

In distributed systems, tracking how requests flow through various services can be tricky. Cloud tracing helps solve that by giving you clear visibility into what’s happening behind the scenes.
Tackling performance issues, pinpointing bottlenecks, or understanding how your services communicate with each other—all of these challenges become easier with cloud tracing. It offers clear visibility into the flow of requests across your distributed system.
In this blog, we’ll explore what cloud tracing is, why it’s important, and share some best practices to get you started. Plus, we’ll also talk about tools like Last9 to help you keep everything in check.
What Is Cloud Tracing?
Cloud tracing, also known as distributed tracing, is the practice of following requests or transactions as they travel across various services, APIs, and databases within a distributed system.
Imagine a GPS for your app’s traffic—it captures every stop, detour, and delay along the way. Mapping out the journey, cloud tracing provides visibility into complex interactions, helping pinpoint bottlenecks, diagnose errors, and optimize system performance.
For more on context propagation and its importance in tracing, check out our OpenTelemetry Context Propagation blog.
Why Does Cloud Tracing Matter?
Modern applications are no longer monoliths. They’re made up of microservices communicating through APIs and messaging systems, often deployed across multiple cloud environments.
While this setup boosts flexibility and scalability, it also makes troubleshooting significantly harder. That’s where cloud tracing shines:
Boosts Debugging Efficiency
Trace failures back to their roots—be it a slow database query or a buggy service.
Improves Performance Optimization
See which parts of your system need tuning for faster response times.
Empowers Collaboration
DevOps and engineering teams get shared visibility, reducing finger-pointing during incident resolution.
Key Components of Cloud Tracing
To truly understand cloud tracing, you need to familiarize yourself with its building blocks:
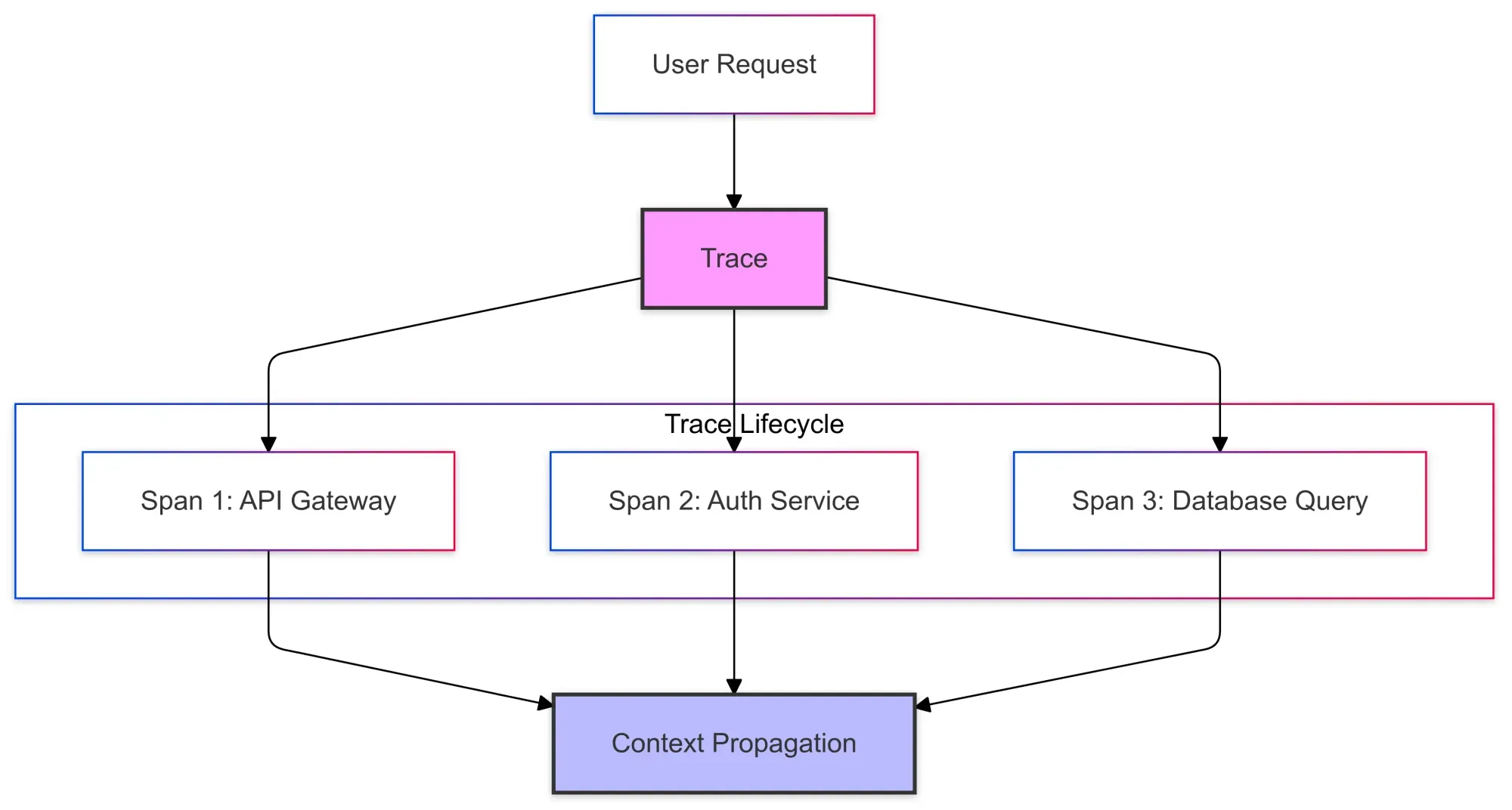
1. Traces
A trace is like a storyline. It represents the lifecycle of a request, from the moment it enters your system until it completes (or fails).
2. Spans
Spans are the chapters in your storyline. Each span represents an individual operation, such as calling an external API, executing a database query, or rendering a web page.
3. Context Propagation
Context propagation is the glue that holds everything together. It ensures that each service along the request’s path contributes its part to the trace, maintaining consistency.
To learn about integrating Kafka with OpenTelemetry, check out our Kafka with OpenTelemetry blog.
How Cloud Tracing Works
Instrumentation
Add tracing libraries or SDKs to your services to generate spans and traces.
Data Collection
Use agents to collect trace data from your application.
Trace Aggregation
Centralize your trace data in a tracing backend like Jaeger, Zipkin, or an APM solution.
Visualization and Analysis
Explore traces using dashboards to identify performance trends, bottlenecks, and error patterns.
10 Techniques for Modifying Trace Spans
Trace spans are the building blocks of distributed tracing, capturing granular details about operations within your application.
Customizing how spans are defined and modified allows developers to better align trace data with their specific requirements.
Here are some effective techniques to refine and manage trace spans:
1. Span Naming Conventions
Assign meaningful and consistent names to your spans. Clear names make it easier to understand the operation being measured. For instance:
- Use
GET /api/usersinstead of a generic “API Call.” - Append specific actions like
DB_Query_Insert_Userfor database-related spans.
2. Custom Span Attributes
Enrich spans with custom attributes to capture additional context. Attributes are key-value pairs that can include metadata like user IDs, request parameters, or environment details. For example:
span.set_attribute("user_id", "12345")span.set_attribute("region", "us-east-1")These attributes make filtering and analyzing traces much more intuitive.
For insights on converting OpenTelemetry traces to metrics, visit our Convert OpenTelemetry Traces to Metrics using SpanConnector blog.
3. Span Annotations
Annotations are timestamps or markers that highlight significant events within a span’s lifecycle.
For example, you might mark when a cache hit occurs or when a critical dependency is called:
span.add_event("Cache Hit", {"cache_key": "user_123"})4. Dynamic Span Sampling
Modify the rate or conditions under which spans are sampled. For example, you can:
- Sample all spans in production for critical services.
- Use a lower sampling rate for less critical ones to save resources.
Dynamic sampling ensures you capture the most important trace data without overwhelming storage or analysis tools.
5. Span Context Propagation
Ensure spans correctly propagate context across service boundaries. This involves passing trace IDs and span IDs in headers or metadata when making API calls. Using tools like OpenTelemetry, this process can often be automated with minimal setup.
6. Conditional Span Creation
Create spans only for specific conditions, such as slow queries or requests exceeding a latency threshold. This helps focus on anomalies rather than capturing every single operation:
if query_time > threshold: with tracer.start_as_current_span("slow_query") as span: span.set_attribute("query_time_ms", query_time)7. Span Batching and Aggregation
Batch similar spans or aggregate them into a single high-level span to reduce noise. For example, instead of tracking every individual database call, you could represent them as one aggregated “DB Transaction” span.
8. Error Handling and Status Codes
Explicitly set error statuses and record exceptions within spans. This helps trace back issues with rich error context:
try: perform_operation()except Exception as e: span.record_exception(e) span.set_status(Status.ERROR)9. Integrating Business Logic
Add custom logic to span modifications to capture domain-specific metrics. For instance, an e-commerce platform might record the cart size or order value within its spans to monitor user behavior.
10. Span Tags for Grouping
Use tags to group spans by characteristics like service, region, or user segment. This makes it easier to aggregate and analyze traces based on your application’s architecture.
Check out our Winston Logging in Node.js blog for more on integrating logging in your Node.js applications.
How to Integrate Cloud Trace with Logging Systems
Monitoring and troubleshooting modern applications can be a complex task, especially when dealing with distributed systems.
Cloud tracing and logging are two of the most powerful tools at your disposal for gaining visibility into your app’s performance.
When combined, they offer a more comprehensive approach to troubleshooting, performance optimization, and overall system health.
Why Integrate Cloud Trace and Logging?
While cloud tracing provides an end-to-end view of requests as they pass through services, logging offers detailed records of specific events or issues within those services.
Integrating both creates a richer, more connected view of your system, allowing you to:
Correlate Events
Link related logs and traces to understand the full context of an issue or request.
Pinpoint Issues Faster
Identify the root cause by drilling down from high-level traces to detailed logs and vice versa.
Simplify Troubleshooting
Reduce the time spent searching for issues by following the trace and examining logs simultaneously.
How to Integrate Cloud Trace with Logging Systems
1. Use Trace Context in Logs
One of the most important steps in integrating tracing and logging is to pass trace context (such as trace and span IDs) into your logs.
This enables you to connect log entries with corresponding traces, allowing you to track the entire journey of a request from the logs to the traces.
For example, when a trace is created, its trace ID and span ID can be added as metadata in the log entries:
import loggingtrace_id = span.context.trace_idspan_id = span.context.span_idlogging.info(f"Processing request with TraceID: {trace_id}, SpanID: {span_id}")By including trace context in your logs, you can easily filter and search for logs related to specific traces, which is especially useful when troubleshooting complex issues.
For more on structured logging in Python, check out our Python Logging with Structlog blog.
2. Use Distributed Tracing Libraries that Support Logging Integration
Many modern tracing tools and libraries, such as OpenTelemetry, allow you to integrate traces and logs out of the box. These tools can automatically enrich logs with trace context without needing to manually configure it every time.
This integration often extends to cloud logging services, like Google Cloud Logging or AWS CloudWatch, which can automatically capture trace data and display it alongside logs.
3. Create Log Entries for Key Trace Events
Instead of relying solely on tracing systems for visibility, create log entries at critical points in the trace to capture significant events.
For example, when a specific operation completes within a trace, log a message with relevant details:
span.add_event("Service A call completed", {"service": "ServiceA", "status": "success"})These log entries can provide detailed contextual information, such as success or failure statuses, request parameters, or performance metrics, allowing you to correlate specific trace events with your logs.
4. Centralize Your Observability Data
To get the most value from both traces and logs, it’s crucial to centralize your data in an observability platform.
Solutions like Elastic Stack, Datadog, or Last9 can collect both traces and logs in a single dashboard.
This consolidation gives you the ability to quickly search, visualize, and correlate data from both sources, creating a unified view of your system’s performance.
5. Set Alerts Based on Tracing and Log Data
By integrating trace data with logs, you can create more effective alerts that combine both metrics.
For example, if a trace spans a long duration or encounters errors, you can configure alerts that not only notify you but also provide logs related to that trace, giving you immediate insight into potential issues.
if span.duration > threshold: logging.error(f"Long request duration detected. TraceID: {trace_id}, Duration: {span.duration}")6. Create Trace-Backed Dashboards
Create custom dashboards that combine trace and log metrics, offering a full view of application performance. You can visualize trace statistics (e.g., average duration, latency) alongside logs showing error counts or throughput.
This approach provides a deeper understanding of your application’s health and helps identify patterns, like a specific service or API causing slowdowns.
7. Analyze Performance Bottlenecks with Traces and Logs Together
When you notice a performance bottleneck in a trace (e.g., an unusually slow request), you can explore the associated logs to identify issues such as resource constraints, database slow queries, or unexpected exceptions.
Combining trace data with logs lets you not only visualize where problems occur but also understand the “why” behind them.
To dive deeper into the challenges of distributed tracing, take a look at our Challenges of Distributed Tracing blog.
Best Practices for Integration
1. Ensure Proper Trace Context Propagation
Make sure that trace IDs are passed correctly through service boundaries. Without this, you won’t be able to correlate logs and traces properly.
2. Normalize Log Formats
Use a structured log format (like JSON) to make it easier to filter logs by tracing context and attributes.
3. Use a Single Tool for Both
Consider using an observability platform that provides integrated tracing and logging support. This ensures smoother data correlation and less friction between tools.
4. Don’t Overwhelm with Data
While it’s useful to have rich context in both traces and logs, avoid excessive logging at the span level. Focus on meaningful and actionable data to prevent unnecessary noise.
How Can You Customize Default Configurations in Cloud Trace
While default configurations in cloud tracing systems offer a solid starting point, many applications require tailored solutions to meet specific needs.
Below are key methods for customizing cloud trace configurations to align with your application’s requirements.
1. Adjusting Trace Sampling Rates
One of the most critical customization options is configuring trace sampling rates. By default, many tracing systems capture traces at a fixed rate (e.g., 1% or 100%). However, depending on the traffic load and the criticality of certain services, you might need to adjust the rate dynamically.
For example, in production environments, you may want to sample all traces for important services but reduce sampling for less critical ones. This prevents unnecessary performance overhead while ensuring you capture relevant data for high-traffic components.
How to Customize:
- Dynamic Sampling: Implement conditional sampling based on specific criteria, such as request latency, service type, or error rates.
- Rate Limiting: Use libraries like OpenTelemetry’s sampler to set rates like “100% for errors” or “1% for standard requests” across various service tiers.
from opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.trace.sampling import TraceIdRatioBased
# Set a sampling rate for high-traffic servicestrace_provider = TracerProvider(sampler=TraceIdRatioBased(0.01))For insights on how to protect sensitive information in your tracing data, check out our blog on Redacting Sensitive Data in OpenTelemetry Collector.
2. Customizing Span Attributes
By default, spans capture basic information like duration, service name, and status. However, developers can enhance these spans by adding custom attributes, providing deeper insights into the application’s specific needs.
For example, attributes like user IDs, API keys, request payloads, or transaction IDs can be added to spans for better tracking and analysis.
How to Customize:
- Add attributes specific to your application’s business logic.
- Use context from other parts of your code (e.g., authentication tokens or regional information).
span.set_attribute("user_id", user.id)span.set_attribute("request_method", "POST")3. Implementing Custom Span Events
Span events are powerful tools that help track significant actions within a span, such as database queries, cache hits, or external API calls.
Customizing these events allows developers to capture more granular information that might otherwise be missed.
How to Customize:
- Add custom events for key operations within your system, such as database interactions or external service calls.
- Use events to mark significant state changes, such as when a service begins processing a request or completes a task.
span.add_event("Database query started", {"query": "SELECT * FROM users"})span.add_event("Database query completed", {"duration_ms": 200})4. Configuring Span Names and Categorization
Span names by default often represent generic actions, like “HTTP Request” or “Database Call.” However, developers can customize span names to reflect more specific actions or use cases that matter most to their application.
How to Customize:
- Assign span names that are descriptive of the operation, such as “User Registration API Call” or “Payment Gateway Request.”
- Categorize spans based on service types, request types, or user actions.
with tracer.start_as_current_span("User Registration API Call") as span: # perform registration logicTo understand how the OpenTelemetry Collector can enhance your observability setup, take a look at our blog on What Is OpenTelemetry Collector?.
5. Contextual Propagation
Context propagation ensures trace information (such as trace IDs) is passed between distributed components so they can all contribute to a single trace.
Customizing how context is propagated is essential for ensuring trace data is accurately tracked as requests travel through your system.
How to Customize:
- Customize the way context is injected into headers or messages between services.
- Ensure that trace context is passed in every request, such as HTTP headers, gRPC metadata, or message queue headers.
# Propagate trace context through an HTTP request headerheaders = { "trace-id": span.context.trace_id, "span-id": span.context.span_id}response = requests.get("http://example.com", headers=headers)6. Error Handling and Status Codes
Customizing how errors are reported within spans is essential for capturing meaningful diagnostic data.
While some tracing systems automatically mark spans with error statuses when exceptions are thrown, developers may want more control over when and how errors are captured.
How to Customize:
- Manually set the error status on spans based on application-specific error conditions.
- Include detailed error messages or exception data within spans for a richer diagnostic context.
try: risky_operation()except Exception as e: span.set_status(Status.ERROR) span.record_exception(e)7. Customizing Trace and Span Duration Handling
In some cases, the default behavior for measuring trace duration may not align with your needs.
Developers can modify how trace durations are calculated, especially if certain operations (like waiting for an external API response) should be excluded from the total time.
How to Customize:
- Adjust the timing mechanism to exclude certain operations, or use custom timers to track specific parts of a request lifecycle.
- Add custom timeouts or thresholds for span durations to better track performance.
with tracer.start_as_current_span("Payment Processing") as span: start_time = time.time() process_payment() span.set_attribute("duration", time.time() - start_time)8. Integrating Custom Trace Logic for Specific Use Cases
For applications with highly specific needs (e.g., batch jobs, high-frequency trading), custom logic can be implemented to handle traces differently.
For instance, high-priority spans may require more detailed tracing, while others can be simplified.
How to Customize:
- Develop custom trace logic to capture specific types of traffic (e.g., batch processing or real-time analytics).
- Implement advanced logic like “trace only under certain conditions” to minimize overhead in low-priority areas.
if is_high_priority_transaction(transaction): with tracer.start_as_current_span("High-priority transaction") as span: # Capture detailed trace for this transaction9. Integrating Third-Party Metrics and Logs into Traces
Many applications use third-party services (e.g., databases, APIs, external systems). To get the most value from tracing, you can integrate third-party metrics and logs into your traces for a richer context.
How to Customize:
- Include external service latencies and error metrics in spans.
- Pull in additional logs from other systems and associate them with your trace spans.
span.set_attribute("db_latency", external_db.query_latency)What is Pub/Sub Tracing
Message-driven architectures, like Publish/Subscribe (Pub/Sub) systems, are a favorite choice for building scalable and flexible distributed systems.
However, they often introduce complexity when it comes to tracking and monitoring messages as they travel between components.
Pub/Sub tracing gives developers the ability to track messages as they flow from publishers to subscribers, making debugging and performance monitoring much more manageable.
For a comparison between OpenTelemetry and traditional APM tools, check out our blog on OpenTelemetry vs. Traditional APM Tools.
Why Pub/Sub Tracing is Crucial
In a message-driven system, messages hop across various services and intermediaries, making it hard to track what’s happening behind the scenes.
Pub/Sub tracing helps by tracking the entire lifecycle of a message—how it moves, gets processed, and what happens at each step. This visibility helps with:
- Tracking message flow: See where messages are at any point in the system.
- Debugging with context: Understand failures and delays by examining trace data linked to each message.
- Measuring performance: Monitor how long it takes for a message to travel through the system.
- Correlating logs and traces: Pinpoint issues more effectively by linking logs with trace information.
How Pub/Sub Tracing Works
Pub/Sub tracing involves adding trace context (like trace and span IDs) to messages as they’re published.
This allows each consumer or subscriber to continue the trace when processing that message, even if it passes through message brokers like Kafka or RabbitMQ.
Here’s how it works:
- Trace Context Propagation: Attach trace context to messages as they are published so that subscribers can continue the trace when consuming the message.
- Span Creation: Each time a message is processed, a new span is created to record relevant details, such as processing time, errors, etc.
- Log Correlation: Logs generated during message processing are correlated with trace data, allowing for deeper investigation into issues.
Enabling Pub/Sub Tracing
1. Integrating with OpenTelemetry for Pub/Sub Tracing
OpenTelemetry is an excellent tool for enabling Pub/Sub tracing, as it provides built-in support for tracing message-driven systems. Here’s how to set it up:
- Publisher Side: When publishing a message, OpenTelemetry attaches the trace context to the message.
from opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.trace import get_tracerfrom opentelemetry.propagators.textmap import set_span_in_context
tracer = get_tracer(__name__)
with tracer.start_as_current_span("Publishing Message") as span: span.set_attribute("message_type", "order_update") pubsub.publish(topic_name, message, trace_context=span.context)- Subscriber Side: On the consumer side, the trace context is extracted, and the trace continues.
from opentelemetry.trace import set_span_in_context
context = extract_trace_context_from_message(message)with tracer.start_as_current_span("Processing Message", context=context) as span: span.add_event("Processing started") # Handle the message here2. Manually Setting Trace Context in Pub/Sub Headers
For message brokers that don’t automatically propagate trace context, you can manually insert the trace context into message headers or metadata.
Example with Google Pub/Sub:
python from google.cloud import pubsub_v1 import opentelemetry.tracepublisher = pubsub_v1.PublisherClient()
span = opentelemetry.trace.get_tracer(__name__).start_span("Publishing Message")trace_context = { "trace-id": span.context.trace_id, "span-id": span.context.span_id}
topic_name = "projects/my-project/topics/my-topic"message_data = b"My message data"publisher.publish(topic_name, message_data, **trace_context)3. Monitoring and Debugging Pub/Sub Systems
Once Pub/Sub tracing is set up, you can monitor the flow of messages in your system and debug issues using trace data. Some key things to monitor:
- Latency Tracking: Track the time it takes for a message to go from publisher to subscriber and alert on delays.
- Error Detection: Trace failed or delayed messages through your system to identify where things went wrong.
- Message Throughput: Monitor the volume of messages being processed over time to assess system load.
- End-to-End Flow: Visualize the entire lifecycle of a message, from publishing to consumption.
Last9 has been an amazing partner in making inroads on what a solid observability platform should be. – Akash Saxena, CTO, Disney+ Hotstar
Benefits of Pub/Sub Tracing
- End-to-End Visibility: See the complete journey of messages across your system.
- Easier Debugging: Quickly find the root causes of issues by correlating trace and log data.
- Performance Insights: Measure how well your Pub/Sub system performs and identify bottlenecks.
- Better Error Handling: Detect and resolve issues where messages fail or are delayed.
- Scalability Monitoring: Monitor how your system performs under increased load as it scales.
Popular Tools for Cloud Tracing
Several tools and frameworks make cloud tracing easier:
- OpenTelemetry: A robust open-source project offering libraries and APIs for tracing, metrics, and logs.
- Jaeger: A distributed tracing system designed for monitoring and troubleshooting microservices.
- Zipkin: A simple yet effective tool for collecting and viewing trace data.
- Elastic APM: Provides end-to-end observability, combining tracing, metrics, and logging.
- Last9: A platform designed to simplify observability by unifying metrics, logs, and traces into one cohesive view, enabling teams to better monitor, trace, and troubleshoot their systems.
Best Practices for Implementing Cloud Tracing
- Start Small: Begin by implementing tracing for a few critical services, and gradually scale as you gain confidence and understanding of how traces can improve visibility.
- Focus on Key Metrics: Start by measuring essential metrics like latency, error rates, and throughput to evaluate performance and identify any potential bottlenecks.
- Integrate with Logs and Metrics: Enhance traceability by correlating trace data with logs and metrics. This combined approach helps in troubleshooting and getting a clearer view of system health.
- Automate Context Propagation: Ensure trace context (such as trace IDs) is automatically passed between services. This enables end-to-end visibility and makes tracking easier across your distributed systems.
Wrapping Up
Cloud tracing isn’t just a nice-to-have—it’s a must-have in today’s distributed computing landscape. It provides the visibility and clarity teams need to maintain high-performing systems while reducing downtime.
Got questions about cloud tracing or implementing it for your business? Let’s discuss on our Discord community!

