

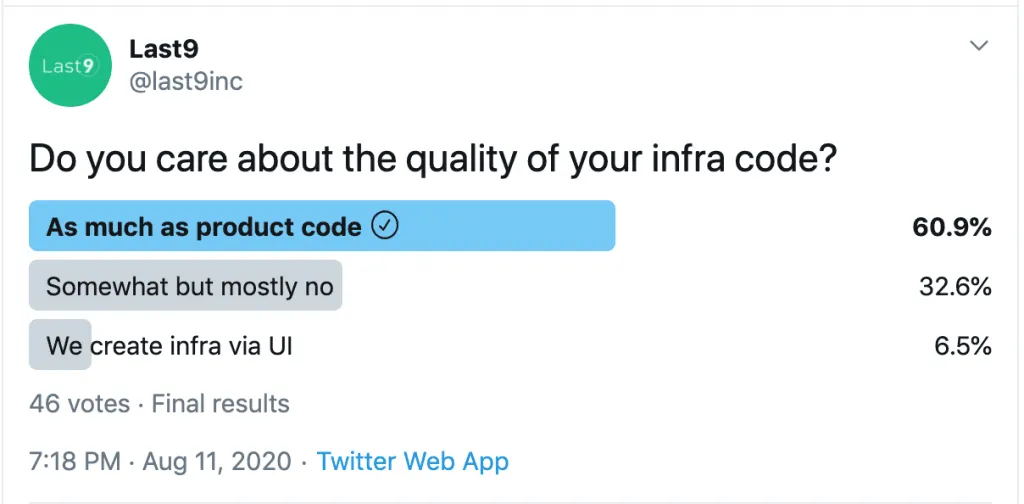
We ran a poll on Twitter.
“Do you care about the quality of your infrastructure code?”
And on Reddit
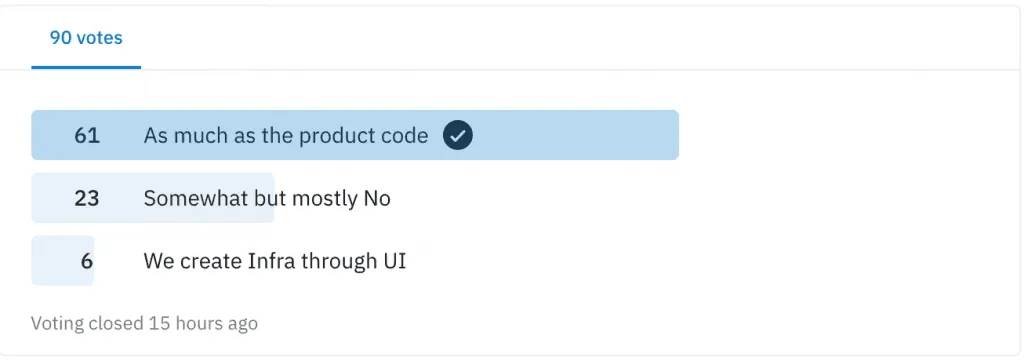
That’s an approximate and staggering 60–30–10 split.
What do you think will the response be if the poll was — “Do you care about the quality of your product code?”
Reasons
We asked a follow-up question to reason why ~30% are in the Somewhat but mostly no category and gleaned these reasons from Twitter and Reddit:
- Someone manually created the legacy infrastructure. No one questioned the practice or broke the tradition.
- Organizations at a small enough scale might feel that it is faster to deploy infrastructure from the cloud provider console than to codify it.
- Infrastructure-as-code DSL approach makes one think that software development practices don’t apply to it.
- Lack of visibility on the importance and benefits of treating infrastructure code at the same level as product code.
The last two reasons suggest a mindset gap between how developers approach infrastructure code v/s product code.
Developers are willing to invest time and effort to refactor product code and make it readable, modular, easy to maintain, etc. But often, these practices are not applied to infrastructure-as-code.
Ambition
The most common design principles that helped me get better at Software Engineering apply almost 1:1 to Infrastructure-as-code.
- 📒 Readability
- 🍴Separation of Concern
- 🔗Loose Coupling
- 🤼 Conway’s Law
- 📡IPC (Inter Process Communication)
- ♻️ Reusability and Abstraction
- 🔒 Dependency and Version Management
- 📄Static Code Checkers
The ambition of this post is to build the mindset that software is software. Be it infrastructure or product, the principles of — modularity, ease of use, reusability, maintainability apply to the “DevOps” code alike.
To seasoned practitioners, some of these thoughts may sound duh obvious. Maybe the similarity doesn’t appeal to you enough. In that case, I certainly hope that it is something you can refer others to. If the application of these principles resonate with you, bookmark this post and pass it along the next time you have to review that Pull Request and save an explanation of the Idea behind Infrastructure-as-code.
Enough talk!
The example case is simple: Deploy a minimal REST API and evolve its code from the easiest (read: ugliest) to what we think is production ready.
And, a pretty diagram. Because a pic or it didn’t happen
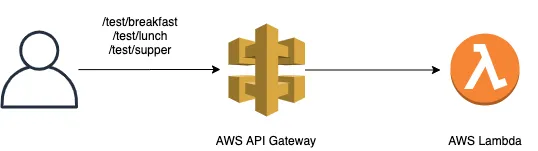
- AWS API gateway backed by AWS Lambda
$ curl http://$api_gw_url/test/breakfast | jq{"breakfast": {"time": "9 AM", "menu": ["poha", "chai"]}}
Setup
You must have the following installed/cloned on your system:
Each stage in tf_best_practices_infra_code repo creates the same infrastructure but with code evolved from the previous step. Hence it is necessary if you destroy infrastructure at the current phase before moving on to the next.
It would be worthwhile to clone the repositories to see the principles in action as the code evolves. We will go from 01_big_main_tf to 05_multi_env, explaining software engineering principles backing up each step in the evolution process. Some seasoned Terraform practitioners may skip the hands-on part and just read through the post to see how each stage builds upon the previous.
0/8 🛹 Make it work
Code:
├── README.md├── lambda.py├── lambda.zip└── main.tfAll the code is dumped into one main.tf. It may seem unusual to a few, but I have seen many projects with such a structure. Remember:
- When was the last time you wrote your product frontend, backend, and controller logic in one big file and shipped that product to your customers? Is your favorite Python module written as one big
main.py? - How will multiple developers collaborate on this code base?
- What happens when one more infrastructure component gets added?
- Even the Javascript world has moved on to splitting their js files
1/8 📒Readability
We thought of ending the post here and advise the reader to write all their Terraform code in one file.
Then 1998 called — they wanted their design principles back.
Code: 02_split_main_tf
├── README.md├── apigw.tf├── init.tf├── lambda.py├── lambda.tf├── lambda.zip├── outputs.tf└── variables.tfThis code layout reads better than the previous version. We can link the code layout to the architecture diagram and understand that lambda.tf deploys the lambda code and apigw.tf deploys the API Gateway code.
There are still some limitations:
- We didn’t improve the code — we just split one big file into multiple ones. One big pizza sliced into six pieces will still have the same calories.
- The file split surfaces meaningful learning: there are groups of related components that should be identified and bundled separately.
2/8 🍴Separation of Concern
Splitting codebase into multiple files ≠ separation of concern. The following components are tightly coupled, yet they reside in the same folder.
lambda.py - application code
lambda.tf - deploys the application code
apigw.tf - deploys the API Gateway.
If you had to redeploy just the lambda code, you would also need to tinker/no-op the API Gateway along. Every time your application code is updated, you do not redeploy the Load balancer or the database.
Bundling all infrastructure components together also has a runtime cost. If your application deployment code is in the same folder as your database infrastructure code — every small application deployment code change will also lead to checking the database code. Some changes to AWS components like the AWS API gateway, AWS RDS take north of 10 minutes!!
All you had to do was update an environment variable! It reminds me of no better image to describe the situation.

“My infrastructure’s deploying” is the new “My code’s compiling.”
3/8 🔗Loose Coupling
Let’s take the first swipe at decoupling the infrastructure and application codes.
Code: 03_split_infra_and_app
├── README.md.md├── apigw.tf├── init.tf├── lambda.tf├── outputs.tf└── variables.tflambda.py - app_code
├── README.md├── create-bucket.sh├── delete-bucket.sh├── lambda.py├── lambda.zip├── package.sh├── upload.shWhat is missing here:
- The deployment process is now split between app_code and 03_split_infra_and_app
- app_code creates and deletes its infrastructure via
create-bucket.shanddelete-bucket.shrespectively. The lambda code is uploaded viaupload.sh. - 03_split_infra_and_app assumes that the bucket is created and the lambda zip file is uploaded.
The assumption code is shown here and hard coded as follows:
s3_bucket = "test-tf-lambda-s3"s3_key = "lambda.zip"If the app code changes the bucket location, the infrastructure code will have no way of knowing that.
4/8 🤼 Conway’s Law and Service-Oriented Design
Conway’s law states that organization design systems mirror their own communication structure.
The division of teams handling different components is most prevalent in the infrastructure domain, e.g., networking teams, database teams, product teams, etc. These teams work independently and communicate with each other to identify integration points, e.g., the Database team speaks with the networking team to know which subnets to use when creating a private network database. More often than not, configuration changes like these are a significant contributing factor in repeat issues.
To map our sample setup infrastructure to teams:
- Application code — business logic code. Team: Product development team.
- AWS Lambda — deploys the application code artifact. Team: Product development team.
- AWS API Gateway — REST API endpoints definition and integration with AWS Lambda. Team: API management.
Let us evolve our infrastructure code accordingly.
But before we move ahead, In a service-oriented design, it’s incredibly crucial to establish:1. The exchange contracts2. The mode of communication.5/8 📡Inter Layer Communication
Code: 04_split_infra_and_app_remote_state
Terraform resources can access infrastructure information in two ways:
- data sources For example, if layer one creates a database, another layer can use
aws_rdsdata source to query information for the created RDS like the RDS endpoint. - remote state Instead of going to the last mile of the created AWS component, make a query to a centrally located Terraform remote state file. There are multiple remote backends to choose from, and we have used the most widely used option of AWS S3.
Stale Pro Tip: Use S3 + DynamoDB for remote state storage with locking. Without locking, there is always a possibility of multiple developers updating the same state file in parallel and overwriting each other’s changes.
01-base does this work for us? It creates the remote state infrastructure using the terraform-aws-state-mgmt module.
With the remote state addressed, let us revisit the folder layout and understand how it handles the separation of concerns between different layers.
├── 01-base ├── 02-app └── 03-infra01-base- base layer - Foundational infrastructure for storing state - creates S3 state bucket and DynamoDB lock table - least frequently updated.03-app- app layer -Infrastructure which deploys app_code in an AWS Lambda - uses base layer infrastructure to store state. Most frequently updated as application logic can change without impacting API Gateway infra.02-infra- infrastructure layer - Infrastructure for API Gateway - uses base layer infrastructure to store state and app layer to link API endpoints with Lambda backend. Updated more frequently than the base layer but less regularly than the app layer.
Just like a burger where one team builds the bottom bun, another team perfects the patty and offers multiple varieties, and a third team perfects the dressings.
⚽ Reading State the Hard Way.
- The base layer creates an S3 bucket and a DynamoDB table, which is used by the app and infrastructure layer. Unfortunately, Terraform does not permit variable interpolation while setting the state, so we have to initialize the app and infrastructure layer by passing in the bucket name and DynamoDB table name in the command line.
terraform init -backend=true \\-backend-config="bucket=test-tf-state-bucket-1" \\-backend-config="key=app.tfstate" \\-backend config="dynamodb_table=test-tf-state-lock-table-1"- The infrastructure can refer to the lambda attributes created in the app layer by using.
aws_lambda_functionTerraform data source:
data "aws_lambda_function" "test" { function_name = var.lambda_name}function_name = data.aws_lambda_function.test.function_nameuri = data.aws_lambda_function.test.invoke_arnWhat is Missing Here?
- Every data source lookup involves one or more network calls to look up the specific AWS resources, extending the terraform plan time. The technique is sufficient only if you have a few resources to refer to, but as the dependent resources increase, the number of Cloud API calls will increase.
- Data source lookups are limited by the implementation — what if you wanted to look up the list of tags applied to your S3 bucket and use the same for tagging your EC2 instance? No data source does that.
- One cannot use data source lookups cannot be used conditionally. A search that yields no resource results will result in an exception.
I have been unfortunate to witness AWS Rate limits exceeding just by querying the data sources, resulting in retries and too sluggish terraform plans.
One can improve Inter-Layer communication by moving from data.aws_lambda_function.* data source directs AWS component calls to data.terraform_remote_state.* remote state lookup calls.
Before
uri = data.aws_lambda_function.test.invoke_arnfunction_name = data.aws_lambda_function.test.function_nameAfter
lambda_name =data.terraform_remote_state.app.outputs.lambda_function_namelambda_invoke_arn = data.terraform_remote_state.app.outputs.lambda_function_invoke_arn6/8 ♻️Reusability and Abstraction
We have come a long way from one big file to using a remote state for state management and lookup between infrastructure layers. However, we still fall short on these questions:
- If you have to deploy the sample infrastructure in different environments e.g. dev, stage, prod — how much of the AWS API Gateway and Lambda code would you duplicate?
- Suppose this wildly original AWS API Gateway + Lambda pattern took the infrastructure world by storm, and different teams in your organization wanted to deploy the same API Gateway + Lambda infrastructure for their products. Should they be concerned with the gnarly internals of AWS API Gateway and AWS Lambda intricacies?
Terraform Modules
Modules are to Terraform what libraries as to programming — reusable components that can provide uniform functionality.
In our setup, we will leverage modules to deploy to dev and stage environments.
- Code repo and deployment steps: 05_multi_env
- Terraform module repo: tf_best_practices_sample_module
The caller code layout, along with dev and stage folders has another folder called common
This folder holds default values that can be overridden by each environment-specific folder e.g. common/lambda.tfvars has
lambda_timeout = 60lambda_memory_size = 128which is overridden at dev/02-app/input.tfvars
lambda_timeout = 30lambda_memory_size = 2567/8 📄Static Code Checking
A good developer uses code linters, static analysis, and document generation tools to bolster her application codebase. Both the tf_best_practices_infra_code and tf_best_practices_sample_module use pre-commit-terraform which wraps the following tools:
- terraform-docs — Generate documentation from variable descriptions.
- tflint — Terraform linter.
- tfsec — Terraform static analysis security checker.
If you are using MacOS, installing pre-commit via brew upgrades your python to 3.8 - check this issue here.
8/8 🔒 Dependency Locking
Can you imagine releasing your Ruby module without Gemfile.lock? Terraform’s landscape is no different. Along with git-based module version locking, you can have version locking on the:
- Terraform binary — we use tfenv to lock dev machine versions. To enforce specific versions in our codebase, we update the
terraformblock. For example - to lock Terraform version >= 0.12 but < 0.13 and 0.1, we add:
terraform { required_version = ">= 0.12, < 0.13, < 1.0"}This level of locking can be tightened further by specifying exact Terraform versions also.
- Terraform provider locking — Terraform uses providers to expose interfaces to different cloud provider APIs. These should also be locked by using the
required_providersblock:
terraform { required_version = "0.12.3" required_providers { aws = "2.62.0" }}🏁 Conclusion and Secrets
That’s about it for the code evolution process.
Using software engineering principles to make infrastructure code more robust and reliable is a learnable skill, and we hope this post will help you achieve that. However, no infrastructure codebase is perfect or has one right way of solving a problem. Our sample repositories are no different. If you think our codebase can be evolved further and have suggestions for improvement, please engage with us in the comment section.
ba dum tish
Most stages in tf_best_practices_infra_code have hidden bugs that don’t reveal themselves in basic testing. See if you can smoke them out. We will do the big reveal in the much-awaited sequel — Terraform from the trenches — Brunch after dinner?
Last9 is a Site Reliability Engineering (SRE) Platform that removes the guesswork from improving the reliability of your distributed systems.

