

All monitoring systems need a Time Series Database (TSDB). Without a TSDB, you can’t monitor the performance of a system.
A ‘time series’ series means there’s a time stamp, a metric, and a value.
So when a machine emits data, it stores the time, CPU percentage, etc… and a few other identifiers — this shows up as a chart to be monitored.
There are currently two large open-source TSDBs in the market — Prometheus and Victoria Metrics.
Both of them come with their advantages and disadvantages. But folks unanimously agree on one commonality: They’re hard to scale, and for large organizations, they become unsustainable over time; which means your monitoring systems work against you exploding in Cardinality and costs. This limits the engineering teams in the functionalities they should expect from their monitoring systems.
So, if a conventional TSDB becomes outdated as an org grows, what next?
That’s when you need a Time Series Data Warehouse (TSDW)
What is a Time Series Data Warehouse
A Time Series Data Warehouse brings the goodness of Data Warehousing principles to time series storage. By incorporating these Data Warehousing techniques in a conventional time series storage, monitoring systems get faster, cheaper, and simpler. But that’s not all.
Multiple teams can use a Data Warehouse to ‘explore’ data and make meaning out of it for key business decisions. Its ‘analytical’ capabilities make it powerful for an organization. Last9 is a TSDW, not a TSDB.
Requirements from a Time Series Data Warehouse
The absolute basic requirements of a TSDW can be summarised into three points:
- Fast query execution while keeping costs under check
- Elasticity to handle high volume and cardinality data
- Policies and governance to ensure data isolation between teams
How a TSDW fulfills these requirements
A TSDW brings three key elements to the table:
- Data Tiering: to isolate hot data and warm or cold data.
- High Cardinality: Pre-aggregation of data to solve for cardinality.
- Policies & Governance: Functionality to provide Data Policies and Access Policies.
Let’s study these three elements in detail:
Data Tiering
A TSDW needs Data Tiering to be accessible to teams and eke out more from your monitoring systems. You need the ability to ‘tier’ data into different categories improving the performance of systems.
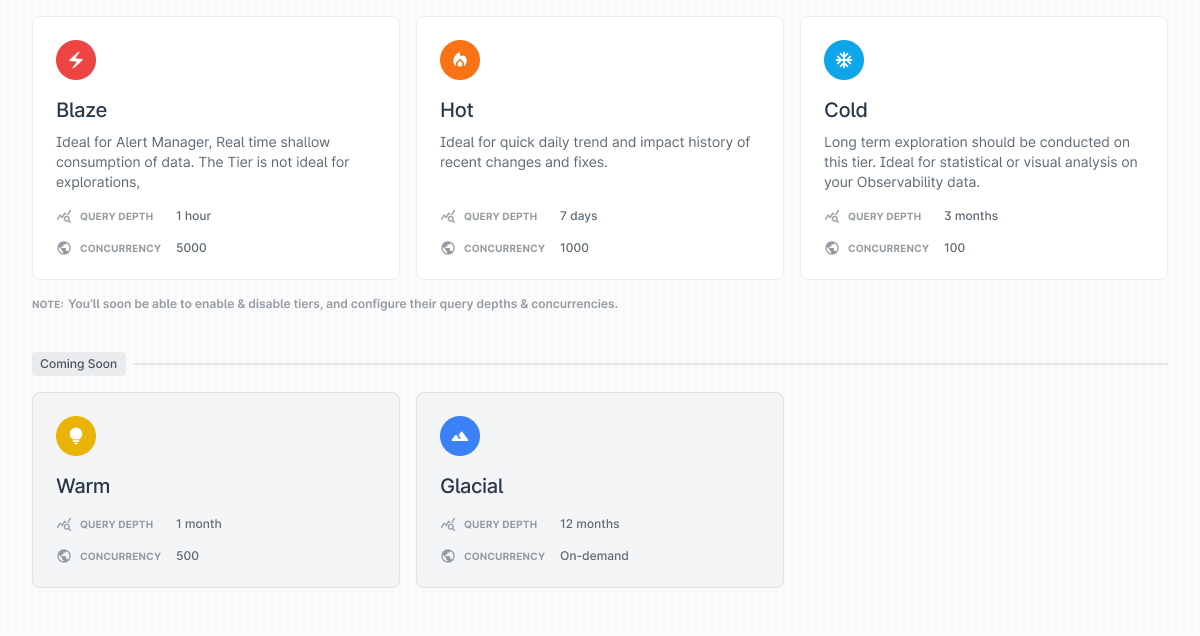
Take the above example: the Blaze tier helps in real-time monitoring of mission-critical events. However, you can’t explore, and dice data as the query depth is only for 1 hour. This improves performance for specific teams while other teams can query data from non-urgent tiers.
Teams only have to emit metrics to a single write endpoint from an integration perspective, and data reaches each of the respective Tiers. All Tiers have all the fresh data, but their data retention varies. Each tier functions as a completely independent Time Series database but serves different concurrencies, query latency, and depths.
By doing this, your TSDW is far more performant, has no lags, and saves on costs.
How does this work?
To understand the power of tiers, imagine the current situation where all the metrics, used or unused, are saved in the database. Say there is an auto-refreshing dashboard panel that greedily aggregates 6 months of payment failures saved per transaction and renders it on a histogram chart.
Now, imagine five such dashboards, refreshing every 15 seconds.
This is enough to bring an 8-core, 32GB RAM database to its knees. During this period, the ingestion, as well as critical alerting, gets impacted.
These are real on-the-floor problems with each team having 10+ dashboards per service and the nuisance compounds when you realize multiple teams querying for large data sets.
💡 You don’t just pay extra for what you don’t use; you pay extra because of what you don’t use.
Tiering enables different teams to query data and analyze data to make meaningful business decisions.
Last9 can segregate data into Virtual clusters, or Tiers, with distinct access control parameters like:
- Retention Limit - Limit the data that is available in the Tier—i.e x months/days/hours.
- Concurrency Control - Limit the active number of queries the Tier can handle simultaneously. This is the most trustworthy indicator of Performance.
- Range Control - Limit the number of days of data allowed to be looked up in a single query. It directly impacts the number of data points or series loaded into the memory.
High Cardinality
With large distributed systems and a complicated infrastructure, High Cardinality data is inevitable. Open Source tools and conventional TSDBs have strict restrictions on querying High Cardinality data. This comes with different kinds of penalties; from exorbitant costs, to slow dashboards and crashing systems. In effect, one is robbing users from accessing their data.
Over time, your monitoring systems work against the purpose it’s been designed for; observing problems.
With a TSDW, one can get deep visibility and early warnings about cardinality explosion before it happens. One can control data growth with Streaming Aggregations and slash the operational overhead of expensive queries.
How does this work?
As a TSDW, Last9 pre-aggregates the most expensive queries ahead of time, drastically reducing cardinality.
Streaming Aggregation, unlike Recording Rules, aggregates the data in real-time as it arrives, massively reducing the query overhead at runtime.
You can now leverage the power of PromQL to create aggregations without the complexity of pipelines.
Policies and Governance
Data is used differently across different teams. Some teams need historical data from 6 months back, and engineers from the SRE team need data from an hour back. Needs vary across teams and organizations.
Current time series tooling only has features to cater to different kinds of engineers across the org. It dissuades Product and Business teams among others from ‘explore’ data. Last9 solves this with Policies & Governance.
How does this work?
Last9 creates guardrails for time series data retention, storage, and access, across teams. These guardrails ensure data is highly available for teams with varying needs.
Policies are divided into two: Data Policies & Access Policies
Access Policies control how Tiers are engaged based on Access Methods. Access Policies give you control over querying data across different tiers. This reduces infra costs, gives faster alerts, and improves the speed of queries.
Data Policies control how data moves in and out of Tiers based on Access Frequency and Time.
Policies and governance helps our customers define control parameters for different teams. This gives flexibility to an organization to controls costs and makes dashboards highly available.
Conclusion
Let me quickly summarise the 3 pointers that make a TSDW:
- Data Tiering - Ability to slice data to keep your dashboards highly performant
- High Cardinality - Tame explosion of data and control costs, don’t be blindsided
- Policies & Governance - Enable data exploration across all teams
A TSDB and TSDW matter a lot depending on the scale of the organisation. If you have only 5 engineers and 5 services with under 10 customers, it makes sense to use a TSDB. At this size, you’re a fledgling startup trying to win more customers to scale.
If you’re maturing as an engineering organization with 20+ services and 30+ engineers, it’s time to start looking at a TSDW to get effective monitoring practices in place and nip lags and downtimes. This is also when you start realizing the implications of High Cardinality and the costs associated with monitoring. A TSDW solves a lot of these worries.
Wondering when to start thinking of a TSDW over a TSDB? All answers are here on our whitepaper.
Want to understand more about Data Tiering, Access Policies, how we tame high cardinality and more? All Product documentation here.

