

As businesses scale, managing data and analytics becomes increasingly complex. Search workloads and performance optimization can demand significant resources.
Amazon OpenSearch Serverless offers a solution that simplifies operations, allowing for effortless scaling and optimized performance. But what sets it apart from other search and analytics tools? Let’s take a closer look.
What Is OpenSearch Serverless?
Amazon OpenSearch Serverless is a managed, serverless version of OpenSearch Service. It’s designed to handle high-volume search and analytics use cases without the hassle of provisioning or managing clusters.
Instead, the service automatically allocates resources based on demand, ensuring low-latency performance and uninterrupted operations.
Check out our guide on getting started with AWS WAF for more insights on setting up web application firewalls.
Why Choose OpenSearch Serverless?
1. Ease of Use
OpenSearch Serverless eliminates the complexity of managing clusters. Developers can use familiar open-source tools like Logstash and Fluentd to ingest data, making integration smooth and hassle-free.
2. Scalability
The serverless architecture dynamically scales up or down based on workload needs. Whether it’s a surge in traffic during holiday sales or quiet periods, OpenSearch Serverless adapts easily.
3. Cost Efficiency
Pay only for what you use. OpenSearch Serverless charges based on data ingestion and query execution, reducing the risk of over-provisioning resources.
4. Enhanced Performance
With automatic scaling and optimized resource allocation, the service ensures sub-second query responses even during high-demand periods.
Key Features of OpenSearch Serverless
1. Vector Search
OpenSearch Serverless supports vector search, which is crucial for AI-driven applications. This feature allows developers to store and search vector embeddings, making it easier to deliver accurate and relevant search results.
2. Automatic Scaling
Resource scaling is entirely automated, freeing teams to focus on building features instead of managing infrastructure.
3. Security
OpenSearch Serverless integrates with AWS Identity and Access Management (IAM), providing fine-grained access control and robust encryption to safeguard data.
4. Simplified Deployment
Developers can set up and deploy projects in minutes. The service supports multiple use cases, including log analytics, application monitoring, and real-time search applications.
For a deeper dive into automating workflows, check out our post on AWS Step Functions.
How Amazon OpenSearch Serverless Works
Amazon OpenSearch Serverless is designed to simplify the management of search and analytics workloads by eliminating the need to provision and manage infrastructure.
Here’s an in-depth look at how it works and what makes it tick:
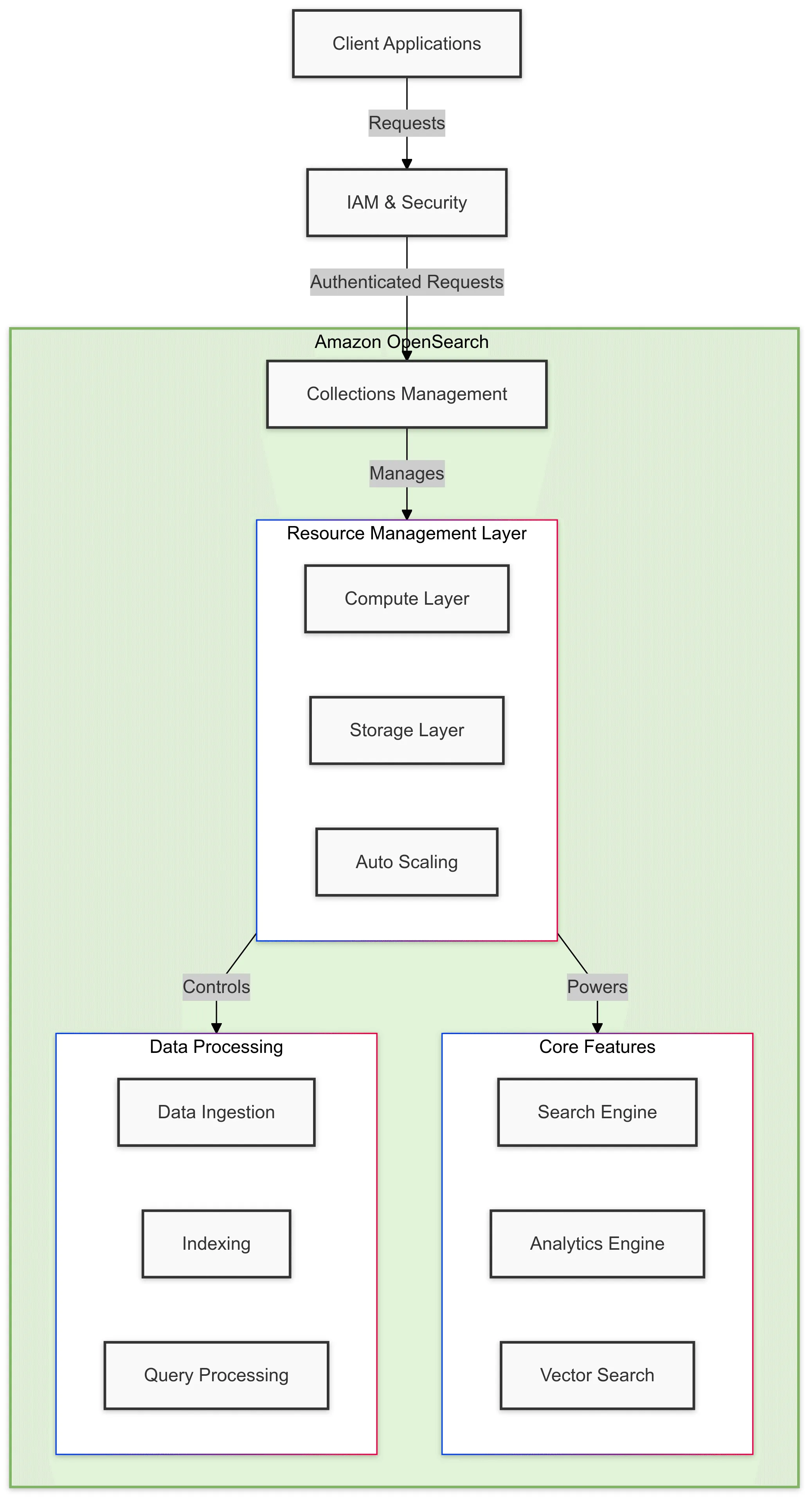
1. Serverless Architecture
At its core, OpenSearch Serverless operates on a serverless architecture. This means you don’t have to manage underlying infrastructure like servers or clusters.
Instead, AWS takes care of provisioning, scaling, and maintenance, allowing you to focus on your application.
- Dynamic Scaling: OpenSearch Serverless automatically allocates resources based on workload demands. Whether you’re handling a spike in traffic or a quiet period, it scales resources up or down to match your needs without manual intervention.
- Pay-as-You-Go: Billing is based on usage. You pay only for the compute and storage resources consumed, reducing costs and eliminating over-provisioning.
2. Collections as the Building Blocks
OpenSearch Serverless organizes workloads using collections, which are purpose-built environments for indexing and querying data. Each collection is optimized for a specific use case:
- Time Series Collections: Ideal for logs, metrics, and time-stamped data.
- Search Collections: Tailored for full-text search and analytics on structured or unstructured data.
Collections abstract away the complexity of traditional clusters while ensuring high availability and performance.
3. Separation of Compute and Storage
OpenSearch Serverless decouples computing and storage, ensuring better efficiency and scalability:
- Compute: Handles indexing, querying, and aggregation tasks. Resources are dynamically allocated to match the workload.
- Storage: Manages the underlying data using scalable and durable storage solutions. This separation allows computing resources to be optimized independently of storage needs.
4. Event-Driven Design
The serverless architecture relies on an event-driven model, which triggers compute resources only when there is work to be done:
- Data Ingestion Events: When data is ingested into a collection, the system triggers indexing processes to store and organize the data efficiently.
- Query Execution Events: When a search query is submitted, compute resources are spun up to execute the query and return results with minimal latency.
Explore more about monitoring your AWS environment in our post on AWS monitoring tools.
5. Automatic Resource Management
One of the standout features of OpenSearch Serverless is its ability to manage resources automatically:
- Provisioning: When a new collection is created, the system allocates the appropriate compute and storage resources.
- Scaling: As query or ingestion workloads increase, resources are scaled dynamically. This ensures consistent performance without manual adjustments.
- Idle Management: During low-activity periods, the system scales down resources to save costs, while still maintaining readiness for incoming workloads.
6. Security and Access Control
Amazon OpenSearch Serverless is built with security in mind, offering robust measures to protect your data:
- Encryption: Data is encrypted at rest and in transit using AWS Key Management Service (KMS).
- Fine-Grained Access Control: AWS Identity and Access Management (IAM) allows you to define precise permissions for accessing collections and data.
- Isolation: Collections are isolated from one another to ensure data integrity and security.
7. Built-in Features for Analytics and Search
OpenSearch Serverless includes features to enhance both search and analytics workloads:
- Vector Search: Supports AI-driven use cases like recommendation engines by indexing and searching vector embeddings.
- Domain-Specific Language (DSL): Enables advanced search capabilities with precise filtering, sorting, and aggregation.
- Dashboards and APIs: OpenSearch Dashboards provide visual exploration tools, while APIs allow integration with applications for programmatic access.
How It All Comes Together
Here’s a simplified flow of how OpenSearch Serverless operates:
- Data Ingestion: Use tools like Amazon Kinesis Data Firehose, Logstash, or Fluentd to feed data into your collection.
- Data Storage: The system indexes the data and stores it in a distributed and scalable storage layer.
- Query Execution: When a query is submitted, compute resources are dynamically allocated to process the request and return results in milliseconds.
- Scaling and Maintenance: Resources are automatically scaled and maintained by AWS, ensuring optimal performance and minimal downtime.
Learn how to track and monitor your AWS resources with our AWS CloudTrail guide.
How to Get Started with OpenSearch Serverless
If you’re looking to explore OpenSearch Serverless, here’s an easy guide to help you set things up and get going:
1. Sign in to the AWS Management Console
The journey begins by accessing the AWS Management Console:
- Log in to your AWS account at AWS Management Console.
- Navigate to the Amazon OpenSearch Service dashboard. If you’re new to the service, AWS provides a guided setup for first-time users.
- Ensure you have the necessary permissions to create and manage OpenSearch Serverless resources. AWS Identity and Access Management (IAM) roles and policies play a crucial role here.
2. Create a Collection
A collection is a foundational resource in OpenSearch Serverless. It groups your data and configurations to handle specific workloads like search or analytics.
Steps to Create a Collection:
- Go to the OpenSearch Serverless section in the Amazon OpenSearch Service dashboard.
- Click Create Collection.
- Choose the Collection Type:
- Time Series Collection: For log analytics, metrics monitoring, or event tracking.
- Search Collection: For e-commerce search, document indexing, or knowledge bases.
- Configure the collection:
- Assign a meaningful name to identify your collection.
- Define your workload settings, such as anticipated query volume or data ingestion rate.
- Review and confirm your settings.
Once created, the collection acts as a container for indexing and querying data.
3. Ingest Data
Now that your collection is ready, the next step is to populate it with data. OpenSearch Serverless supports various tools to ingest data efficiently.
Common Data Ingestion Tools:
- Amazon Kinesis Data Firehose: A fully managed service to stream real-time data into OpenSearch.
- Use it for high-speed, continuous data flows from applications, IoT devices, or logs.
- Logstash: A popular open-source tool for log and event data processing.
- Ideal for transforming and routing data from multiple sources into OpenSearch.
- Fluentd: Another open-source solution for data collection and transport.
- Best for lightweight data aggregation from distributed systems.
Steps to Ingest Data:
- Configure your ingestion pipeline in the tool of choice (e.g., set up a Kinesis Data Firehose delivery stream).
- Define the schema or mappings for your data in OpenSearch.
- Start streaming data into your collection. Verify the ingestion process via the OpenSearch dashboard to ensure data is arriving correctly.
For tips on reducing your AWS CloudWatch costs, check out our guide on cutting down CloudWatch expenses.
4. Run Queries
With data in your collection, it’s time to explore and extract insights using OpenSearch Dashboards or APIs.
Using OpenSearch Dashboards:
- Access OpenSearch Dashboards from the AWS Management Console.
- Connect to your serverless collection.
- Create visualizations:
- Use pie charts, histograms, or time-series graphs to interpret trends.
- Combine multiple visualizations into a single dashboard for an at-a-glance view of your data.
- Save and share dashboards with team members for collaborative analysis.
Querying via APIs:
If you prefer programmatic access:
- Use the OpenSearch REST API to execute search and analytics queries.
- Write queries using DSL (Domain-Specific Language) to filter, sort, and aggregate data.
- Integrate the API into your applications for dynamic, real-time data retrieval.
OpenSearch Serverless Collection Types
In OpenSearch Serverless, collections are the foundation for organizing and managing your search and analytics workloads.
Each collection is designed to handle specific use cases, ensuring optimal performance and efficiency. Here’s an overview of the primary collection types available:
1. Time Series Collections
Time series collections are tailored for workloads that involve timestamped data. These are ideal for scenarios where data needs to be ingested continuously and queried based on time-based patterns.
Common Use Cases:
- Log Analytics: Monitor application and infrastructure logs for patterns and anomalies.
- Metrics Monitoring: Track performance metrics across systems for real-time insights.
- Event Tracking: Capture and analyze events such as user activity or transactions.
Key Features:
- Optimized for high-volume, sequential data ingestion.
- Supports efficient time-based queries with low latency.
- Automatically manages older data, reducing storage overhead.
Discover the best tools for server monitoring in our guide on server monitoring tools.
2. Search Collections
Search collections focus on delivering fast, accurate, and relevant search results for use cases involving structured and unstructured data.
Common Use Cases:
- E-Commerce Search: Power search functionalities in online stores, delivering personalized results.
- Knowledge Bases: Enable users to search through documentation, FAQs, and support articles.
- Enterprise Search: Facilitate quick access to internal documents, emails, and other business-critical data.
Key Features:
- Built to handle diverse query patterns, including keyword, full-text, and vector-based searches.
- Integrates easily with AI-driven features like recommendation engines.
- Provides flexible indexing options to accommodate varying data structures.
Choosing the Right Collection Type
The choice between a time series and a search collection depends on your workload requirements.
If your primary focus is analyzing timestamped data over time, a time series collection is your best bet. For use cases where relevance and search accuracy are critical, a search collection offers the tools needed to deliver top-notch results.
Amazon OpenSearch Serverless vs. The OpenSearch Project
1. OpenSearch Project Overview
The OpenSearch project is an open-source, community-driven engine based on Apache Lucene and Elasticsearch, providing search, real-time analytics, and log management. It supports full-text search, powerful aggregations, and horizontal scalability across distributed nodes.
2. Amazon OpenSearch Serverless: The Managed Version
Amazon OpenSearch Serverless is a managed version of OpenSearch by AWS. It offers automatic scaling, cost optimization, and simplified management. Key features include:
- Serverless Architecture: No need to manage clusters or hardware.
- Auto-scaling: Dynamically adjusts resources based on demand.
- Pay-as-you-go Pricing: Charges are based on actual usage instead of fixed pricing.
3. Shared Core Functionality
Despite differences in architecture, OpenSearch Serverless retains the core functionalities of OpenSearch:
- Search Capabilities: Full-text search, complex queries, aggregations, and filters.
- OpenSearch APIs: Same RESTful APIs for integration.
- OpenSearch Dashboards: Works the same as with traditional OpenSearch clusters.
- Open-source Compatibility: Supports plugins, client libraries, and integrations from the OpenSearch ecosystem.
Learn how to boost your database performance with our guide to database optimization.
4. Benefits of OpenSearch Serverless
- Simplified Management: No need to handle provisioning, scaling, or hardware.
- Cost Efficiency: Pay only for resources used, reducing costs during low traffic.
- Elastic Scalability: Dynamically adjusts resources to match demand, ensuring optimal performance.
Conclusion
Amazon OpenSearch Serverless redefines the approach to search and analytics workloads. With its ease of use, scalability, and cost-efficiency, it empowers teams to innovate without the headache of infrastructure management.
If you’d like to discuss anything further, join our community on Discord. We have a dedicated channel where you can chat with other developers about your specific use case.
FAQs
What is OpenSearch Serverless?
OpenSearch Serverless is a managed, serverless version of the OpenSearch project that simplifies search and analytics workloads. It automatically scales resources based on demand, removing the need for manual management of clusters, and operates on a pay-as-you-go pricing model.
How does OpenSearch Serverless differ from traditional OpenSearch?
The main difference lies in the management and scaling. Traditional OpenSearch requires you to manually provision and scale clusters, while OpenSearch Serverless handles these tasks automatically. Additionally, OpenSearch Serverless uses a pay-per-use pricing model, whereas traditional OpenSearch clusters have a fixed pricing structure.
What are the key features of OpenSearch Serverless?
OpenSearch Serverless offers automatic scaling, cost optimization, and simplified management. It provides full-text search, and real-time analytics, and supports dynamic resource allocation based on workload demand.
Can I use OpenSearch Serverless for large-scale applications?
Yes, OpenSearch Serverless is designed to scale dynamically, making it suitable for large-scale applications like e-commerce sites, log analytics, and monitoring systems, where performance and scalability are crucial.
How does OpenSearch Serverless handle pricing?
OpenSearch Serverless uses a pay-as-you-go pricing model, meaning you only pay for the resources you use in terms of compute and storage, rather than a fixed monthly cost for a cluster.
Is OpenSearch Serverless compatible with OpenSearch APIs?
Yes, OpenSearch Serverless maintains full compatibility with the OpenSearch project, including RESTful APIs, which means you can interact with your data and integrate with other services just like you would in a traditional OpenSearch environment.
Can I use OpenSearch Dashboards with OpenSearch Serverless?
Yes, OpenSearch Dashboards work with OpenSearch Serverless the same way it does with traditional OpenSearch clusters, allowing you to visualize and explore your data without any changes to your workflow.
What types of workloads are best suited for OpenSearch Serverless?
OpenSearch Serverless is ideal for workloads that need elastic scalability, such as log analytics, metrics monitoring, event tracking, and large-scale search applications.
What are the advantages of OpenSearch Serverless?
The main advantages are simplified management, cost efficiency (only pay for what you use), and elastic scalability that adjusts to your workload demands. It reduces the complexity of managing infrastructure while maintaining the full capabilities of OpenSearch.

