

A Levitate cluster is the backbone of our platform. Levitate cluster allows users to logically separate out their time series data based on environments, regions, data centers, or even business units.
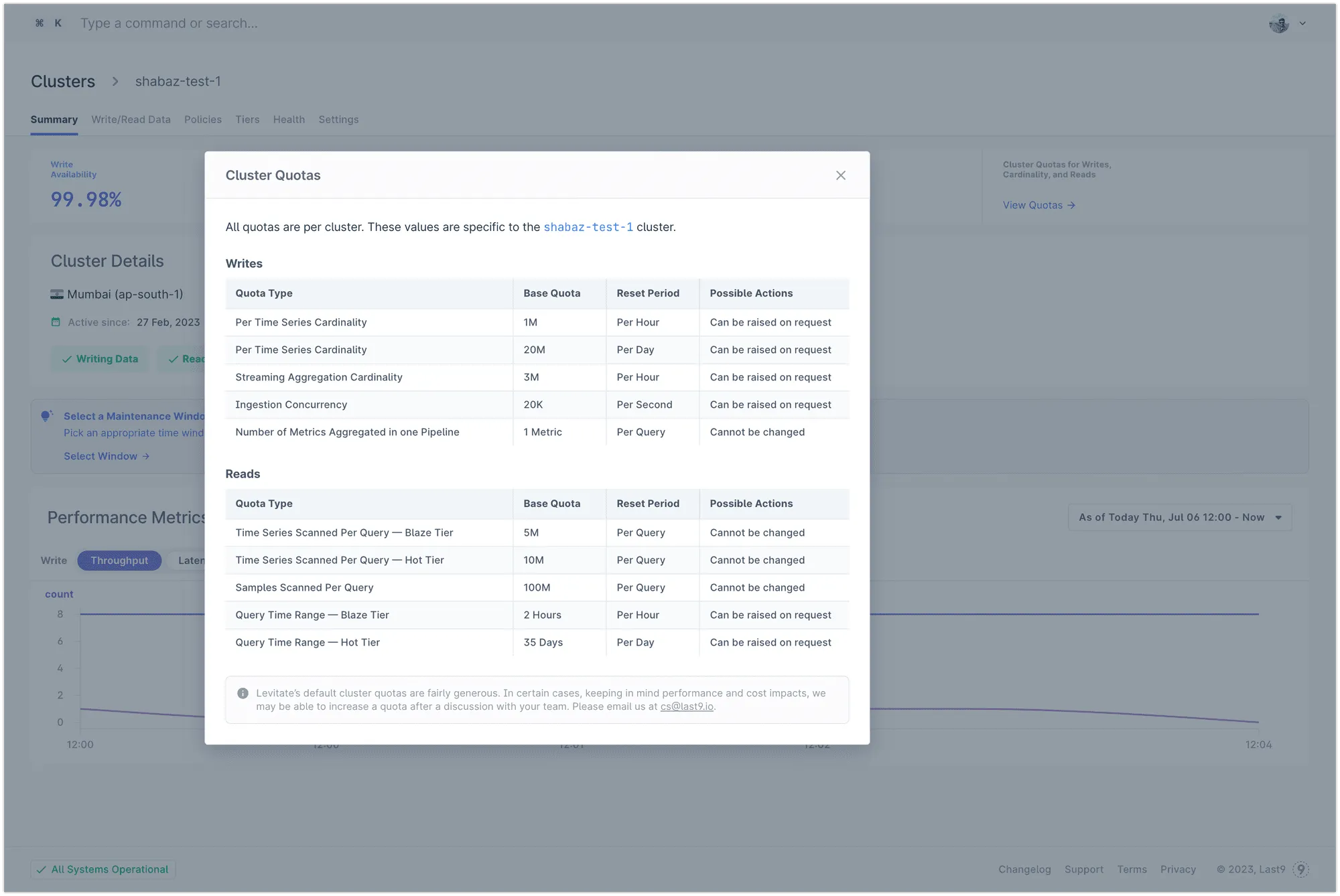
These quotas include cardinality limits and query limits for write and read workloads. Here is a detailed explanation for each.
Writes
- Per Time Series Cardinality - the number of unique time series allowed for ingestion. This setting is per metric and available per hour and day.
- Streaming Aggregation Cardinality - the number of unique time series allowed for ingestion for a streaming aggregation. You will notice that this number is thrice the number for metrics without streaming aggregation.
- Ingestion Concurrency - Number of write requests you can make per second.
- The number of metrics aggregated in one pipeline - this setting indicates that one streaming aggregation pipeline can aggregate only one metric and not more.
Reads
- Time Series scanned per query - Blaze Tier - Number of allowed time series scanned per query for Blaze tier. If this limit is crossed, you will get a 422 error. You can either improve the query or use a streaming aggregation to reduce the series scanned.
- Time Series scanned per query - Hot Tier - Number of allowed time series scanned per query for Hot tier. If this limit is crossed, you will get a 422 error. You can either improve the query or use a streaming aggregation to reduce the series scanned.
- Samples scanned per query - Number of allowed samples scanned per query. If this limit is crossed, you will get a 422 error. You can either improve the query or use a streaming aggregation to reduce the series scanned.
- Query Time Range — Blaze Tier - 2 hours. This denotes the time range for each query on Blaze Tier.
- Query Time Range - Hot Tier - 35 days. This denotes the time range for each query on Hot Tier. You can query for a maximum of 35 days of data at any point. As Hot Tier retains data for 6 months, you can query anywhere in those 6 months, but at max, you will get a range of 35 days of data per this setting.
💡
Levitate’s default quotas are extremely generous, but we also allow increasing the quota if you have a genuine use case for high cardinality. Contact us with the request at cs@last9.io, and we will make it happen.