

Your application is handling peak traffic when something fails. Error logs don’t reveal much, and it’s not immediately clear which part of the system is slowing things down. In a distributed environment, finding the root cause quickly can be challenging.
APM tools are built for exactly this kind of situation. They instrument your code to capture performance metrics, trace requests across services, and send alerts when something isn’t working as expected. Instead of combing through logs in the middle of the night, you can use visual dashboards to see where latency or errors are coming from.
This guide walks through the essentials of setting up APM — from basic monitoring to advanced distributed tracing — so you can understand what’s happening inside your applications.
What is APM?
APM stands for Application Performance Monitoring. It’s about keeping track of how your application runs in production — how fast it responds, how reliable it is, and how much it uses system resources.
It works by adding instrumentation to your application so it can send performance data while users interact with it. You can do this in two main ways:
1. Auto-instrumentation agents
These are language-specific agents (for Java, Python, Node.js, Go, etc.) that hook into your application at runtime. They detect common frameworks, libraries, and operations automatically — like HTTP requests, database queries, and message queue interactions — without you having to change your code.
Example: In a Java Spring Boot service, attaching an OpenTelemetry Java agent can automatically trace incoming HTTP requests, JDBC calls, and Redis operations.
Ideal for quickly getting visibility into an existing application or when you want to monitor a broad range of services without modifying the codebase.
2. SDKs for custom instrumentation
Software Development Kits (SDKs) give you full control over what gets measured. You add trace spans, custom attributes, and business-specific metrics directly in your application code.
Example: In a Node.js Express app, you might use the OpenTelemetry SDK to create a custom span around a payment gateway call, adding attributes like order_id or payment_method to help with debugging and analysis.
Best when you need to track specific workflows, capture business logic, or add context that auto-instrumentation can’t detect.
APM tools usually track:
- Response times for APIs and services
- Error rates and stack traces
- CPU and memory usage
- Database query performance
- Third-party API latency and failures
This data helps you:
- See how requests move across services
- Understand memory and garbage collection patterns
- Find slow or failing database calls
- Debug errors with full context
For performance-critical domains like gaming, where rich visuals must be delivered with minimal latency, APM becomes essential for maintaining seamless user experiences and optimizing rendering pipelines.
You can follow these application monitoring best practices to make sure your APM setup stays effective as your systems grow in scale and complexity.
Key Components of APM
A complete APM platform is a set of capabilities that work together to give you a full view of your application’s performance.
- Real User Monitoring (RUM)
Captures what real users experience when using your app — page load times, interaction delays, and errors. This helps you see performance the same way your users do. - Synthetic Monitoring
Runs simulated user actions at regular intervals to test performance, even when no one’s using the system. Useful for catching issues early and checking SLA compliance. - Infrastructure Monitoring
Tracks the health of everything your app runs on — servers, containers, databases, and cloud services — so you can quickly spot whether an issue is in the app or the environment. - Application Discovery & Dependency Mapping
Automatically maps out your application’s services, APIs, and data flows, making it easier to understand complex, distributed systems. - Code-Level Diagnostics
Lets you drill down into the application code to pinpoint slow functions, inefficient database calls, or memory leaks that impact performance. - End-User Experience Monitoring
Focuses on the user journey — whether pages load smoothly, forms submit without delays, and transactions complete without errors. - Database Monitoring
Tracks SQL and NoSQL query performance, connection issues, and resource usage to keep data-intensive workloads running efficiently. - Transaction Profiling
Breaks down each transaction step-by-step to find where time is being spent, so you can eliminate bottlenecks and improve response times.
How Does APM Work?
An APM tool works by collecting performance data from your application and the systems it runs on — then turning that raw data into insights you can act on. Here’s what that looks like in practice:
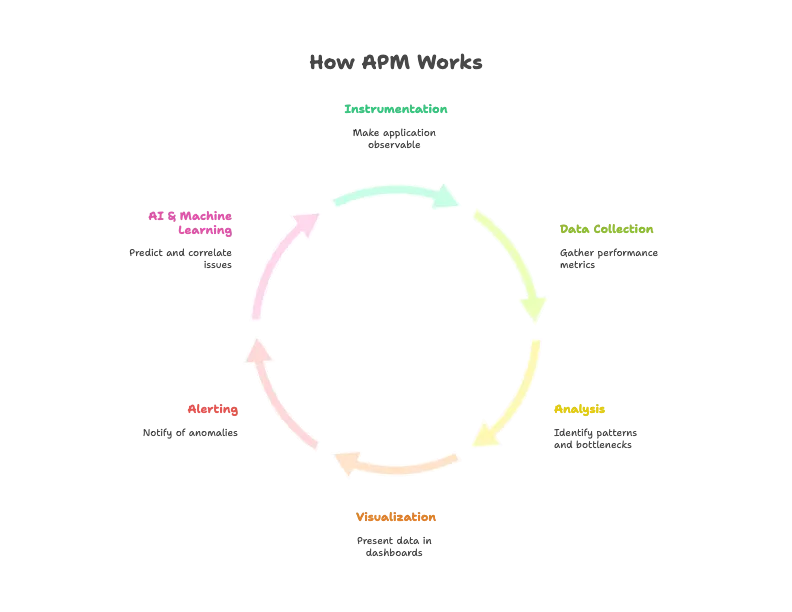
1. Instrumentation
First, you make your application “observable” by adding instrumentation.
- Automatic – Many APM tools ship agents for popular languages (Java, Python, Node.js, Go) that hook into frameworks and libraries to collect data without you writing extra code.
- Manual – You can also add custom instrumentation for high-value actions, like checkout flows or payment processing.
Example: You drop an OpenTelemetry Node.js agent into your Express app so you can track request latency and database query times instantly.
Learn how OpenTelemetry works with application performance monitoring in Last9’s guide to OpenTelemetry and APM.
2. Data Collection
Once instrumented, the APM starts gathering data from everywhere your app runs:
- Frontend Performance – How fast pages load, how long scripts take to run, and any JavaScript errors your users hit.
For example, you notice customers in Singapore have page loads twice as slow as US users — a hint that your CDN routing needs tweaking. - Backend Performance – Server and API response times, throughput, and error rates. For instance, A trace shows your
/checkoutendpoint slows down because the inventory API call takes 1.5 seconds. - Infrastructure Metrics – CPU, memory, disk I/O, and network throughput.
A spike in memory usage on one Kubernetes pod suggests a memory leak in the order processing service. - Application Logs – Error messages and stack traces for debugging.
You correlate a burst of 500 errors with a deployment from 10 minutes ago, pointing straight to the change that caused it. - Business Transactions – End-to-end tracking of workflows.
You follow a “Place Order” transaction from the moment a user clicks “Buy” through payment, order creation, and confirmation.
3. Analysis
The tool processes the collected data to find patterns, unusual spikes, or potential bottlenecks.
You spot a gradual 200ms increase in search service response times over the past week, long before customers complain.
4. Visualization
The APM gives you dashboards, service maps, and charts so you can quickly interpret the data.
- Heatmaps to see which APIs are slowest.
- Dependency graphs that show how services call each other.
- Drill-downs from top-level trends to individual traces.
5. Alerting
You set thresholds, and the APM lets you know when something’s off.
You get an alert when the error rate for the payment service goes above 2% for more than 5 minutes, with a link to the exact traces causing the spike.
6. AI & Machine Learning
APM tools use AI to connect the dots for you:
- Correlating a CPU spike on your database with a slowdown in your order API.
- Spotting a 25% drop in conversion rate, even if no error threshold is breached.
- Predicting that, at the current rate, your container will run out of memory in 2 hours.
Benefits of Implementing APM
When you put the right APM in place, you’re not just adding another dashboard — you’re giving yourself a way to keep applications healthy, resolve issues quickly, and make smarter decisions.
The benefits touch three areas: how the system runs, how your teams work, and how it impacts the bottom line.
Technical benefits — keeping the system healthy
See problems before users do
APM collects latency, error rate, and throughput data in real time. If checkout suddenly jumps from 1.2s to 3.8s after a deployment, you’ll spot it right away and can roll back before customers start dropping off.
Find the real cause, not just the symptom
Because traces, metrics, and logs are linked, you can follow a slow request across services until you hit the exact bottleneck. If 92% of the delay comes from a single inventory API call, you can fix that directly instead of guessing.
Identify early signs of trouble
Synthetic tests and baselines show when performance starts drifting from normal. If the p95 latency for “Search Products” climbs from 450ms to 700ms overnight, you’ll know before the morning traffic rush.
See the full picture
From the moment a user clicks “Buy” to the final database write, you can follow the entire transaction path. That visibility makes it easier to debug and to plan improvements in your architecture.
Operational benefits — helping teams work faster
One view for everyone
With service maps, traces, and resource metrics in the same place, developers and ops teams can skip the blame game and start fixing. Everyone’s working from the same facts.
Right-size infrastructure
Actual usage data means you can scale based on reality. If two pods run at 10% CPU all week, you can scale them down without risking performance.
Faster recovery when things break
Linked telemetry lets you jump straight to the failing component instead of digging through separate tools. Less time down, more time delivering.
Business benefits — turning performance into results
Happier users, better retention
Fast, reliable apps keep people coming back. Cutting API latency from 2.5s to 1.2s can mean more orders completed and fewer abandoned sessions.
Performance that pays off
Better performance boosts conversions and engagement — without extra marketing spend. Its growth is powered by speed and stability.
Decisions grounded in real data
With historical APM data, you can plan capacity for seasonal peaks, decide which features to optimize, and invest in the right infrastructure — all based on evidence, not guesswork.
See how tracing fits into the bigger picture of monitoring in our guide to APM tracing.
How to Choose the Right APM Solution
Choosing the right APM is all about making sure the tool fits into your current setup, scales with your architecture, and gives you the depth you need for real troubleshooting.
1. Compatibility with your stack
An APM should be able to plug into your environment without major rewrites.
- Languages & frameworks: Java with Spring Boot, Python with Django or Flask, Node.js with Express, Go microservices — check for native instrumentation and support for your specific framework hooks.
- Infrastructure awareness: If you run on Kubernetes, the tool should auto-discover pods, services, and namespaces. For serverless, it should support AWS Lambda, Azure Functions, or Google Cloud Functions.
- Protocol support: Verify coverage for HTTP, gRPC, message queues (Kafka, RabbitMQ), and database drivers you use.
2. Scalability
Your monitoring overhead should stay low as you scale.
- Data volume handling: Can it handle high-cardinality metrics without aggregation loss?
- Trace sampling: Look for dynamic or tail-based sampling so you can capture all errors while sampling normal traffic.
- Retention: Check how long you can store raw traces vs aggregated metrics, and whether you can tier storage.
3. Ease of use
A powerful APM is useless if your team avoids it because it’s hard to navigate.
- Dashboards should load fast, even with millions of time series.
- Traces should be searchable by service, span name, HTTP status, or custom attributes.
- The UI should support pivoting from a metric graph → trace → related log in a few clicks.
4. Integration with existing workflows
An APM should extend your current observability stack, not replace it entirely.
- Monitoring tools: Integration with Prometheus remote write, Grafana dashboards, and existing alert managers.
- Collaboration tools: Alert routing to Slack, Microsoft Teams, PagerDuty, or Opsgenie.
- CI/CD hooks: Ability to annotate deployments in dashboards and compare performance before/after releases.
5. Deployment options
- SaaS: Minimal maintenance, but check data residency and encryption.
- Self-hosted: More control, but you’ll manage scaling, updates, and HA.
- Hybrid: Store sensitive traces on-prem while using the cloud for metric dashboards.
6. Advanced analysis features
These can save hours in root cause analysis:
- Service maps: Auto-generated diagrams showing service dependencies and call volumes.
- Anomaly detection: ML models that learn normal response times for each endpoint and flag deviations.
- Correlation: Linking a CPU spike in the DB to increased checkout latency without manual investigation.
7. Full coverage of your architecture
A strong APM should give you visibility into:
- Web and mobile RUM (page load time, JavaScript errors, Core Web Vitals)
- Backend API performance (p50, p95 latency, error rates)
- Database queries (execution plans, slow query logs, lock waits)
- External API dependencies (latency, failure rates)
- Cloud provider services (S3, DynamoDB, GCP Pub/Sub)
8. Pricing model transparency
Understand how your usage will affect cost:
- Host-based: Good for static environments, but can get expensive with autoscaling.
- Data-ingestion-based: Flexible, but watch for cost spikes during incidents or load testing.
- Custom metrics charges: Some vendors bill separately for custom instrumentation.
With Last9 MCP, you can investigate APM data — metrics, traces, and logs — directly in your IDE, with full production context. This means you can trace a performance issue, inspect related telemetry, and apply fixes without leaving your development environment.
APM Tools vs. APM Platforms
Standalone APM tools are focused solutions designed to monitor specific aspects of application performance. They might specialize in transaction tracing, database monitoring, frontend performance tracking, or infrastructure metrics. These tools are often lightweight, easy to deploy, and excel at solving targeted problems.
What an APM Platform Brings to the Table
An APM platform takes a broader approach, combining multiple monitoring and diagnostic capabilities into one system. Instead of tracking just traces or metrics, a platform integrates end-user monitoring, service dependency mapping, code-level diagnostics, infrastructure monitoring, and alerting — all in a single place.
Advantages of Using Focused APM Tools
- Specialization: Purpose-built tools often go deeper in their area of focus. For example, a dedicated database monitor might provide detailed query execution plans, lock wait analysis, and index usage statistics.
- Lower overhead: Lighter agents and simpler dashboards can make these tools easier to run without affecting performance.
- Quick adoption: Teams can deploy them fast to address urgent monitoring gaps without reworking existing systems.
Limitations of Standalone APM Tools
- Fragmented view: Using multiple specialized tools can make it harder to see the full picture of a problem, since you’re switching between dashboards.
- Integration effort: Correlating data from separate tools often requires custom integrations or manual cross-checking.
- Scaling challenges: As your architecture grows in complexity, managing and maintaining several tools can add operational overhead.
Last9: A Complete, Otel-Native APM Approach
Last9 brings the depth of specialized monitoring tools and the breadth of a full APM platform — all built on OpenTelemetry, so you can use it with your existing instrumentation.
- Automatic service discovery
The moment you send traces, Last9’s Discover view maps every service, endpoint, and dependency — no manual tagging or setup. You’ll see throughput, error rates, latency, and APDEX scores for each service, making it easy to spot what needs attention. - End-to-end transaction visibility
Follow a request from the first browser click through APIs, microservices, queues, and databases. Every hop is linked, so you can drill into traces, logs, and metrics in the same view. - Real-time cost and data governance
With the Control Plane, you can drop, sample, or reroute telemetry instantly — without waiting for a redeploy. This keeps ingestion clean, predictable, and cost-efficient. - Vendor-neutral and future-proof
Last9 is fully Otel-native, so you’re not tied to proprietary agents. You own your telemetry, and you can route it anywhere if your needs change. - Scales with your architecture
Handle 20M+ cardinality per metric without losing granularity. Warm/cold tiering keeps historical data accessible, while streaming aggregation supports real-time analysis.
With Last9, you don’t have to choose between specialized depth and platform-wide visibility; you get both in an open, scalable, developer-friendly APM environment.
Get started for free today!
FAQs
1. What does APM mean in application performance?
APM stands for Application Performance Monitoring. It refers to the process of tracking and analyzing how an application behaves in production — including response times, error rates, resource usage, and overall reliability.
2. What is APM monitoring?
APM monitoring is the continuous collection of performance metrics, traces, and logs from an application and its supporting infrastructure. The goal is to detect slowdowns, errors, or resource issues and understand their root cause.
3. What is an example of an APM?
An APM could be a platform like Last9, Datadog, or Elastic APM that continuously monitors your application’s health and performance. For example, you might use an APM to:
- Trace a user request from the moment it hits your API gateway, through multiple microservices, down to a database query.
- Measure key metrics like API response times, error rates, memory usage, and CPU load in real time.
- Pinpoint slow components — such as an API call to a payment gateway that’s adding 1.5 seconds to checkout time.
- Visualize dependencies between services so you can see how an outage in one system affects others.
This means you’re not just seeing “the app is slow” — you can see exactly where and why it’s slow, then fix it.
4. What are the 5 dimensions of APM?
While frameworks differ, common dimensions include:
- End-user experience monitoring (real and synthetic)
- Application topology and dependency mapping
- Transaction tracing
- Application component metrics (CPU, memory, thread counts)
- Analytics and reporting
5. What is the full form of APM?
APM stands for Application Performance Monitoring. It’s the practice of tracking, analyzing, and optimizing how applications perform in production — including response times, error rates, resource usage, and overall availability.
6. What are forms of application performance monitoring?
- Real User Monitoring (RUM) – tracks actual user interactions.
- Synthetic monitoring – simulates transactions to test performance.
- Infrastructure monitoring – tracks servers, containers, and services.
- Code-level diagnostics – identifies performance hotspots in code.
7. What is Elastic Observability?
Elastic Observability is a solution built on the Elastic Stack (Elasticsearch, Logstash, Kibana, Beats) that unifies logs, metrics, and traces for application and infrastructure monitoring. It can be used as an APM by ingesting telemetry data and providing visualizations and alerts.
8. What are APM tools?
These are software platforms designed to monitor, analyze, and improve application performance. Examples include Last9, Elastic APM, Datadog, and Dynatrace.
9. What factors should you consider when choosing an application performance monitoring tool?
Key considerations include stack compatibility, scalability, integration with existing tools, ease of use, deployment options, depth of diagnostics, coverage (frontend to backend), and pricing model.
10. What are the main benefits of application performance management?
- Faster problem resolution
- Early detection of performance regressions
- Improved collaboration between Dev and Ops
- Smarter resource usage
- End-to-end visibility into transactions
- Better user experience and business outcomes
11. How does APM help in identifying application bottlenecks?
It correlates metrics, traces, and logs to show exactly where delays occur — whether in an API call, a database query, or an external service. For example, a trace might reveal that 80% of a request’s latency comes from a single slow SQL query.
12. How can APM improve the user experience of an application?
By keeping load times low, error rates minimal, and transactions reliable, APM ensures users can complete actions quickly and without frustration. It also helps optimize performance for different regions, devices, or network conditions.
13. How does application performance monitoring improve user experience?
It detects performance issues in real time and enables teams to fix them before users notice — maintaining smooth interactions, stable availability, and consistent performance.
14. How does application performance monitoring work?
It works by instrumenting applications to collect telemetry data, sending that data to an APM platform, analyzing it for patterns or anomalies, visualizing it in dashboards, and alerting teams when thresholds are breached.
15. How do APM tools help in identifying bottlenecks in applications?
The tools provide detailed traces and metrics that break down execution time across services and components. This makes it easy to see where the most time is being spent in a transaction.
16. How can APM improve user experience?
By ensuring applications stay responsive, reliable, and available under varying load conditions. Faster load times, fewer errors, and stable performance all contribute to better customer satisfaction.

