

Nginx is widely known for its high performance and reliability. However, just like any software running in production, it requires continuous monitoring to ensure smooth operation.
Issues such as high latency, unexpected crashes, or overwhelming traffic spikes can lead to performance degradation or even complete outages. Therefore, implementing a robust monitoring strategy is crucial to maintaining the health and stability of your Nginx deployment.
This guide provides a deep dive into Nginx monitoring, covering essential metrics, tools, and best practices.
Why Monitoring Nginx is Essential for Performance and Stability
Monitoring your Nginx deployment allows you to:
- Detect performance bottlenecks before they escalate into major problems.
- Reduce downtime and improve incident response times.
- Understand traffic trends and optimize configurations accordingly.
- Identify potential security threats, such as brute-force login attempts and DDoS attacks.
For a deeper understanding of user experience beyond server-side metrics, check out our guide on Real User Monitoring (RUM) to track performance from an end-user perspective.
4 Key Metrics to Monitor in Nginx
Nginx generates a wealth of performance and traffic data. Below are the most important metrics to monitor:
1. Traffic and Connection Metrics
Requests per Second
This metric indicates how many HTTP requests Nginx is handling per second. A sudden increase may indicate a traffic spike, while a drop might suggest an outage.
Example command to check request rate using access logs:
tail -n 1000 /var/log/nginx/access.log | wc -lThis counts the number of log entries in the last 1000 lines, giving an estimate of the request rate.
Active Connections
This represents the number of clients currently connected to Nginx. A high number might indicate a flood of incoming requests or a slow backend response.
You can check this using the stub_status module (explained below).
Dropped Requests
Dropped requests indicate that the server is overwhelmed. This might be due to resource constraints or improper configurations such as low worker process limits.
2. Performance Metrics
Response Time
Response time measures how long it takes for Nginx to process and serve a request. Increased response times could mean resource exhaustion, inefficient configurations, or backend issues.
Example: Use curl to measure response time from a terminal:
curl -o /dev/null -s -w "%{time_total}\n" http://your-nginx-server.comThis outputs the total time taken to process the request.
Upstream Response Time
If Nginx is acting as a reverse proxy, upstream response time helps determine how quickly the backend servers respond. High values indicate slow application performance or networking delays.
Error Rate (HTTP 4xx and 5xx Errors)
Monitoring error responses helps identify user-related issues (4xx errors) and server-side failures (5xx errors). You can analyze error logs to find patterns.
Example command to count 5xx errors in logs:
grep " 5[0-9][0-9] " /var/log/nginx/access.log | wc -lTo better understand frontend performance bottlenecks alongside Nginx monitoring, explore our guide on Total Blocking Time (TBT) and how it impacts user experience.
3. System Resource Utilization
CPU and Memory Usage
High CPU or memory consumption by Nginx can indicate inefficient configurations or excessive request handling. Use tools like htop or top to monitor system resource usage in real time.
Disk I/O Usage
If Nginx logs are stored locally, excessive disk I/O operations can slow down the server. Tools like iostat can help monitor disk performance.
4. Security Metrics
Failed Login Attempts
Brute-force login attempts against Nginx-protected resources should be tracked and mitigated.
SSL/TLS Handshake Failures
These failures may indicate misconfigured SSL certificates or ongoing attacks.
Example log analysis:
grep "SSL: error" /var/log/nginx/error.log5 Easy Methods to Monitor Nginx
1. Using Nginx’s Built-in Stub Status Module for Basic Monitoring
Nginx provides a simple way to check basic metrics via the stub_status module. To enable it, add the following to your Nginx configuration:
server { listen 80; server_name localhost; location /nginx_status { stub_status; allow 127.0.0.1; # Restrict access deny all; }}Then access it via:
curl http://localhost/nginx_statusYou’ll see output like this:
Active connections: 10server accepts handled requests 1000 1000 2000Reading: 0 Writing: 2 Waiting: 82. Analyzing Logs for Deeper Insights
Nginx logs provide detailed insights into request patterns, errors, and security events. Configure logs as follows:
access_log /var/log/nginx/access.log;error_log /var/log/nginx/error.log warn;You can use grep, awk, or tools like Last9 for log analysis.
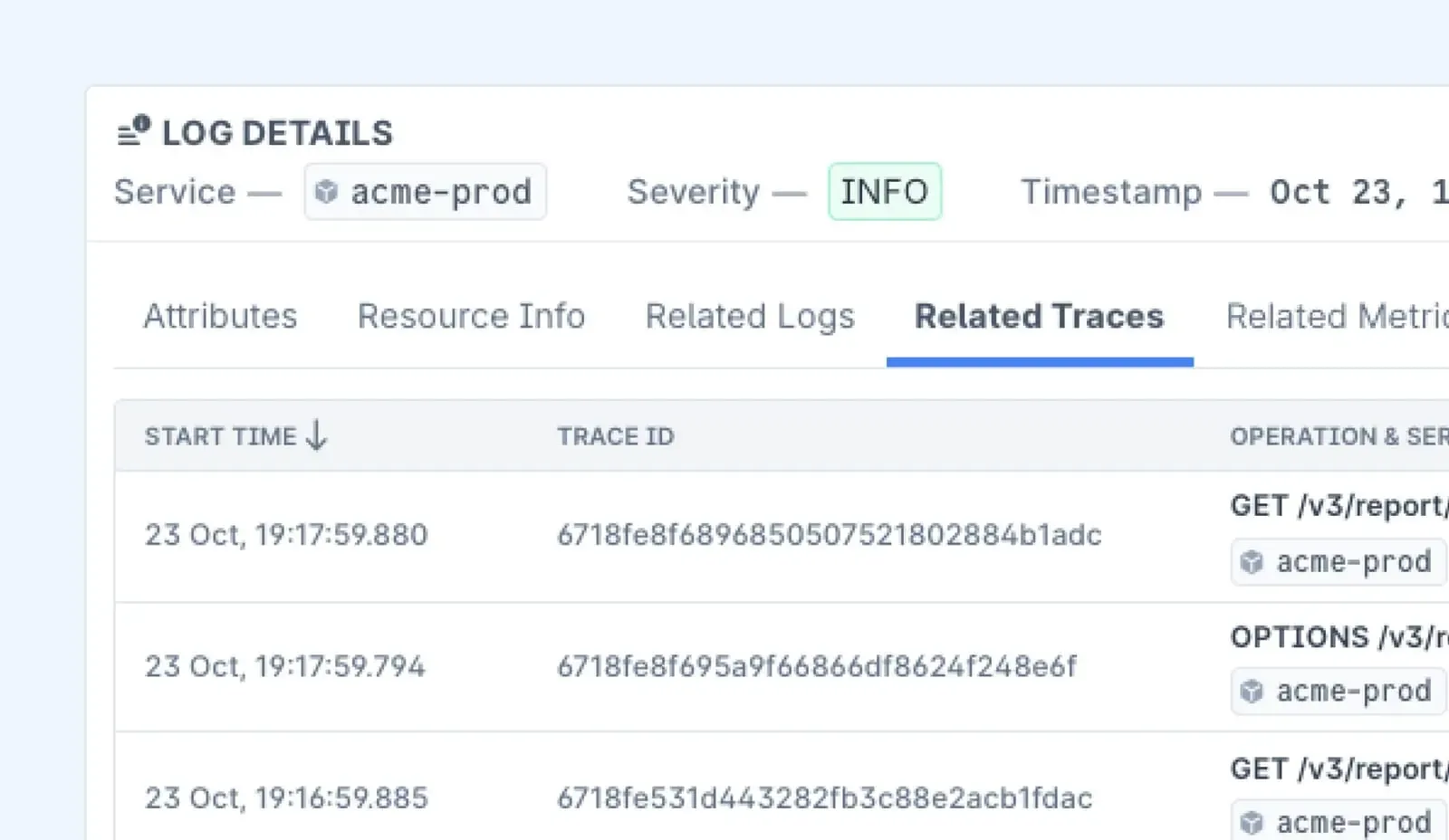
3. Advanced Monitoring with Prometheus and Grafana
For comprehensive monitoring, use Prometheus with Grafana dashboards. Install the Nginx Prometheus exporter:
nginx-prometheus-exporter -nginx.scrape-uri=http://localhost/nginx_statusConfigure Prometheus to scrape the metrics and use Grafana to visualize them.
4. Full Observability with OpenTelemetry (Otel)
OpenTelemetry enables distributed tracing and deeper insights into Nginx performance. Integrate Otel by installing the Otel Collector and configuring Nginx log ingestion.
5. Managed Monitoring Solutions
If you prefer an out-of-the-box solution, services like Last9, New Relic, and Datadog provide powerful dashboards and alerting capabilities.
For a detailed look at analyzing Nginx logs and extracting valuable insights, check out our guide on Nginx Log Monitoring.
How to Setup Alerts for Critical Nginx Events
It’s crucial to configure alerts for anomalies such as:
- High 5xx error rates.
- Unexpected traffic drops.
- Excessive response times.
- CPU or memory spikes.
For example, using Prometheus Alertmanager:
- alert: HighErrorRate expr: rate(nginx_http_requests_total{status=~"5.."}[5m]) > 0.05 for: 2m labels: severity: critical annotations: summary: "High Nginx error rate detected"How to Correlate Metrics with Logs
When an issue arises, logs provide context to understand the root cause, while metrics help detect anomalies before they escalate.
For example, if response time spikes suddenly, analyzing logs can reveal whether it’s due to an increase in request volume, slow upstream responses, or an application error.
Similarly, a rise in 5xx errors in logs may correspond with increased memory usage, indicating a potential resource exhaustion issue.
Steps to Correlate Metrics with Logs
- Identify Anomalies in Metrics: Use tools like Prometheus, Grafana, or Last9 to detect performance deviations.
- Pinpoint Relevant Logs: Use
grepor log analysis tools like the Last9, ELK stack to filter logs for timestamps matching the anomaly. - Analyze Patterns: Look for repeated errors, unusual spikes, or trends that coincide with metric fluctuations.
- Automate Correlation: Implement log aggregation platforms that automatically link metrics with log entries for faster debugging.
5 Best Tools for Nginx Monitoring
Choosing the right monitoring tool for Nginx depends on your infrastructure, budget, and specific observability needs.
Below is a detailed comparison of popular tools, starting with Last9, which offers deep observability and OpenTelemetry-native capabilities.
1. Last9
Overview: Last9 is an OpenTelemetry-native observability platform designed to provide deep insights into Nginx performance. It offers real-time monitoring, distributed tracing, and a scalable architecture suitable for enterprises.
Best Features:
- Native OpenTelemetry support for hassle-free integration.
- Scalable, real-time monitoring with low overhead.
- Advanced alerting that minimizes noise and prioritizes actionable insights.
- In-depth correlation between logs and metrics for faster troubleshooting.
Ideal For: Enterprises and teams looking for a scalable, high-performance monitoring solution with deep OpenTelemetry integration.
Pricing: Flexible pricing based on number of events ingested which makes pricing predictable for organizations.
2. Sematext
Overview: Sematext is a cloud-based monitoring and logging solution that provides full visibility into Nginx performance. It combines log management, metrics, and real-time alerts in one platform.
Best Features:
- Anomaly detection with automated alerts.
- Unified monitoring for logs and metrics.
- Intuitive dashboards with customizable visualization options.
Ideal For: Organizations that need an easy-to-use, all-in-one monitoring platform for both logs and metrics.
Pricing: Offers paid plans with a free trial available.
3. Prometheus & Grafana
Overview: Prometheus, coupled with Grafana, is a popular open-source monitoring stack widely used for collecting and visualizing Nginx metrics.
Best Features:
- Open-source and highly customizable.
- Strong community support and extensive documentation.
- Seamless integration with other open-source tools.
Ideal For: DevOps teams and organizations comfortable with self-hosted, customizable solutions.
Pricing: Free, but infrastructure costs may apply depending on setup and scaling.
4. New Relic
Overview: New Relic is a full-stack observability platform offering real-time monitoring, distributed tracing, and AI-driven insights for Nginx and other applications.
Best Features:
- AI-powered insights and automatic anomaly detection.
- Comprehensive application performance monitoring.
- Support for distributed tracing across services.
Ideal For: Large enterprises and SaaS companies requiring a sophisticated observability platform with AI-powered analytics.
Pricing: Free tier available; pricing scales based on data usage and additional features.
5. Datadog
Overview: Datadog is a cloud-based observability platform that provides log management, infrastructure monitoring, and APM for Nginx.
Best Features:
- Pre-built dashboards for Nginx monitoring.
- Unified logs, metrics, and traces in one platform.
- Native integrations with cloud services and Kubernetes.
Ideal For: Cloud-native businesses and teams that need an all-in-one observability platform with seamless integrations.
Pricing: Starts with a free tier; paid plans are based on usage.
If you’re considering Datadog for Nginx monitoring, check out our guide on Datadog Pricing to understand its costs and plans.
Conclusion
Logs play a crucial role in ngnix monitoring, providing the necessary context to troubleshoot anomalies and correlate events with system performance. A combination of real-time metrics, log analysis, and automated alerts ensures that potential issues are detected and resolved before they impact users.
Choosing the right monitoring tools—like Last9 or Prometheus & Grafana —depends on your infrastructure and observability needs.
However, regardless of the tool, a structured approach to monitoring, with well-configured alerts and dashboards, is key to maintaining a highly available and performant Nginx deployment.
And if you ever want to explore a discussion further, join our Discord community! We have a dedicated channel where you can connect with other developers and talk about your specific use case.
FAQs
How do I check if Nginx is running?
Run:
systemctl status nginxOr:
ps aux | grep nginxWhat’s the best way to analyze Nginx logs?
Use tools like Last9, AWStats, or the ELK stack (Elasticsearch, Logstash, Kibana) for detailed insights.
Why is my Nginx server slow?
Check CPU usage, memory, upstream response times, and request rates. Optimizations like caching and load balancing may be needed.
3. How do I monitor Nginx in real-time?
You can use the following tools:
ngxtopto monitor requests and responses live.tail -f /var/log/nginx/access.logto see real-time logs.watch -n 1 curl -s http://localhost/nginx_statusto check active connections and request rates.
4. How do I troubleshoot high CPU usage by Nginx?
- Run
toporhtopto check CPU usage. - Use
strace -p <nginx_pid>to inspect system calls. - Analyze logs to see if slow queries or high request loads are causing the issue.
- Optimize configurations, such as enabling caching and load balancing.
How can I reduce 502 Bad Gateway errors in Nginx?
- Check if the upstream server is running:
systemctl status php-fpm # If using PHP- Increase timeout values in
nginx.conf:
proxy_connect_timeout 60;proxy_send_timeout 60;proxy_read_timeout 60;- Verify firewall settings that may be blocking connections.
- Ensure sufficient resources (CPU, memory) on the upstream server.
How do I find and fix broken links in Nginx?
Use the following command to find 404 errors:
grep " 404 " /var/log/nginx/access.log | awk '{print $7}' | sort | uniq -c | sort -rnFix them by updating links, creating redirects, or handling errors with a custom page.

