelemetry handle FastAPI, Starlette, and other async frameworks with automatic instrumentation.
What’s the difference between APM and logging?
APM focuses on performance metrics and traces, while logging captures discrete events. APM shows you that a database query took 500 ms; logs show you what query ran and why.
Should I instrument every function in my application?
No. Start with key business logic, database operations, and external API calls. Over-instrumentation creates noise and increases overhead without adding value.
How do I handle sensitive data in APM traces?
Configure your APM agent to exclude sensitive fields from traces. Most tools let you filter request bodies, headers, and custom context data to prevent sensitive information from being collected.
Can I switch APM vendors later without changing my code?
If you use OpenTelemetry for instrumentation, yes. OpenTelemetry provides vendor-neutral APIs, so you can change backends by updating your exporter configuration.
How long should I retain APM data?
Keep detailed traces for 7–30 days for troubleshooting, and aggregate metrics for longer periods. High-cardinality trace data gets expensive to store long-term, so most teams focus retention on actionable timeframes.

