
Your user_login span has 47 different attributes. Your payment_processed metric tracks 12 dimensions. But when a customer reports that their payment failed, your incident workflow starts to unravel:
- In your Prometheus dashboard, the
payment_gateway_timeoutmetric shows a sudden spike. - In Grafana, the service map looks healthy, with no clear downstream errors.
- In Loki, you find 504 errors… but they lack a request ID to trace them.
- In Jaeger, traces are present, but only for successful flows. Failed spans don’t show up.
You have logs, metrics, and traces — but no shared thread across them. No consistent field naming. No trace ID in logs. No error labels in metrics.
It’s not that telemetry is missing; it’s fragmented. And that fragmentation is what slows down incident response.
When Your Monitoring System Becomes Part of the Problem
This fragmentation stems from how observability naturally evolves in most organizations:
- Telemetry grows organically
Observability often starts simple, adding logs to understand a specific issue, metrics to track service health, and traces as systems become distributed. Each addition makes sense at the time, but without a broader correlation strategy, the pieces don’t connect when you need them most. - Budget realities shape decisions
Trace sampling is typically set to 1% to manage costs. This works fine during normal operations, but it means most error scenarios, exactly what you need during incidents, aren’t captured. - Different teams, different approaches
It’s natural for teams to focus on their domain. Frontend teams instrument user journeys, backend teams track service health, and infrastructure teams monitor system resources. Each approach is sensible on its own, but can lead to:
- Different naming conventions across teams
- Varying timestamp formats
- Incompatible correlation strategies
The challenge: When systems face real stress, traffic spikes, cascading failures, and resource exhaustion, the observability stack often struggles alongside your applications. Export queues back up, collectors reach memory limits, and the telemetry you rely on becomes another system component under strain.
So, what does reliable observability look like? It starts with rethinking how signals are designed from the ground up
What Trustworthy Telemetry Looks Like
Telemetry you can trust starts with how signals are modeled, correlated, and built to hold up when things break. Most instrumentation focuses on the happy path — request rates, error percentages, and response times during normal operations. The real test comes during traffic spikes, edge cases, and when dependencies fail.
Building trustworthy telemetry requires three core principles that work together:
-
The foundation is signal fidelity
Signal fidelity means your telemetry shows complete cause-and-effect chains. When something breaks, you see what happened and why, not just symptoms.
When your service throws a 500, you should be able to see the specific error code, not just aggregated 5xx metrics, along with the exact database timeout that caused it, the retry attempts, and which user transactions were affected, in real time.
This granular visibility means distinguishing between a 500 Internal Server Error, a 502 Bad Gateway, or a 504 Gateway Timeout, rather than lumping them into broad categories that obscure the actual failure mode. No noise. No gaps
Structure your error logs with explicit context:
{"level": "error","message": "Payment processing failed","database_timeout_ms": 5000,"retry_count": 3,"affected_user_ids": ["usr_123", "usr_456"],"trace_id": "abc123","span_id": "def456"}Success paths need the same structured approach. Here’s what successful payment processing looks like with consistent telemetry:
{"level": "info","message": "Payment processed successfully","processing_time_ms": 247,"payment_method": "credit_card","transaction_amount": 127.5,"user_id": "usr_789","trace_id": "xyz789","span_id": "ghi012"}Whether the operation succeeds or fails, the structure stays consistent — making it easier to aggregate, compare, and analyze patterns across both outcomes.
But don’t stop at error logging. Instrument the context that helps during failures:
deployment_version— did this start after a new release?feature_flags_active— is experimental code involved?user_tier— is this hitting premium customers?upstream_service_health— are dependencies breaking?
Watch your cardinality:
deployment_versionhas low cardinality (maybe 10-20 active versions), whileuser_tierstays manageable (typically 3-5 tiers). Butfeature_flags_activecan explode — with 50 flags and various combinations, you’re looking at thousands of unique combinations. Use structured fields instead of individual boolean dimensions, and sample aggressively for non-critical paths. -
Building on that foundation is correlation integrity
High-quality signals are useless if you can’t connect them. The log line, the metric spike, and the failed trace span should all point to the same event, without timestamp alignment or grepping through logs.
This goes beyond adding
trace_idandrequest_idfields. Trace context gets lost at async boundaries when your payment processor queues work in the background. In event-driven architectures, correlation breaks when events cross service boundaries without proper context propagation.Build a correlation that survives system complexity:
- Inject trace context into message headers
- Use correlation IDs that survive async hops
- Implement context reconstruction at service entry points when the upstream context is missing
-
Completing the structure is operational resilience
Even perfect signals and correlation mean nothing if your telemetry disappears when you need it most. Log drops, missing spans, or delayed metrics during incidents aren’t annoyances; they’re blockers.
Use these patterns to keep telemetry flowing under pressure:
- Buffering – Temporarily holds telemetry in memory or disk when exporters are slow or unavailable
- Circuit breakers – Stop sending data to failing exporters to avoid overload and backpressure
- Fallback exporters – Automatically route telemetry to a secondary destination when the primary fails
-
Focus on failure modes, not just success metrics
These three principles work together to capture what matters most: why things fail and how systems recover. Instead of just tracking business metrics like signup rates, instrument business-relevant failure modes:
- Track
signup_funnel_completion_rate, but also capturesignup_funnel_abandonment_reasonsto understand why users drop off - Monitor
payment_processing_success_rate, but also logpayment_retry_attemptsandpayment_fallback_usedwhen the primary processor fails - Measure
feature_adoption_by_cohort, but also emitfeature_flag_X.errorsandfeature_rollback_triggeredwhen features break
Your system should emit telemetry for recovery behaviors:
timeout_eventsRetry_attemptscircuit_breaker.trippeddegraded_path_used
This shift from happy-path metrics to failure-aware instrumentation is what makes telemetry trustworthy when systems are under stress.
- Track
Why Trace Sampling Fails During Failures
Distributed tracing helps connect requests across services, but when failures hit, the traces you need are often missing. This happens for two main reasons: sampling strategies that miss critical errors, and span collection that breaks under pressure.
Wrong Requests Captured
Most tracing setups use head-based sampling, deciding whether to trace a request at the very beginning, before processing starts. This approach samples a fixed percentage of all incoming requests, regardless of their outcome. But that means you’re making sampling decisions without any signal about what the request will do.
In low-traffic systems, this might work. But at scale, it becomes a problem: the rare, buggy, or slow requests are exactly the ones most likely to be dropped.
The math gets worse during incidents when errors cluster. Consider a system with:
- 0.1% baseline error rate
- 1% head-based sampling
- 100,000 requests per hour
During normal operations, you get ~100 error traces per day. But during an incident, when error rates spike to 15% over a 30-minute window, those errors aren’t uniformly distributed; they’re concentrated exactly when you need visibility most. Your 1% sampling now captures only 1 in 100 of those critical failure traces, leaving you debugging blind during the peak failure period.
This is backwards. The traces teams need most, error traces, slow requests, and cross-service anomalies, are the ones most likely to be excluded by random chance.
Tail-based sampling fixes the incentives
Tail-based sampling solves this by making decisions after seeing the complete trace. OpenTelemetry Collector handles this with tail_sampling processors that can sample 100% of errors, 50% of slow requests (above the 95th percentile), and 1% of regular traffic. The processor waits for complete traces, then applies rules based on actual outcomes rather than random chance.
The trade-offs are real: requires buffering complete traces (increasing memory usage by 2-4x), adds decision latency of 10-30 seconds, and needs cross-service coordination for consistent sampling decisions. But the payoff is significant — you keep every error trace and capture latency outliers that head-based sampling would miss.
Missing Spans
Even if a trace is sampled correctly, it’s not useful if key spans are missing. Crashed services might not flush spans before going down. Network timeouts or overloaded exporters can silently drop them. Suddenly, your “sampled” trace is missing the one component that failed.
This is why resilient tracing setups plan for partial failure from day one:
- Buffered exports: OTEL SDKs and Collector hold spans in memory or disk until they can be sent
- Retries with backoff: Handle temporary export failures gracefully using retry_on_failure settings
- Fallback exporters: Route to secondary destinations when primary fails through Collector configuration
- Graceful degradation: Set appropriate timeouts and resource limits so telemetry export failures don’t impact your service
Without these patterns, you’re not observing the system during failures; you’re sampling around the problem.
Overcoming Distributed System Correlation Issues
Aligning telemetry across logs, metrics, and traces gets tricky when systems go async, crash mid-request, or drop context under load.
The biggest correlation challenges fall into two categories: data quality issues that break the foundation of reliable correlation, and distributed system complexities that fragment context.
Data Quality Issues
Poor data quality makes correlation impossible, even when you have all the right identifiers. The most common problems stem from inconsistent timing, classification, and schemas across services.
Clock drift breaks causality chains
Even 100ms of clock skew across services can make a timeout appear to happen before the request that caused it. In distributed traces, this manifests as child spans starting before their parents, or response logs appearing before request logs in the same transaction.
Use NTP synchronization across all services (aim for <10ms drift). Include relative timestamps like time_since_request_start_ms in spans alongside absolute ones for ordering within request boundaries.
Inconsistent standards create confusion
When timeouts are labeled as client errors in one service and server errors in another, you can’t determine ownership or group errors reliably. Similarly, if metric names or log field structures change without versioning, queries break and historical comparisons stop working.
Establish shared standards across teams:
- Error classification: Timeouts →
504 Gateway Timeout - Rate limits →
429 Too Many Requests - Schema versioning: Don’t remove or rename fields without a migration plan
- Metric alignment: Use consistent roll-up windows and label sets across related metrics
Your signals should tell one story.
Distributed System Complexities
Even with perfect data quality, distributed systems create correlation challenges that trace IDs alone can’t solve. Context gets lost at async boundaries, and clean request lifecycles are a myth when retries, crashes, and queues are involved.
Build a correlation that survives system boundaries
When traces fall apart, persistent identifiers become your lifeline. Fields like user_id, session_token, or order_id can bridge disconnected events across systems.
But raw IDs create their problems — privacy risks, high cardinality costs, and retention headaches. Use safer patterns:
user_hash: Hashed ID, privacy-safesession_id: Time-bounded, expires naturallyrequest_id: One per requestcorrelation_id: Ties together business-level flows
Apply these identifiers everywhere: logs, metrics, spans. Even when a trace is missing, you can still group related events.
Design for async complexity
Background jobs, queue workers, and cron tasks often run without upstream context. If you don’t explicitly pass correlation keys, those parts of your system become trace dead ends.
From day one, design your telemetry to handle missing parent spans, cross-service retries, and async hops with no headers. Inject correlation fields into message headers and reconstruct context at service entry points.
Normalize across signal types
Debugging involves multiple layers — application traces, infrastructure metrics, deploy events, and external dependencies. If they don’t share consistent timestamps, service labels, or correlation fields, you’re stuck squinting at dashboards instead of solving problems.
Use shared structure: synchronized clocks (NTP), consistent service.name and environment tags, and unified IDs across tools.
Correlation is what turns fragmented telemetry into something debuggable.
Health Checks That Work
A 200 OK from every service might look reassuring, but it doesn’t always mean your system is working as expected. Health checks that focus only on availability can miss whether users can complete what they came to do.
Test actual user flows
Liveness and readiness checks are useful for catching crashes and startup delays. But in distributed systems, all services can return 200 OK, while user workflows still break.
That’s why many teams layer in synthetic checks that exercise key workflows, like creating a user, completing a transaction, or validating that a purchase appears in the database.
This shifts the focus from “Is this service up?” to “Can someone search, add to cart, and check out successfully?”
Catch degradation before users do
Synthetic transactions simulate real user flows at fixed intervals, even when traffic is low. They’re great for catching:
- Slow degradation
- Longer-than-usual response times
- Cross-service failures that don’t trigger alarms
By emulating critical journeys, they help teams spot subtle failures before users do.
Monitor what users actually do
System uptime is important, but it’s only part of the picture. What matters is whether core business flows are working:
- Can new users register?
- Are payments going through?
- Are transactions silently failing?
Framing health in terms of business outcomes helps teams prioritize the right alerts and understand the real-world impact of failures faster.
Use OpenTelemetry as the Backbone of Your Observability Stack
Most observability stacks break during incidents because of fragmented correlation, lost context, and brittle pipelines. OpenTelemetry addresses these core issues, but with some limitations.
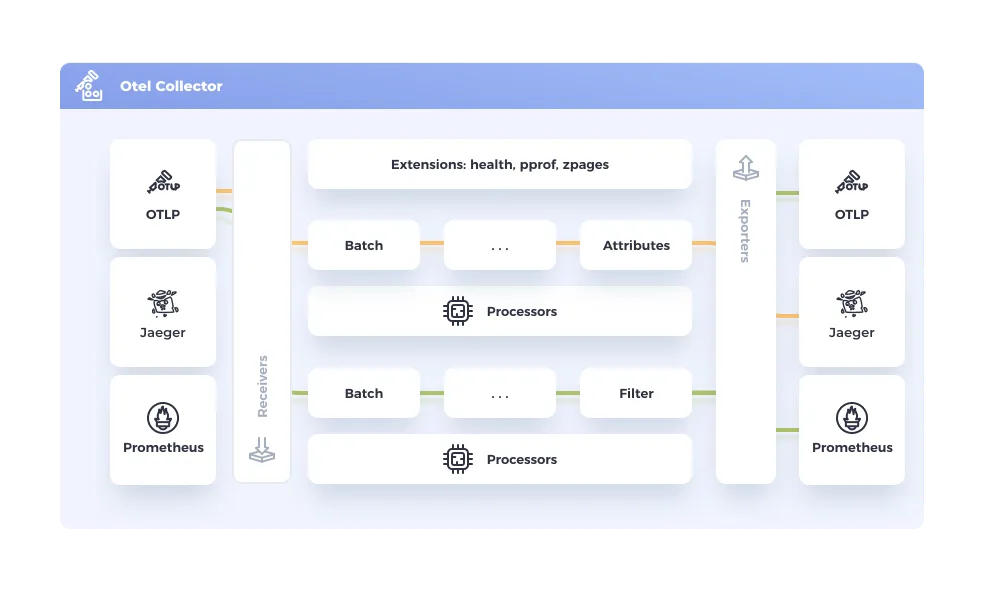
- Fragmented correlation: When every tool uses different field names (
http_statusvsstatus_codevsresponse_code), you waste critical time during incidents translating between formats. OTEL’s semantic conventions standardize this ashttp.response.status_codeacross all signals. However, not all observability vendors fully implement semantic conventions yet, so you may still encounter inconsistencies. - Lost context: Trace context disappears at service boundaries and async operations, breaking your ability to follow requests end-to-end. OTEL’s context propagation ensures
trace_idflows seamlessly across services. The gap: legacy systems and custom protocols still require manual instrumentation work. - Brittle pipelines: Custom telemetry infrastructure fails exactly when you need it most. The OTEL Collector provides resilient buffering, retries, and routing that keep telemetry flowing during failures. But this still requires operational expertise to configure and maintain properly; it’s not a set-and-forget solution.
The result is faster incident resolution because you can jump between logs, metrics, and traces without losing context, plus vendor flexibility without rewriting instrumentation. Just don’t expect it to solve observability problems that require architectural changes to your systems.
How Last9 Helps You
You don’t need perfect observability on day one, just telemetry that holds up when systems fail. That’s exactly what Last9 is built for.
Seamless correlation across signals
Last9 connects logs, metrics, and traces using OpenTelemetry standards and supports full-fidelity data, no sampling, no missing context. With Last9 LogMetrics and TraceMetrics, you can turn logs and spans into real-time metrics for alerting and analysis.
Jump from a metric spike to the exact log line or trace span, no grepping, no timestamp hacks. And with real-time remapping, inconsistent field names like custID and customerID are automatically standardized.

Built for high cardinality and real-time insights
Send high-cardinality fields like user_id and transaction_id without worrying about performance or costs. Last9 gives you granular visibility without tradeoffs.
No surprises during incidents
Other platforms spike your bill during outages. Last9 avoids this with streaming aggregations, query-time computations, and an architecture designed to prevent cost explosions, without compromising fidelity.
Built for teams under pressure
Last9’s architecture is designed to stay resilient when things break. Out of the 20 largest livestreamed events in history, 12 were monitored with Last9, demonstrating proven scalability!
Get started with Last9 and experience observability that works when you need it most.
