


How to Run Elasticsearch on Kubernetes
Anjali Udasi

11 Best Log Monitoring Tools for Developers in 2025
Anjali Udasi

Grafana Tempo vs Jaeger: Key Features, Differences, and When to Use Each
Anjali Udasi

Top 11 Application Logging Tools for DevOps Engineers in 2025
Faiz Shaikh

Top 7 Microservices Monitoring Tools to Consider in 2025
Anjali Udasi

Getting Started with Bun.js: A Quick Guide
Prathamesh Sonpatki

Cloudcraft: A Simple Tool for Cloud Architecture Design
Anjali Udasi

7 Best DigitalOcean Alternatives for Developers in 2025
Anjali Udasi

gRPC vs HTTP vs REST: Which is Right for Your Application?
Anjali Udasi

Top 7 Cloud Providers: The Best AWS Alternatives
Anjali Udasi

Splunk vs. Datadog: A Side-by-Side Comparison
Anjali Udasi

Top 5 Firebase Alternatives for 2024: Best Picks
Anjali Udasi

The Best Heroku Alternatives for Developers in 2024
Anjali Udasi

The Best Linux Monitoring Tools for 2024
Anjali Udasi

Datadog vs Dynatrace: A Comprehensive Comparison
Anjali Udasi

Fluentd vs Fluent Bit – A Comprehensive Overview
Prathamesh Sonpatki, Anjali Udasi

Top 5 Open Source SIEM Tools for Security Monitoring
Anjali Udasi

Filebeat vs Logstash: Key Differences for Your Logging Needs
Anjali Udasi

Kibana vs Grafana: Key Differences and Use Cases
Anjali Udasi

Extracting Account-Level CDN Metrics from Akamai Logs with Last9
Prathamesh Sonpatki, Aditya Godbole

AWS Monitoring Tools to Optimize Cloud Performance
Anjali Udasi

OpenSearch vs. Elasticsearch: What’s the Real Difference?
Anjali Udasi

Datadog vs. Grafana: Finding Your Ideal Monitoring Tool
Anjali Udasi

9 Datadog Alternatives Worth Considering in 2025
Anjali Udasi

Top 10 Platform Engineering Tools in 2024
Prathamesh Sonpatki

A Deep Dive into Log Aggregation Tools
Anjali Udasi

What do self-driving cars tell us about Site Reliability Engineering?
Mohan Dutt Parashar

Understanding “Cricket Scale”
Aniket Rao

Reliability Engineering for Dummies: ELI5
Mohan Dutt Parashar
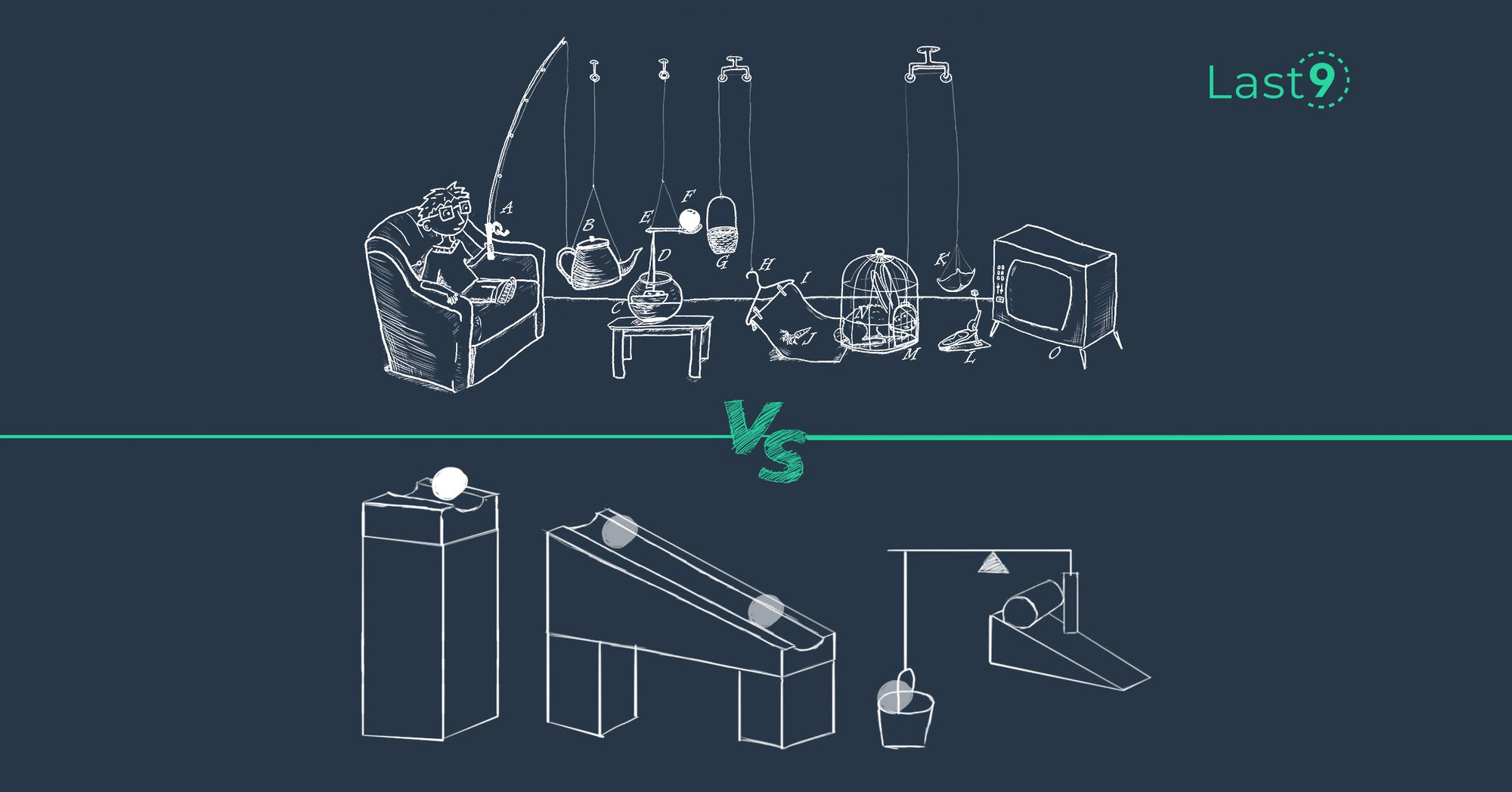
Self-managed Prometheus vs Managed Prometheus
Last9
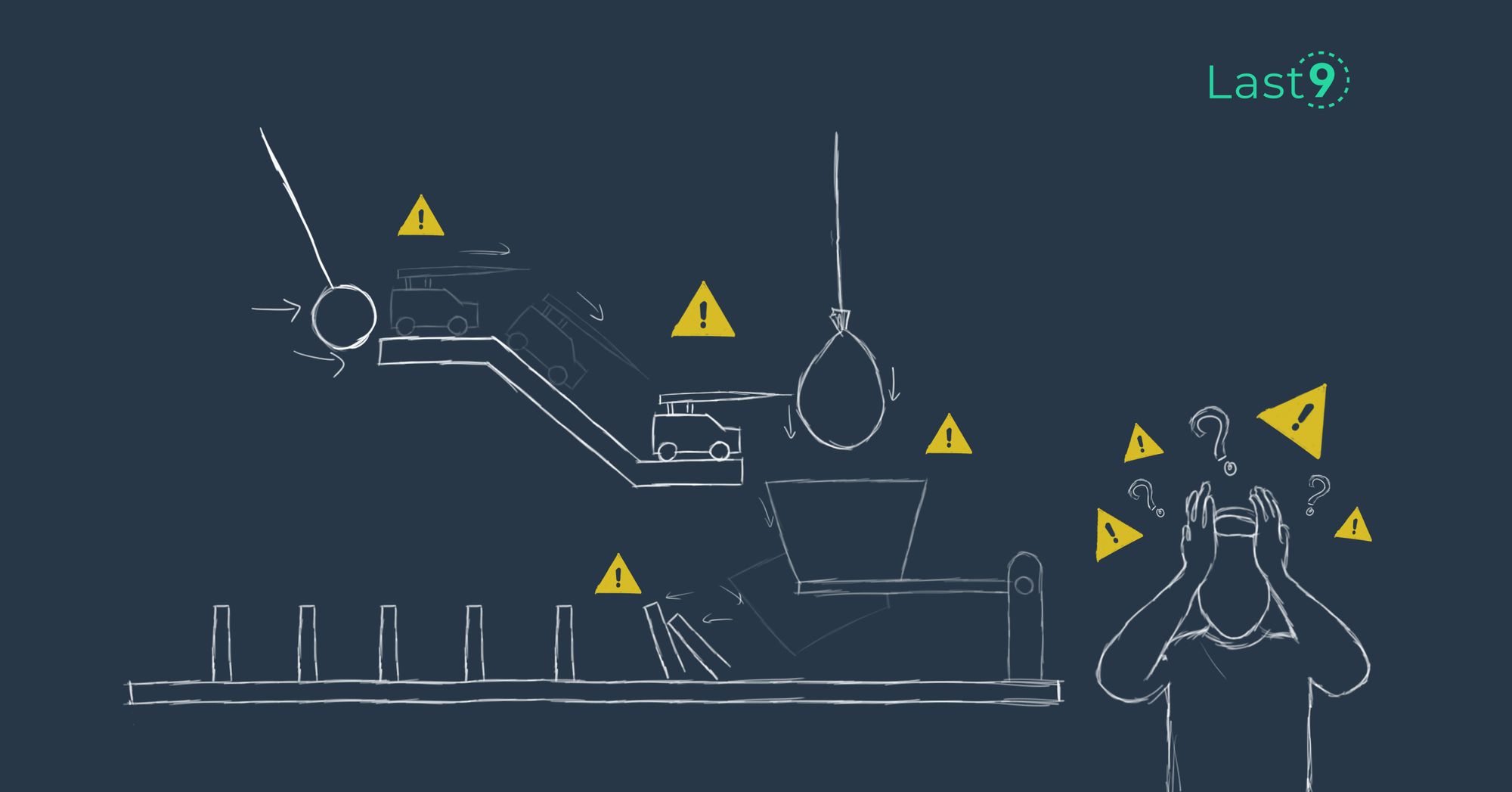
Battling Alert Fatigue
Last9
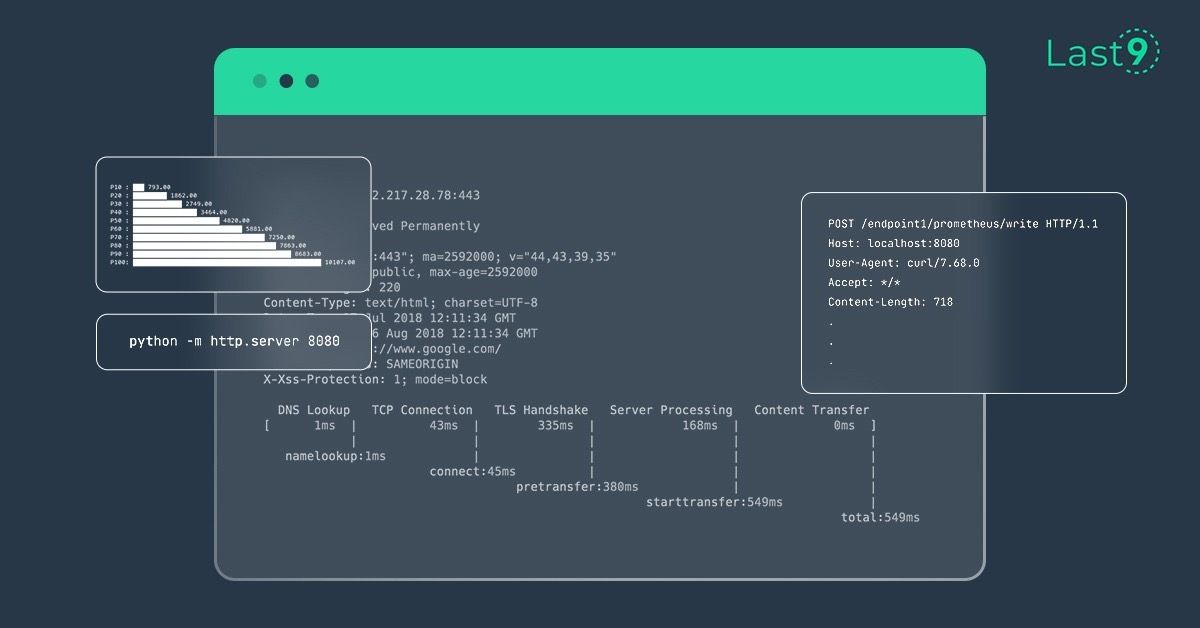
How to calculate HTTP content-length metrics on cli
Saurabh Hirani

We’ve raised a $11M Series A led by Sequoia Capital India!
Nishant Modak

The origin of Service Level Objectives
Akshay Chugh, Piyush Verma
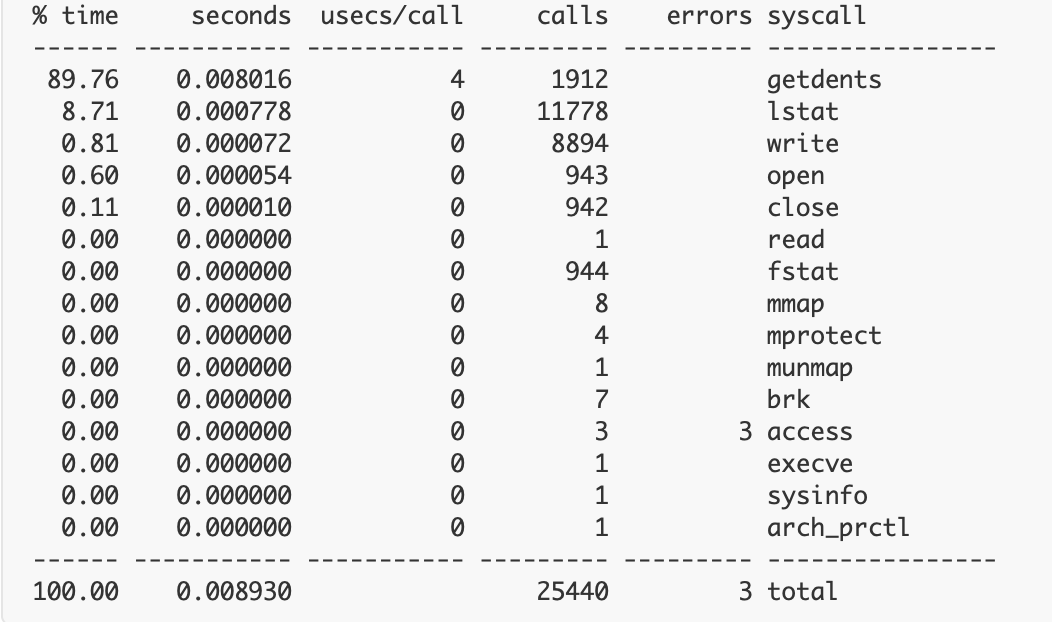
Strace – A Hidden Superpower
Akshat Goyal, Prathamesh Sonpatki

Infrastructure-As-Code-As-Software
Piyush Verma