

When we launched the support for streaming aggregations to tame high cardinality data, the workflow involved using a GitOps-based CI/CD pipeline.
The Last9 team will provide the GitHub repository with predefined CI/CD workflow for streaming aggregation.
The flow involves four easy steps.
- Define the streaming aggregations using PromQL in a per-cluster file.
- Send a pull request.
- Review and merge the pull request, and that's it. The streaming aggregation rule will be applied via the CI/CD pipeline.
- Explore the embedded Grafana within Last9 to verify the streaming aggregation has taken effect.
- Repeat!
While this flow is ideal for collaboration between different stakeholders and teams as the concerns for performing streaming aggregations can cut across different organizational departments considering the importance of high cardinality data concerning cost, business importance, and infrastructure, we also realized the need for a workflow via the Last9 dashboard itself to handle the streaming aggregation pipelines.
With today's release, the Streaming Aggregation Editor is available for each Last9 cluster. Just head over to your cluster, click on Settings and you will see the editor in action.
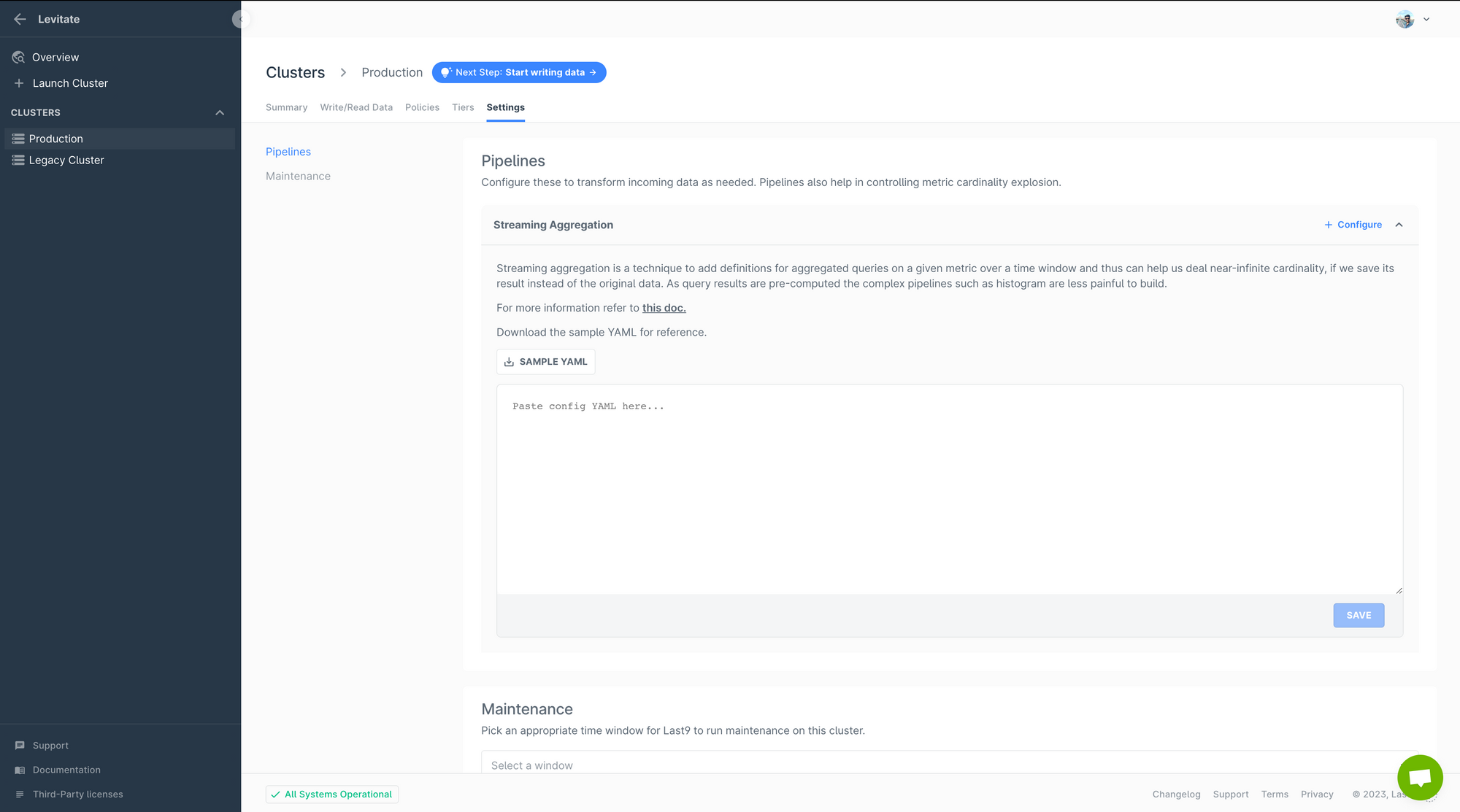
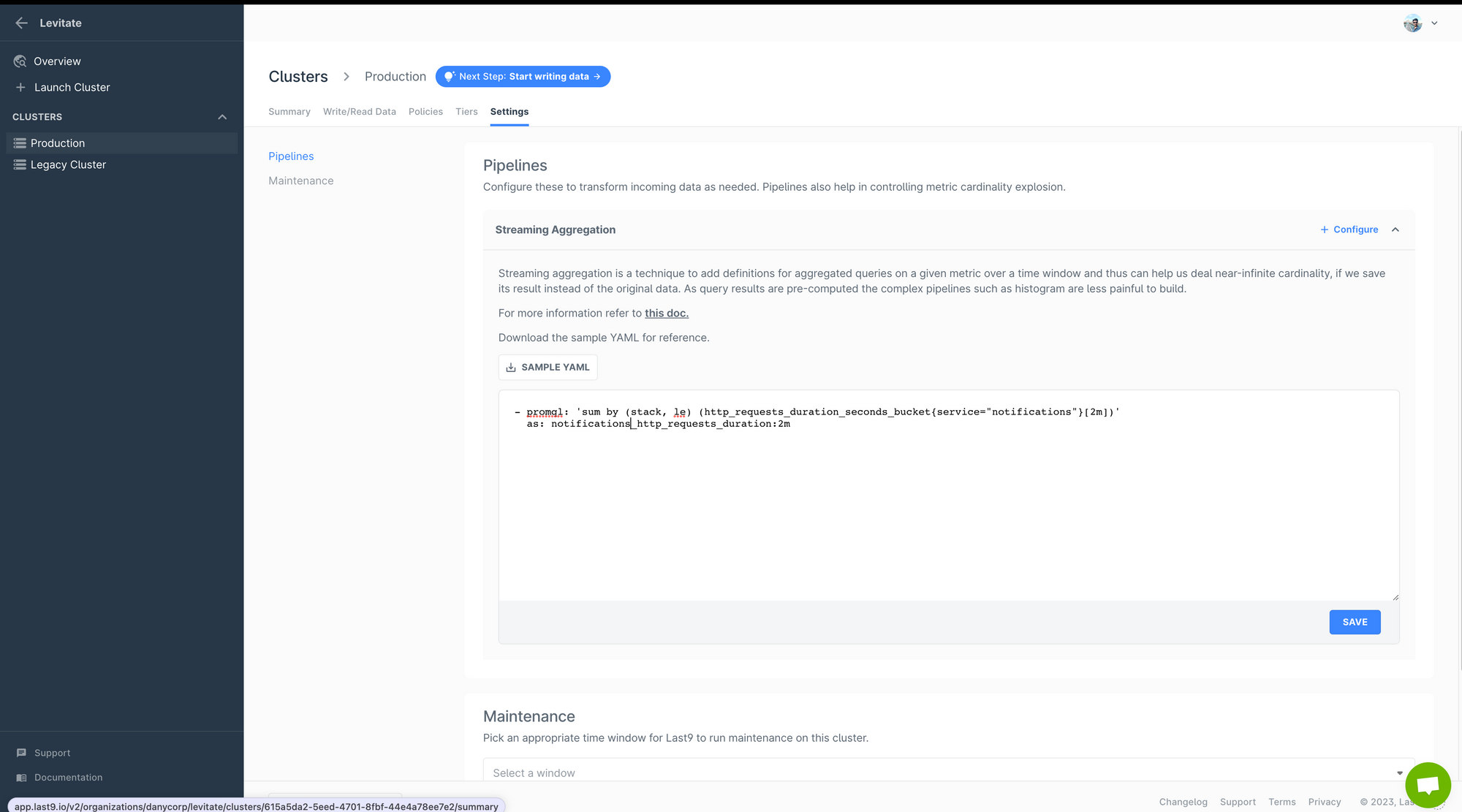
Everything else remains the same; refer to the following document to learn how to define streaming aggregations.

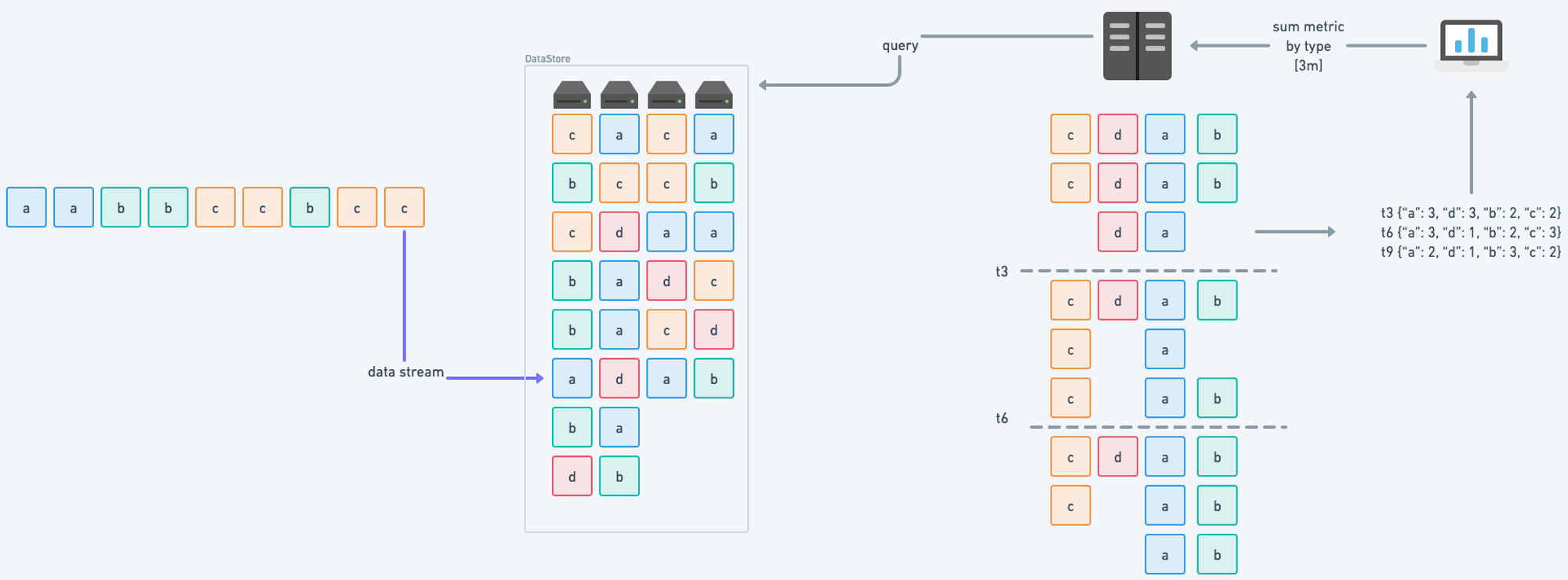
This release also has many performance improvements to make Last9 more stable and reliable as a managed time series data warehouse.