

If your Linux system is acting up and you have no idea why, logs can tell you what went wrong. This guide covers the key logs to check and how to use them to fix issues—whether you're running a personal setup or managing servers.
What Are Linux Event Logs?
Linux event logs are records of system activities, errors, warnings, and informational messages generated by the Linux kernel, applications, and services. Think of them as your system's diary – they note everything that happens behind the scenes.
These logs give you the full picture of what's happening on your system, making them invaluable for:
- Tracking down system issues
- Monitoring security concerns
- Understanding application behavior
- Identifying performance bottlenecks
Each log entry typically contains:
- Timestamp: When the event occurred
- Hostname: Which system generated the event
- Application/service name: What generated the event
- Process ID (PID): Which process wrote the log
- Message: The actual event details
Where to Find Linux Event Logs
The most comprehensive list of events in Linux is typically found in /var/log/syslog (on Debian-based systems like Ubuntu) or /var/log/messages (on Red Hat-based systems like CentOS).
These files contain almost everything happening on your system.
But Linux doesn't put all its eggs in one basket. Here's where different types of events are logged:
| Log File | What It Contains | Usefulness |
|---|---|---|
/var/log/syslog or /var/log/messages |
General system events | Your go-to for most troubleshooting |
/var/log/auth.log or /var/log/secure |
Authentication attempts | Perfect for security monitoring |
/var/log/kern.log |
Kernel messages | Great for hardware and driver issues |
/var/log/dmesg |
Boot-time messages | Helpful for startup problems |
/var/log/apache2/ or /var/log/httpd/ |
Web server activity | Web service troubleshooting |
/var/log/mysql/ |
Database server logs | MySQL/MariaDB issues |
/var/log/apt/ |
Package management | Installation and update tracking |
/var/log/cron |
Scheduled task logs | Cron job debugging |
/var/log/boot.log |
System boot logs | Boot sequence issues |
/var/log/faillog |
Failed login attempts | Security auditing |
Understanding Log Directory Structure
The /var/log directory follows a logical organization:
- System-wide logs in the main directory
- Application-specific logs in subdirectories
- Rotated logs with extensions (.1, .2.gz, etc.)
Running ls -la /var/log shows you all available logs, including hidden ones.
The Linux Logging Architecture
Linux uses a layered approach to logging:
- Applications generate log messages
- Logging libraries (like libsyslog) format these messages
- Logging daemons (like rsyslog or syslog-ng) route them
- Storage backends save them to files, databases, or remote servers
Traditional Syslog vs. Systemd Journal
Modern Linux distributions use one of two main logging systems:
Traditional Syslog:
- Text-based log files
- Managed by rsyslog or syslog-ng daemons
- Configurable via
/etc/rsyslog.confor/etc/syslog-ng/syslog-ng.conf - Logs are stored as plain text files in
/var/log/
Systemd Journal:
- Binary structured logs
- Managed by systemd-journald
- Configurable via
/etc/systemd/journald.conf - Logs stored in
/var/log/journal/in binary format - Accessed via the
journalctlcommand
Many systems use both simultaneously, with journald feeding events to rsyslog.
Essential Commands for Viewing Linux Events
You don't need fancy tools to get started. These commands will help you navigate logs like a pro:
The journalctl Command
If your system uses systemd (most modern distros do), journalctl is your Swiss Army knife:
# View all logs
journalctl
# See logs for today
journalctl --since today
# Follow logs in real-time (like tail -f)
journalctl -f
# View logs for a specific service
journalctl -u apache2
# View logs from a specific time range
journalctl --since "2023-10-15 10:00:00" --until "2023-10-15 11:00:00"
# View logs from a specific executable
journalctl /usr/bin/sshd
# View logs for a specific PID
journalctl _PID=1234
# View logs for a specific user
journalctl _UID=1000
# View kernel messages only
journalctl -kClassic Log Commands
For traditional syslog systems or specific log files:
# View the last 50 lines of syslog
tail -n 50 /var/log/syslog
# Watch logs in real-time
tail -f /var/log/syslog
# Search for error messages
grep "error" /var/log/syslog
# Search case-insensitive across all logs
grep -i "failed" /var/log/auth.log
# View logs with context (3 lines before and after)
grep -A 3 -B 3 "critical" /var/log/syslog
# Count occurrences of specific events
grep -c "authentication failure" /var/log/auth.log
# Use less for easy navigation of large log files
less /var/log/syslogAdvanced Log Analysis with awk and sed
For more complex log analysis:
# Extract IP addresses from auth logs
awk '/Failed password/ {print $11}' /var/log/auth.log | sort | uniq -c | sort -nr
# Filter Apache logs by HTTP status code
awk '$9 == 404 {print $7}' /var/log/apache2/access.log | sort | uniq -c | sort -nr
# Extract timestamp and error message only
sed -n 's/.*\([0-9]\{2\}:[0-9]\{2\}:[0-9]\{2\}\).*error: \(.*\)/\1 \2/p' /var/log/syslogUnderstanding Log Priorities
Linux logs aren't just random notes – they're organized by severity. Understanding these priorities helps you filter the signal from the noise:
| Priority | Name | Meaning | Example |
|---|---|---|---|
| 0 | emerg | System is unusable – panic mode | Kernel panic, hardware failure |
| 1 | alert | Action must be taken immediately | Corruption of system database |
| 2 | crit | Critical conditions | Hard disk errors |
| 3 | err | Error conditions | Application crashes |
| 4 | warning | Warning conditions | Configuration issues |
| 5 | notice | Normal but significant conditions | Service starts/stops |
| 6 | info | Informational messages | Regular operation events |
| 7 | debug | Debug-level messages | Verbose development info |
Use these with journalctl to filter by severity:
# Show only errors and above
journalctl -p err
# Show warnings and above
journalctl -p warning
# Count events by priority
for i in emerg alert crit err warning notice info debug; do
echo -n "$i: "
journalctl -p $i --since today | grep -v "-- Journal" | wc -l
doneCustomizing Your Event Logging
The default logging settings work for most cases, but sometimes you need more detail or want to keep logs longer.
Configuring rsyslog
The rsyslog configuration lives in /etc/rsyslog.conf and /etc/rsyslog.d/*.conf:
# Log all kernel messages to kern.log
kern.* /var/log/kern.log
# Log authentication messages to auth.log
auth,authpriv.* /var/log/auth.log
# Log all cron jobs to cron.log
cron.* /var/log/cron.log
# Save debug messages to debug.log
*.=debug /var/log/debug
# Send critical messages to all logged-in users
*.emerg :omusrmsg:*To modify these rules:
- Edit the appropriate config file
- Use the format:
facility.priority destination - Restart rsyslog:
sudo systemctl restart rsyslog
Adjusting Log Rotation
Log files can grow massive if left unchecked. The logrotate utility handles this automatically:
# View current logrotate config
cat /etc/logrotate.conf
# Check config for a specific service
cat /etc/logrotate.d/apache2A typical config might look like:
/var/log/syslog {
rotate 7
daily
compress
delaycompress
missingok
notifempty
postrotate
/usr/lib/rsyslog/rsyslog-rotate
endscript
}This rotates logs daily, keeps 7 days of history, and compresses older logs.
To create a custom rotation policy:
- Create a new file in
/etc/logrotate.d/ - Specify the log file path and options
- Set rotation frequency (daily, weekly, monthly)
- Define how many old logs to keep
- Add any pre/post scripts for handling services
Setting Up Remote Logging
For multi-server setups or critical systems, consider sending logs to a central server:
Server Configuration (rsyslog)
# Enable TCP and UDP reception
module(load="imudp")
input(type="imudp" port="514")
module(load="imtcp")
input(type="imtcp" port="514")
# Create template for remote logs
template(name="RemoteLogs" type="string" string="/var/log/remote/%HOSTNAME%/%PROGRAMNAME%.log")
# Store remote logs based on hostname and program
if $fromhost-ip startswith '192.168.' then ?RemoteLogsClient Configuration (rsyslog)
# Send all logs to remote server
*.* @@192.168.1.100:514Use @ for UDP and @@ for TCP. TCP provides better reliability.
For secure transmission:
- Generate TLS certificates
- Configure rsyslog to use TLS/SSL
- Set up proper authentication
Advanced Event Monitoring Techniques
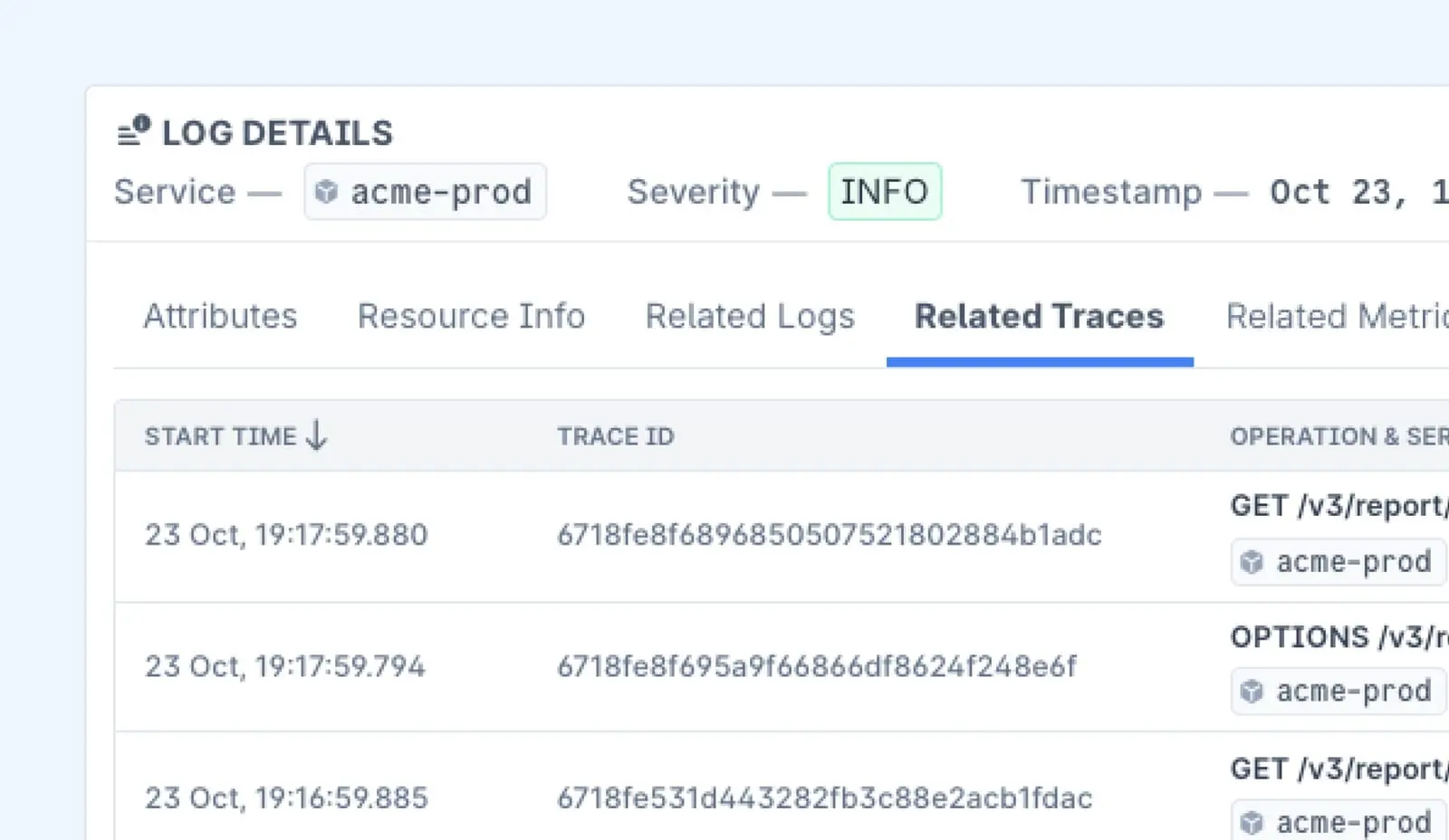
Using Last9 for High-Cardinality Observability
For teams dealing with high-scale event monitoring, Last9 provides a managed observability solution that simplifies log, metric, and trace correlation.
- High-cardinality observability: Easily analyze millions of unique data points without performance bottlenecks.
- Intelligent alerting: Reduce noise and get alerts that matter.
- Service dependencies mapping: Understand how changes in one system impact others.
- Historical comparisons: Quickly pinpoint performance degradations over time.
- Integration with OpenTelemetry & Prometheus: Unified monitoring across distributed systems.
Using the Elastic Stack (ELK)
For environments needing powerful search and visualization, the Elastic Stack provides a complete logging solution:
- Elasticsearch stores and indexes logs.
- Logstash processes and normalizes them.
- Kibana provides visualization dashboards.
- Beats (Filebeat, Metricbeat) collect and forward logs.
Basic setup:
- Install Elasticsearch and start the service.
- Install Kibana and connect it to Elasticsearch.
- Install Filebeat on log sources.
- Configure Filebeat to collect specific logs.
- (Optional) Set up Logstash for advanced processing.
Filebeat configuration example:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/syslog
- /var/log/auth.log
fields:
server_type: production
environment: linux
output.elasticsearch:
hosts: ["elasticsearch:9200"]Using Prometheus and Grafana
For real-time metrics and event-driven alerts:
- Prometheus collects and stores time-series data.
- Node_exporter exposes system metrics.
- Grafana visualizes data and creates alerts.
Basic setup:
- Install Prometheus for metrics collection.
- Set up node_exporter to expose system metrics.
- Configure Prometheus to scrape these metrics.
- Install Grafana for visualization.
- Create dashboards and alerting rules.
Automated Alerting with Fail2ban
Fail2ban monitors logs for suspicious activity and takes action:
# Install fail2ban
sudo apt install fail2ban
# Check its status
sudo systemctl status fail2banExample jail configuration for SSH protection:
[sshd]
enabled = true
port = ssh
filter = sshd
logpath = /var/log/auth.log
maxretry = 5
bantime = 3600This setup:
- Monitors SSH login attempts in auth.log.
- Bans IPs after 5 failed attempts.
- Keeps the ban active for 1 hour.
Writing Custom Log Analyzers
For specialized needs, simple scripts can analyze logs efficiently:
#!/usr/bin/env python3
import re
import sys
error_pattern = re.compile(r'(\w{3} \d{2} \d{2}:\d{2}:\d{2}).*ERROR: (.*)')
with open('/var/log/application.log', 'r') as f:
for line in f:
match = error_pattern.search(line)
if match:
timestamp, message = match.groups()
print(f"{timestamp}: {message}")This script extracts error messages with timestamps from application logs, making troubleshooting easier.
Troubleshooting Common Linux Problems Using Events
Now for the practical stuff – let's see how logs help solve real problems.
Finding Failed Login Attempts
Security concerns? Check auth logs:
grep "Failed password" /var/log/auth.logWhat to look for:
- Repeated attempts from the same IP
- Attempts for non-existent users
- Attempts outside normal business hours
For a summary report:
grep "Failed password" /var/log/auth.log | \
awk '{print $11}' | sort | uniq -c | sort -nr | head -10This shows the top 10 IPs with failed login attempts.
Debugging Application Crashes
When an app keeps crashing:
journalctl -u nginx --since "10 minutes ago"Look for:
- Segmentation faults
- Out-of-memory errors
- Permission issues
- Missing dependencies
For systemd services that fail to start:
systemctl status application.service
journalctl -u application.service -n 50Pay attention to exit codes – they often point to specific issues:
- Exit code 1: General error
- Exit code 126: Command not executable
- Exit code 127: Command not found
- Exit code 137: Process killed (often OOM killer)
Identifying Disk Space Issues
Running out of space?
grep "No space left on device" /var/log/syslogFor a comprehensive disk space analysis:
# Find largest log files
find /var/log -type f -exec du -h {} \; | sort -hr | head -20
# Check if any logs are growing unusually fast
watch -n 1 'ls -la /var/log/*.log'
# See which processes are writing to logs
lsof | grep "/var/log"Resolving Network Connection Problems
For network issues:
# Check for dropped connections
grep "Connection reset by peer" /var/log/syslog
# Look for firewall blocks
grep "UFW BLOCK" /var/log/kern.log
# Check for DNS resolution problems
grep "resolv" /var/log/syslogFor deeper network debugging:
/var/log/networkmanagerfor NetworkManager logs- DHCP client logs in syslog
- VPN connection logs (OpenVPN, WireGuard)
Investigating Boot Problems
When your system won't boot properly:
# Check early boot logs
journalctl -b -1 -p err
# Look for filesystem check errors
grep "fsck" /var/log/boot.log
# Check for hardware detection issues
dmesg | grep -i errorThe key boot log locations:
journalctl -bfor systemd systems/var/log/boot.logfor traditional init systems/var/log/dmesgfor kernel boot messages
When to Look Beyond syslog
While syslog contains a comprehensive list of events, some applications maintain their own logs:
Database Servers
MySQL/MariaDB:
- Error log:
/var/log/mysql/error.log - Slow query log:
/var/log/mysql/mysql-slow.log - General query log:
/var/log/mysql/mysql.log
Key errors to watch for:
- Table corruption
- Connection issues
- Query timeouts
PostgreSQL:
- Main log:
/var/log/postgresql/postgresql-X.Y-main.log - Various levels configurable in
postgresql.conf
Web Servers
Apache:
- Access log:
/var/log/apache2/access.log - Error log:
/var/log/apache2/error.log - Custom vhost logs as configured
Useful Apache log analysis:
# Count status codes
awk '{print $9}' /var/log/apache2/access.log | sort | uniq -c | sort -nr
# Top 10 requested URLs
awk '{print $7}' /var/log/apache2/access.log | sort | uniq -c | sort -nr | head -10
# Top 10 clients
awk '{print $1}' /var/log/apache2/access.log | sort | uniq -c | sort -nr | head -10Nginx:
- Access log:
/var/log/nginx/access.log - Error log:
/var/log/nginx/error.log
Container Platforms
Docker:
- Container logs:
docker logs container_name - Docker daemon:
journalctl -u docker.service
Kubernetes:
- Pod logs:
kubectl logs pod_name - Node logs: typically in journald
- Control plane logs: in
/var/log/kube-*or as containers
Mail Servers
Postfix:
- Mail log:
/var/log/mail.log - Mail errors:
/var/log/mail.err
Common mail server issues:
- SMTP authentication failures
- Delivery failures
- Spam filtering issues
Advanced Log Analysis Tools
Last9
For teams needing deep log analysis, Last9 offers a powerful telemetry data platform that unifies logs, metrics, and traces.
Unlike traditional tools that focus solely on log parsing, Last9 correlates observability data at scale, helping teams detect anomalies, troubleshoot faster, and optimize system performance.
With integrations like OpenTelemetry and Prometheus, Last9 provides a structured approach to log analysis, ensuring that businesses maintain high availability and reliability.
GoAccess
A real-time web log analyzer that provides insights through terminal-based dashboards and HTML reports.
Commands:
# Terminal dashboard for Apache logs
goaccess /var/log/apache2/access.log -c
# Generate HTML report
goaccess /var/log/apache2/access.log --log-format=COMBINED -o report.htmlLnav (Log File Navigator)
Lnav offers an interactive way to analyze multiple log files in one unified view.
Commands:
# Open multiple logs at once
lnav /var/log/syslog /var/log/auth.log /var/log/apache2/error.log
# Press '?' for help in the interactive interfaceLogwatch
An automated log analysis and reporting tool that summarizes logs and provides daily reports.
Commands:
# Install logwatch
sudo apt install logwatch
# Generate a report for yesterday
sudo logwatch --detail high --range yesterday --output stdoutWhile tools like GoAccess, Lnav, and Logwatch help with specific logging scenarios, Last9 provides a more holistic view of system behavior, making it a preferred choice for modern observability strategies.
Best Practices for Linux Event Management
Follow these tips to keep your logging system useful:
- Set up log rotation to prevent disk space issues
- Configure based on size and time
- Consider compression for archives
- Set appropriate retention periods
- Use timestamps in a consistent format across all servers
- Preferably ISO 8601 format (YYYY-MM-DD HH:MM:SS)
- Include timezone information
- Consider using UTC for multi-region setups
- Include hostname in logs for multi-server environments
- Essential for centralized logging
- Helps trace issues across services
- Consider adding the application name and version
- Configure appropriate log levels – too verbose is as bad as too quiet
- Use DEBUG only temporarily
- Keep INFO for normal operations
- Make sure ERROR and CRITICAL are always logged
- Back up important logs regularly
- Include logs in the backup strategy
- Consider longer retention for security logs
- Keep audit logs for compliance requirements
- Implement log security measures
- Set proper permissions (typically 640 or 600)
- Use dedicated log user accounts
- Consider log signing for tamper evidence
- Establish log monitoring and alerting
- Alert on critical errors
- Set up trend monitoring
- Create dashboards for visibility
- Document your logging architecture
- Map all log sources
- Document retention policies
- Create troubleshooting guides
Conclusion
Linux's logging system gives you a powerful window into what's happening on your system. The comprehensive list of events in these logs, especially in syslog or journald, provides the insights you need to solve problems fast.

