

Recently, I posted on LinkedIn about what I’ve observed in terms of logging practices across different teams. The post resonated with many developers, sparking discussions and suggestions. So, I thought it would be worthwhile to expand on this topic and share my opinions in more detail.
As a developer who’s spent countless hours knee-deep in logs, trying to decipher the cryptic messages left by past me (or my well-meaning colleagues), I’ve come to appreciate the art of effective logging. It’s a journey from chaos to clarity, from frustration to insight. Let me take you through this journey, sharing what I’ve learned from working with various teams on the ground.
The Logging Spectrum
From “Log Anything” to “Log Everything”.
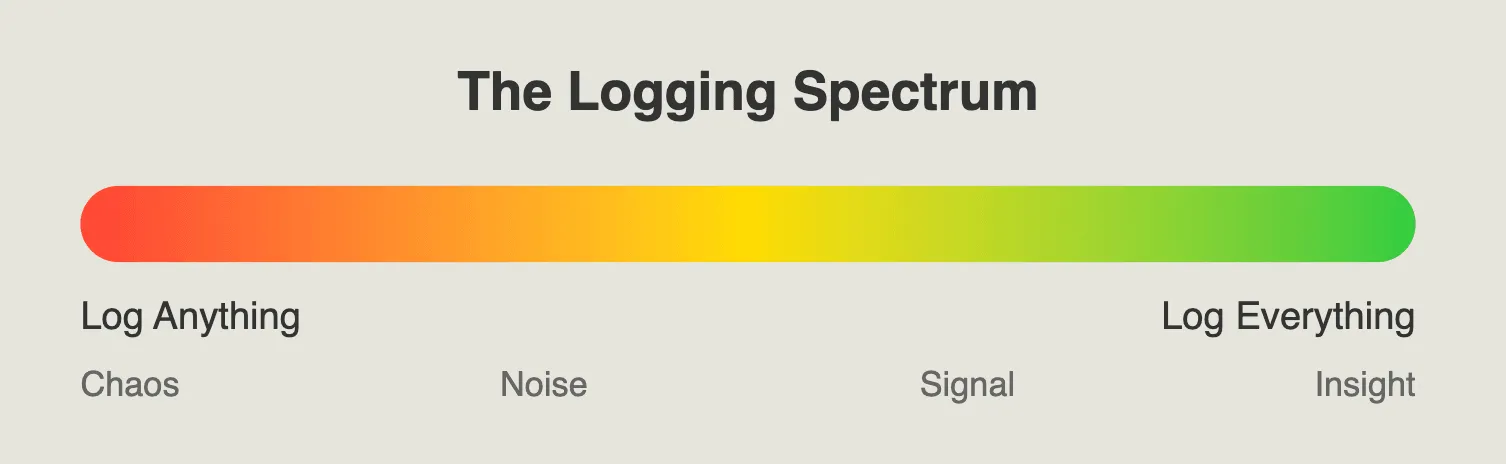
At one end, we have the “Log Anything” approach, and at the other, the “Log Everything” strategy. Let’s break these down and see why moving towards the right end of the spectrum can save you (and your future self) from countless headaches and the best way to reach there.
Log Anything: The Mystery Juice of Logging
We’ve all been there, especially in the heat of debugging a particularly nasty bug. It usually looks something like this:
console.log("here")print("Why isn't this working?!")logger.info("i = " + i)console.log("AAAAARGH!")An absolutely useful Python Logging Guide that shows how to do it right.
This approach is like a mystery juice – it might be helpful, it might be useless, but you won’t know until you’re desperately trying to debug an issue at 3 AM. Here’s why this approach falls short:
- Unstructured Chaos: Random
console.log()orprint()statements scattered throughout your code make it nearly impossible to parse or analyze logs systematically. - Contextless Noise: Logs like “here” or “AAAAARGH!” might have meant something to you when you wrote them, but good luck deciphering that during a production incident.
- Inconsistent Severity: When everything is logged at the same level, nothing stands out. It’s like trying to find a specific drop of water in a waterfall.
- Future You Will Curse Past You: Trust me, I’ve been there. You’ll be debugging an issue, come across these logs, and wonder what on earth you were thinking.
Log Everything: The Fine Wine of Logging
Don’t let the name fool you – it’s not about logging literally everything, but rather about logging thoughtfully and consistently. This is the fine wine of logging – complex yet clear, and it only gets better with time.
Here’s what “Log Everything” looks like in practice:
Structured, Consistent Logging look similar to
logger.info("User action", extra={ "user_id": user.id, "action": "login", "ip_address": request.ip, "timestamp": datetime.utcnow().isoformat()})Golang - its tricky to do this I know. I wrote a Golang logging guide for that very purpose. Its fun to run into your own blogpost when doing a google search
- High-Cardinality Data: Include relevant context that will help you understand the state of your system when the log was created.
- Events That Tell a Story: Log the journey of a request or a user action through your system.
- Thoughtful Severity Levels: Use appropriate log levels (DEBUG, INFO, WARNING, ERROR, CRITICAL) consistently across your services.
The Payoff: Why “Log Everything” Wins
- Faster Debugging: With contextual information readily available, you can quickly narrow down issues.
- Better Insights: Structured logs can be easily parsed and analyzed, giving you insights into system behavior over time.
- Proactive Problem Solving: With comprehensive logging, you can often spot issues before they become critical failures.
- Happier Future You: Trust me, you’ll thank yourself when you’re able to resolve issues quickly, even at 3 AM.
Implementing “Log Everything” in Your Project
- Use a Logging Framework: Utilize robust logging libraries like Python’s
loggingmodule, or more advanced options likestructlogfor Python orwinstonfor Node.js. - Define Log Levels: Establish clear guidelines for when to use each log level (DEBUG, INFO, WARNING, ERROR, CRITICAL).
- Structured Logging: Use JSON or another structured format for your logs. This makes them easy to parse and analyze.
- Include Context: Always include relevant contextual information like user IDs, request IDs, and timestamps.
- Log Life Cycles: Track the journey of important operations through your system.
- Use Log Aggregation Tools: Implement tools like Last9, Loki or Splunk to centralize and analyze your logs.
Last9 has a very nifty feature to turn your logs into a structured format at INGESTION instead of having to go back and changing instrumentation.
Striking the Right Balance
While the “Log Everything” approach is generally superior, it’s crucial to strike the right balance. Over-logging can lead to performance issues and make it harder to find relevant information. Here are some tips to find that sweet spot:
- Be Selective: Log important events and state changes, not every minor detail.
- Use Log Levels Wisely: Reserve ERROR for actual errors, use INFO for normal operations, and DEBUG for detailed information useful during development.
- Rotate and Retain: Implement log rotation and retention policies to manage storage and maintain performance.
- Sample High-Volume Events: For high-volume events, consider sampling a percentage of logs rather than logging every single occurrence.
- Leverage Feature Flags: Use feature flags to dynamically adjust logging verbosity in production when needed for troubleshooting.
- Log to Metrics: Using Last9’s streaming aggregations - you can turn logs into metrics at ingestion that allows for better control and alerting downstream
Conclusion
Remember, the goal isn’t to drown in data but to create a clear, structured narrative of your system’s behavior. By moving from “Log Anything” to “Log Everything,” you’re not just helping the future; you’re creating a more observable, debuggable, and ultimately more reliable system.
So, the next time you’re tempted to throw in a quick console.log("here"), take a moment to think about what future you at 3 AM might need to know. Your future self will thank you, and you might just find that debugging becomes less of a dreaded chore and more of an insightful journey through your application’s story.
Happy logging, and may your debugging sessions be short and your insights be plentiful!

