

We are determined to solve the cardinality problem in the time series world with Last9 - our Managed Time Series Data Warehouse.
We just released a new version of our metric gateway, which can handle cardinality workflows at a massive ‘scale’.
But what kind of workflows?
Cardinality workflows
- An ability to halt the metric that can put a system under duress.
- An ability to report when a metric is destined to breach cardinality limits.
- A periodically replenishing quota to allow newer cardinality.
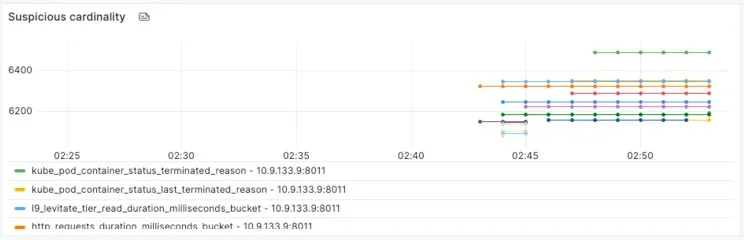
To deal with this Cardinality, we need a solid ability to:
- Count the Cardinality (Number of Series) Per Metric from an incoming stream.
- Differentiate, at that scale and cardinality, seen vs. fresh metrics.
This is a non-trivial problem at scale.

These may be solved problems.
- Counting cardinality can be done using HyperLogLog.
- Differentiation of seen vs. unseen can be done using Probabilistic Data structures like BloomFilters, Cuckoo filters, etc.
- One may even use traditional maps or hashtables.
But how do you do this at a scale of 500 million requests per minute? Or 500 million time Series arriving a minute.
- Without any locks, mutexes, and semaphores; for its speed.
- Without a massive impact on CPU and RAM; for its costs.
Let’s dive deeper 👇🏻
Finding the answer
The data structures to count cost CPU and Memory.
They must be atomic to be fast; they require a substantial amount of memory, to be precise.
Even the smartest of the data structures out there will suffer from this. We are talking about 500M time series being tracked.
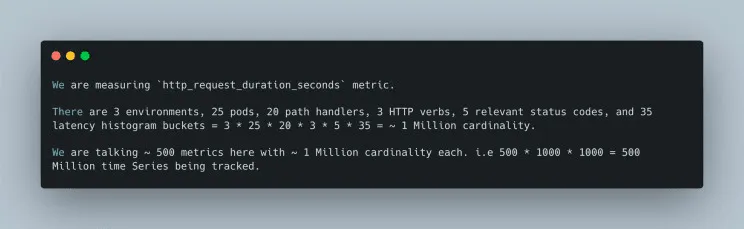
Should we use BloomFilter? It will cost 15GB of memory per metric per cluster.
We have 1000s of metrics from 100s of clusters created by our customers 🙀
A BloomFilter cannot guarantee that a value was seen earlier. So how do you allow a use-case where series that were seen already continue to be ingested and ONLY new ones are blocked?
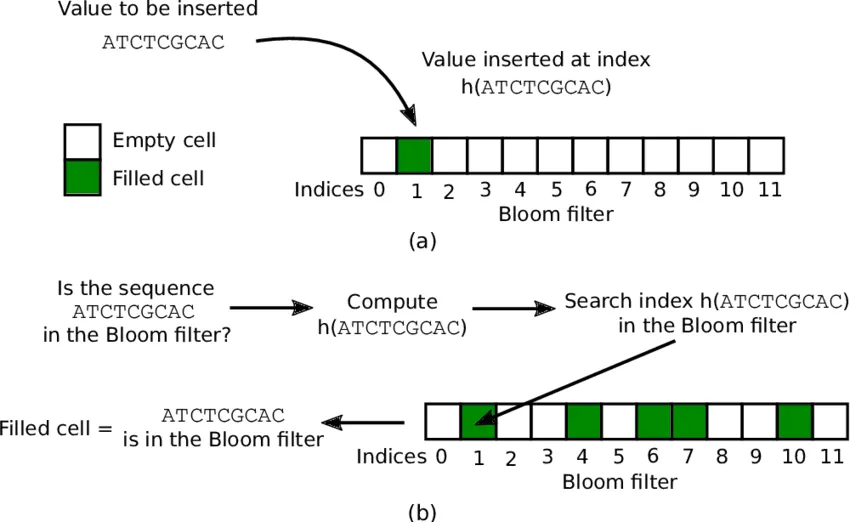
So an InverseBloomFilter? It is the same as a BloomFilter from space-time complexity but answers what has been seen instead of not seen.
While it can certainly tell a series has been seen before, It cannot tell what is “genuinely” missing to increase the cardinality by 1.
HashTables? An alternative that some propose is to use a cache object with expiration. The underlying hash map implementation will use 2.5x or more memory. And the maximum size setting means that items can be thrown out before we’d like them to be.
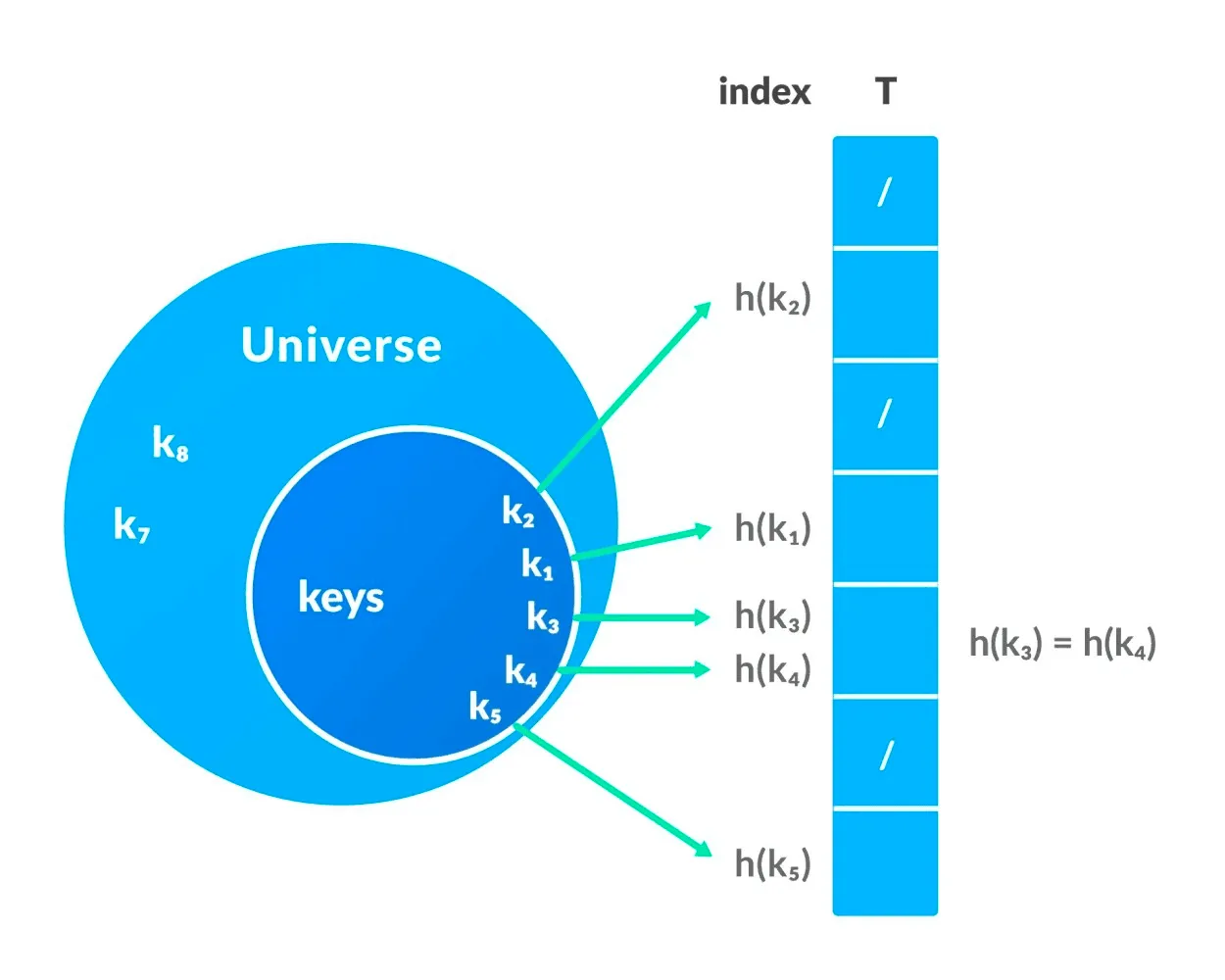
Using an expiring cache implementation is perfectly suitable for smaller datasets. Still, a vanilla hashtable or cache will blow up in memory requirements at the above scale.
Roaring Bitmaps? They consume far lower space using clever run-length encoding techniques.
But It loses the essence of tracking each series to reset/add a burst quota of allowed cardinality.
We even tried HyperLogLog and Cound Min Sketch.
Most data structures lack a CAS (Compare and Swap) implementation that can atomically operate without locking or reading starvation. This limitation applies to native maps and sync.Maps too.
Having to perform these operations for EVERY single SERIES per Metric consumes an insane amount of CPU and Memory.
Only if we could tell beforehand that something WILL or WILL NOT cross cardinality limits?
Only a customer could tell, but will they be around for every metric?

Two solutions that the industry has adopted:
- Lower the stress on cardinality counting and reduce it to pedestrian numbers.
- Switch to an inferior blanket counting system, which works on the overall system rather than per metric finesse.
But we don’t want to tap out.

How do we solve this? We built a CAS-only heuristic counter which has two modes:
- Coarse Mode
- Fine Mode
It has a Heuristical Model that detects an abnormal surge in cardinality and promotes the appropriate counter from Corase Mode to Fine mode.
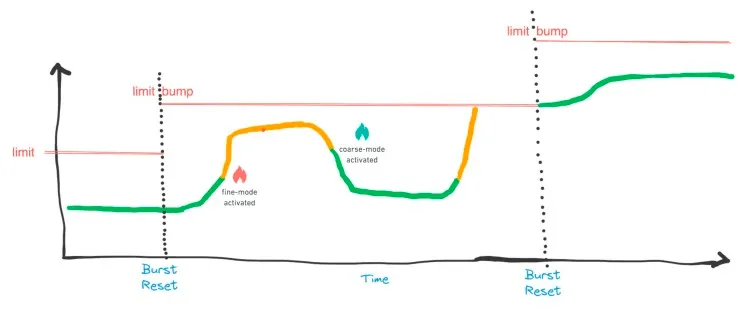
- In Coarse Mode, it operates like HyperLogLog and uses highly compressed Integer representations to track cardinality cheaply but inaccurately.
- In Fine Mode, the Counters precisely count but use more resources.
Results
Memory needed is 8 bytes in Coarse-mode and 10MB in Fine-mode.
Not only do we track Cardinality effectively at scale with ~ 95% reduced resources. But we could build interesting workflows to take cardinality head-on, like suspicious alerts.
Most cardinality explosion is accidental, whereas dimensionality is deliberate.
~ 95% lesser resources and greater accuracy.

Want to get rid of your cardinality woes? Try Last9 today or post a comment on this post, and I can showcase what you can unlock with our managed time series data warehouse!
And we are just getting started! We are determined to solve the cardinality challenge in the time series databases. Subscribe to our blog to learn more; part 2 of the series will be published next week!
UPDATE: Here’s part 2 of the post talking about Sharding.


