
Launch Week Day 2: Introducing Discover Jobs
Your dashboard looks perfect. APIs responding in 80ms. Error rates at 0.02%. Kubernetes pods healthy. Everything’s green.
Then Slack explodes: “Why didn’t my invoice generate?” “Where’s my password reset email?” “The data export I requested yesterday is still processing?”
You check your job queue. Sidekiq dashboard shows 47,000 jobs processed today. Redis looks fine. Workers are running. But somehow, your business logic is silently falling apart.
Sound familiar?
Last9 helped us forget all the different observability tools and consolidate every dashboard into one single place. Everything is correlated and accessible in one place.
The Jobs That Run Your Business (While You’re Not Looking)
Here’s what’s actually happening in those background workers:
- Stripe webhooks processing subscription renewals
- Image resizing for user uploads
- Email campaigns to 100k+ subscribers
- Data exports that power customer BI dashboards
- ML model training on the latest user behavior data
- Third-party syncs keeping your CRM updated
When an API fails, you get an immediate 500. When a background job fails, you get a confused customer three days later asking why their report never arrived.
The brutal reality: Background jobs ARE your business logic. They just run where your monitoring can’t see them.
What Your Current Tools Actually Show You
Let’s be specific about what you’re missing:
- DataDog APM: Shows you that 12,847 jobs were “processed” yesterday. Doesn’t tell you that 340 of your payment processing jobs are timing out because a database query started taking 25 seconds after last week’s migration.
- New Relic: Gives you worker process metrics. Won’t show you that your email jobs are failing because the external SMTP API started rate-limiting your requests at 100/minute instead of 500/minute.
- Prometheus + Grafana: You can track job queue lengths and worker CPU usage. But when your image resizing jobs start failing for uploaded videos over 50MB, you’re debugging with
docker logsand prayer. - Your job queue’s dashboard (Sidekiq Web, Celery Flower, etc.): Shows basic success/failure counts. Doesn’t correlate failures with the specific database queries, API calls, or file operations that are actually breaking.
The common thread? They all treat background jobs as infrastructure that processes work, not as application logic that runs your business.
When Jobs Become First-Class Citizens
What if debugging a failing background job looked like debugging a failing API endpoint?
Instead of: “The email job failed. Let me check the logs… grep through 10,000 lines… oh, it’s a timeout somewhere in the sending logic… let me check the external service… maybe it’s a DNS issue?”
You get: “The email job’s P95 latency jumped from 200ms to 8 seconds. The bottleneck is the personalization API call – it’s returning 500s 15% of the time. Here’s the exact stack trace and the failing request details.”
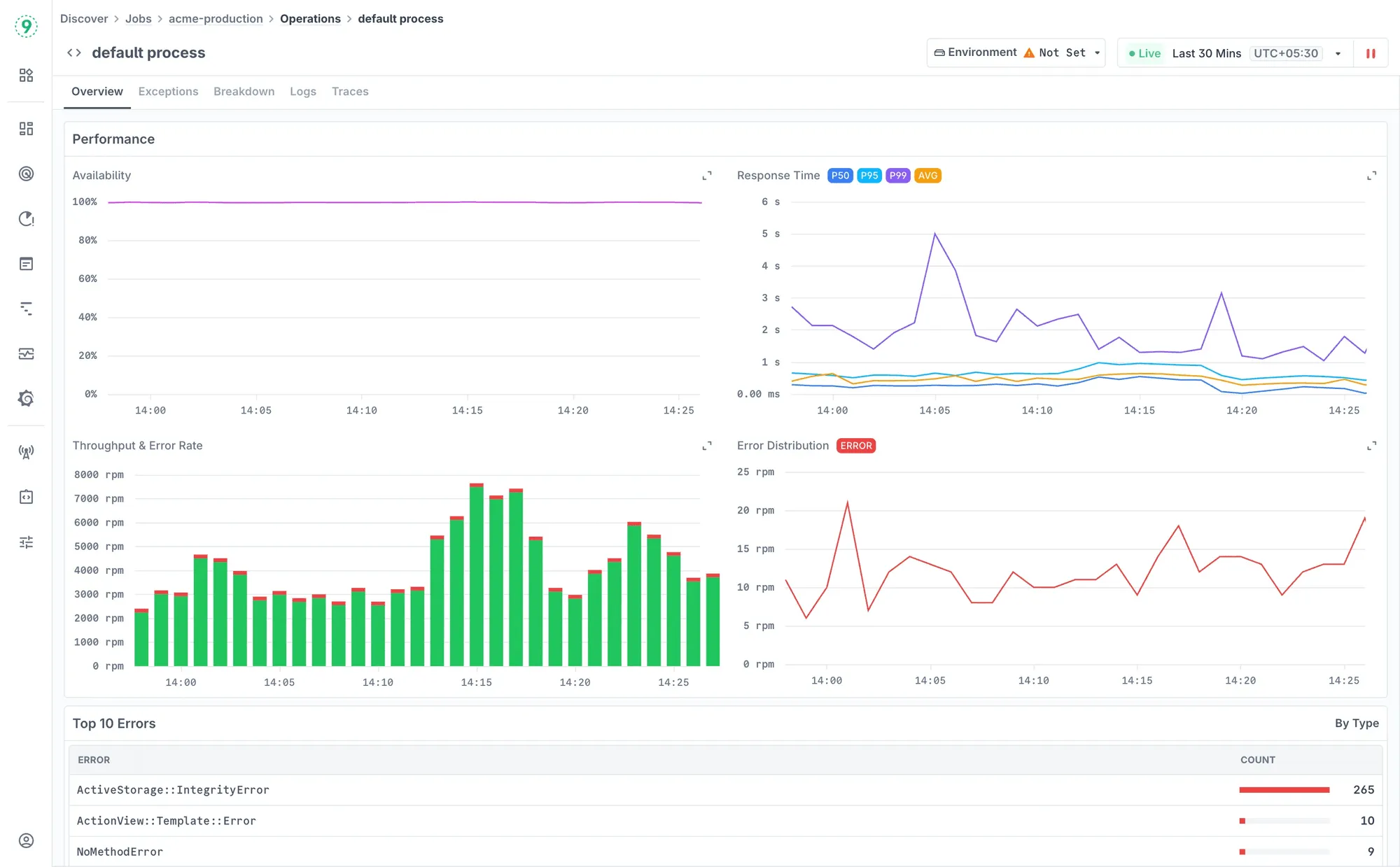
This is what Discover Jobs delivers: Operation-level visibility for background operations.
Real Debugging Scenarios
- Payment Processing Deep Dive: Your Stripe webhook processor is “working” but customers report failed charges. Discover Jobs shows you that the webhook job’s database query to update payment status has P95 latency of 12 seconds. The query is timing out, leaving payments in a pending state. You can see the exact SQL, the execution plan, and how it correlates with increased database load from another job running concurrently.
- Email Campaign Investigation: Marketing reports “emails are slow to deliver.” Instead of guessing, you see that your email worker’s external API calls to your email service provider have error rates of 23% due to rate limiting. The traces show exactly which API endpoints are failing and how the retries are backing up your queue.
- Data Pipeline Diagnosis: Your ETL job that processes user analytics “finished successfully” but downstream reports show missing data. Discover Jobs reveals that the job’s file processing operation silently skipped 15,000 records due to a schema validation error that wasn’t bubbling up to the job’s overall status.
How It Actually Works
Discover Jobs automatically detects background operations from your existing OpenTelemetry traces. No job registration. No YAML configs. No agents to install.
If you’re running:
- Sidekiq (Ruby) with tracing
- Celery (Python) with OpenTelemetry
- Bull/BullMQ (Node.js) with instrumentation
- Custom job workers that emit traces
You get:
- Performance monitoring for every job type with P50/P95/P99 latencies
- Error analysis showing which operations within jobs are failing
- Dependency mapping to see how job failures affect downstream services
- Resource correlation showing how infrastructure load impacts job performance
- Queue health metrics with backlog analysis and processing rate trends
“Last9 eliminates my need to juggle multiple observability tools by providing a single platform for logs, traces, and metrics,” says a Shailesh K in our G2 reviews. “I’m now uncovering problems that went completely unnoticed with my previous tools.”
The Setup (Actually Simple)
Prerequisites:
- OpenTelemetry traces from your job processing systems
- Optional: Application logs and infrastructure metrics for deeper context
That’s it. If your background jobs are already instrumented for tracing, they’ll show up in Discover Jobs with full performance monitoring automatically.
No separate job monitoring service to maintain. No queue-specific dashboards to configure. Your background operations get the same observability treatment as your HTTP APIs.
Why This Matters Right Now
Modern applications are increasingly async-first. Event-driven architectures. Microservices that communicate through job queues. Real-time features powered by background processing.
Yet most teams debug background jobs like it’s 2015-SSH into boxes, tail logs, and cross their fingers.
“Last9 helped us forget all the different observability tools and consolidate every dashboard into one single place,” says Rahul Mahale, Principal DevOps Engineer at Circle. “Everything is correlated and accessible in one place.”
Your background jobs deserve the same observability sophistication as your user-facing APIs. Because when they fail silently, your business fails loudly.
Ready to see what your background jobs are actually doing?
Start monitoring jobs (if you’re sending traces, they’re visible now) or see a demo with your specific stack.
This is Day 2 of Launch Week. Tomorrow: Infrastructure discovery, because your jobs and services need somewhere reliable to run.

