

Deep dives

Think Data Warehouse, NOT Database.
Aniket Rao

The most important aspect of software monitoring
Aniket Rao

What needs to change in software monitoring?
Aniket Rao

How We Cut Monitoring Costs and Deprecated Thanos at Replit
Prathamesh Sonpatki

Back to the Future: The R-C-A of alerting
Aditya Godbole

Launching Alert Studio
Aditya Godbole

Everything in software monitoring is dead, apparently
Aniket Rao

Software Monitoring — Stuck in the 00s
Piyush Verma

A checklist to choose a monitoring system
Prathamesh Sonpatki

Why your monitoring costs are high
Aniket Rao

The unresolved cost of High Cardinality
Prathamesh Sonpatki

Why you need a Time Series Data Warehouse
Rishi Agrawal

Building Logs to Metrics pipelines with Vector
Aniket Rao

This arctic winter — time to repay your tech debt
Ajey Gore
A case for Observability outside engineering teams
Aniket Rao
Understanding the Rasmussen model for failures
Nishant Modak

1979, a nuclear accident and SRE
Aniket Rao

What Site Reliability Engineering Needs: A Swarm of Bees
Aniket Rao

Take back control of your Monitoring
Nishant Modak

Observability is a practice, not a job
Aniket Rao

Who should define Reliability — Engineering, or Product?
Piyush Verma

What do self-driving cars tell us about Site Reliability Engineering?
Mohan Dutt Parashar

Observability—OSS vs Paid vs Managed OSS
Satyajeet Jadhav

The neglected tech arctic winter — Internal SaaS expenses
Nishant Modak

Understanding “Cricket Scale”
Aniket Rao

Reliability Engineering for Dummies: ELI5
Mohan Dutt Parashar
When should I start thinking of observability?
Piyush Verma
The importance of structured communication in the world of SRE
Saurabh Hirani
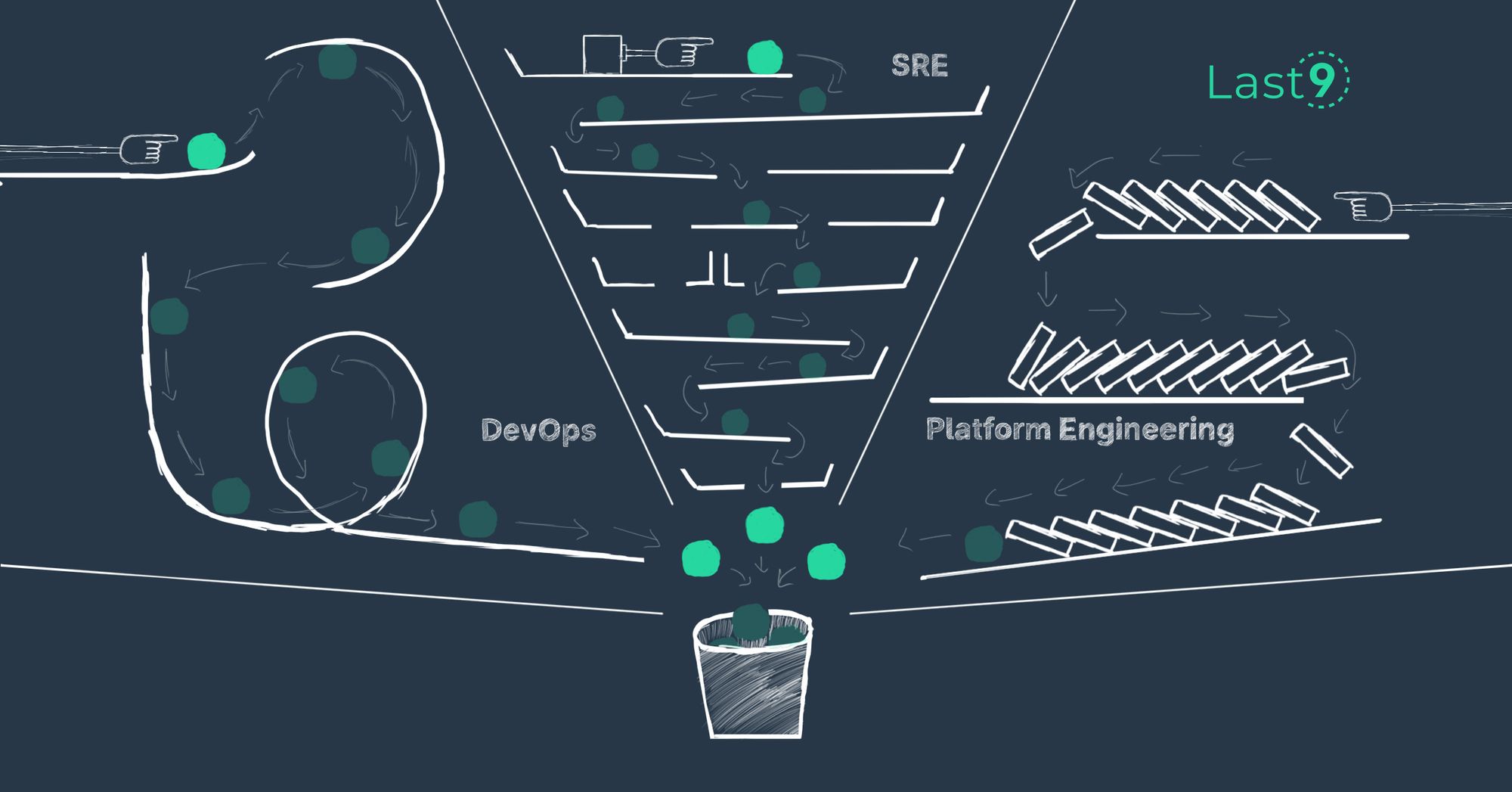
The difference between DevOps, SRE, and Platform Engineering
Prathamesh Sonpatki
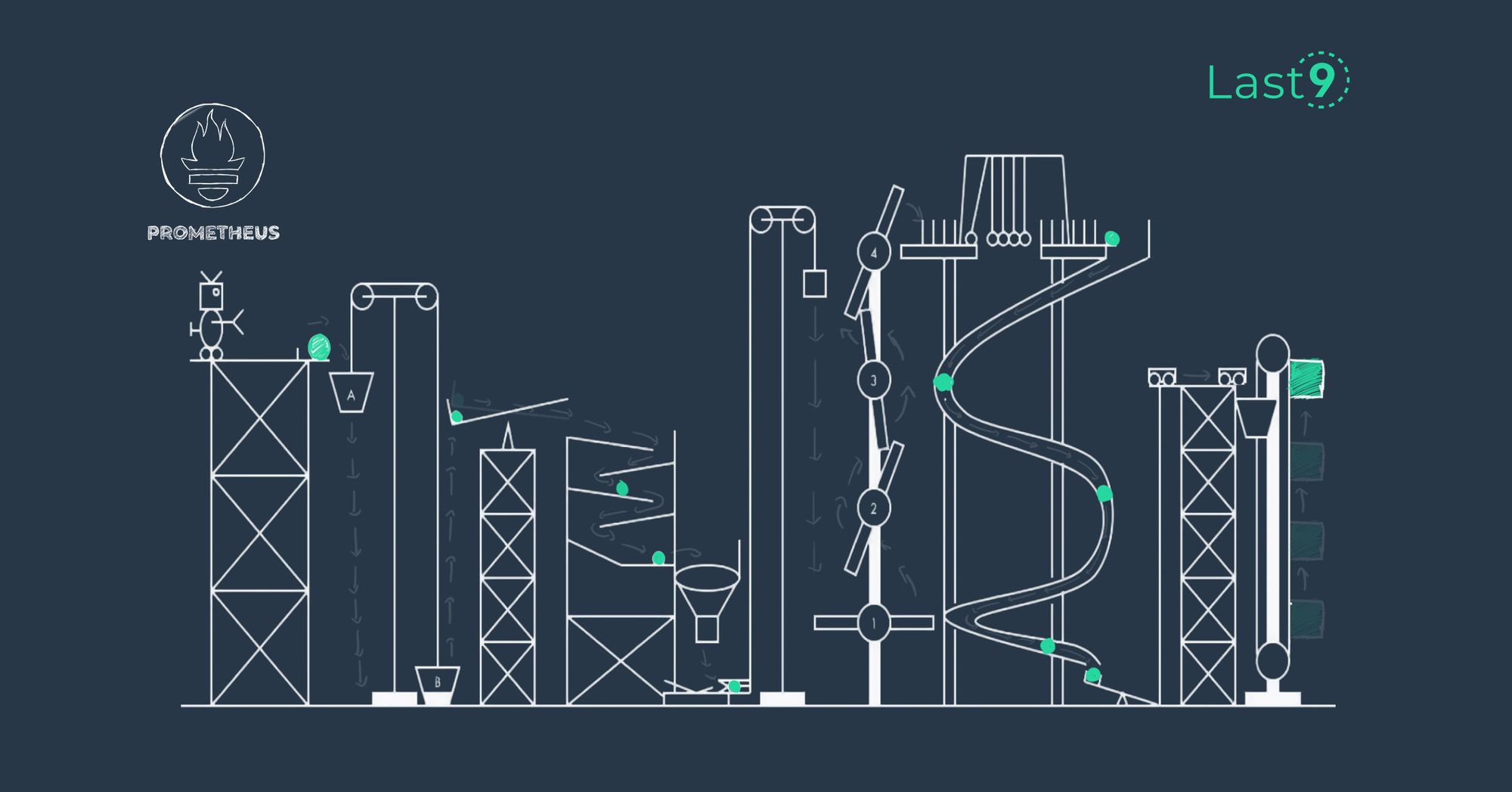
How to improve Prometheus remote write performance at scale
Saurabh Hirani
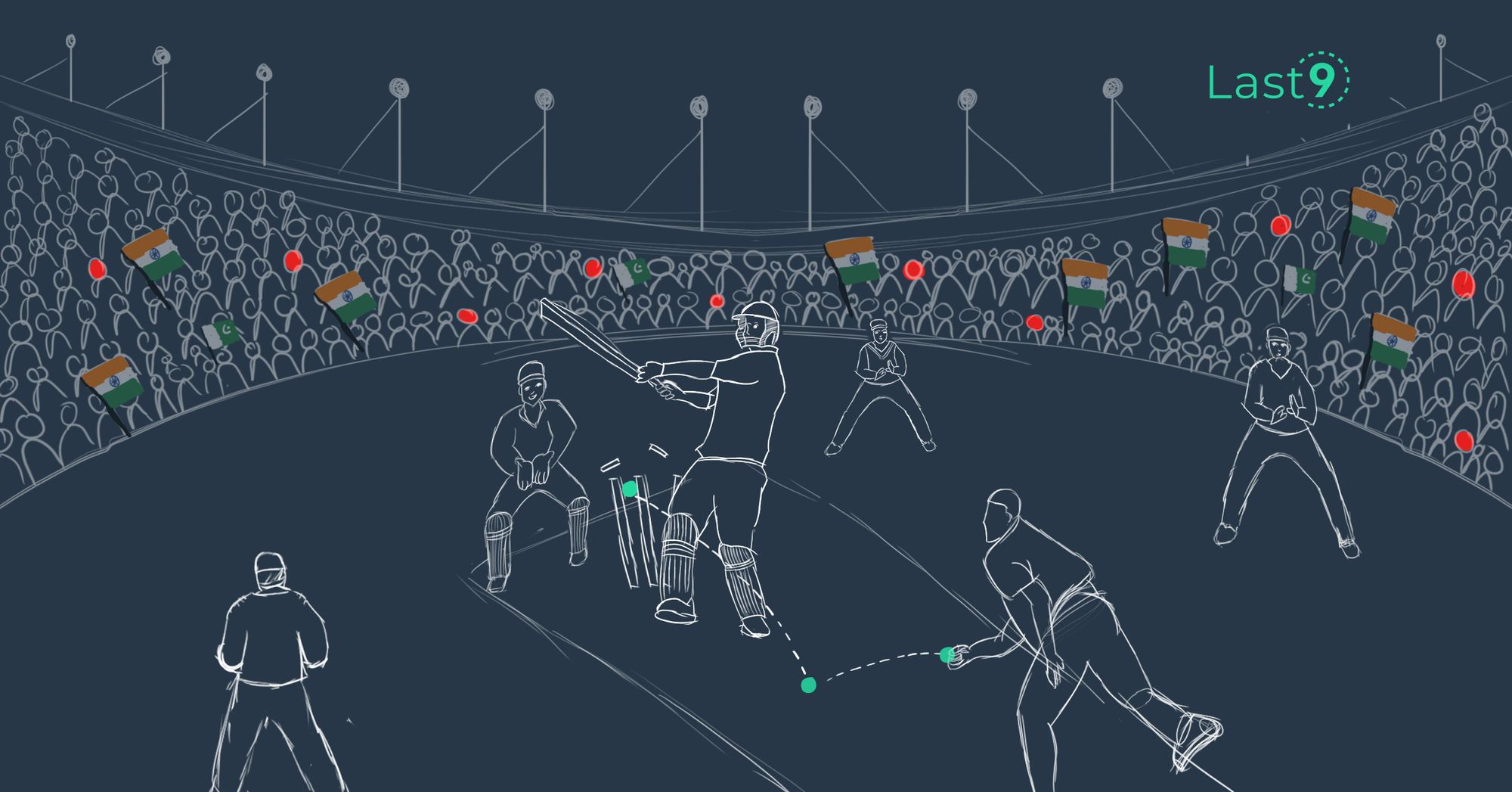
India vs Pakistan: SRE and the Shannon Limit
Satyajeet Jadhav
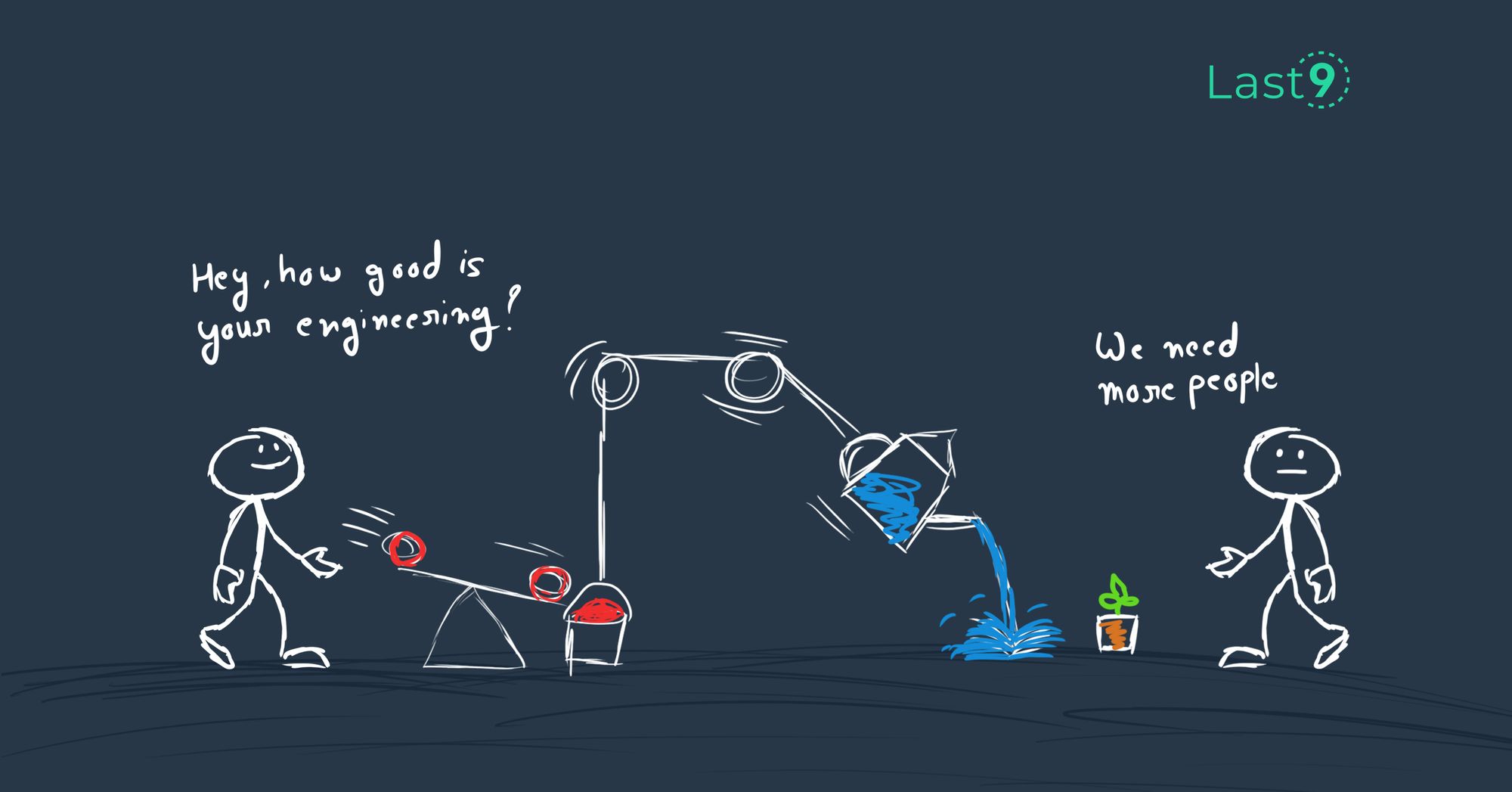
Why MTTR should be a ‘business’ metric
Sidu Ponnappa

Observability - That Last 9
Akash Saxena

How we won Dukaan over
Aniket Rao

Getting the big picture with Log Analysis
Jayesh Bapu Ahire

Microservices - Tracking Dependencies
Akshay Chugh, Jayesh Bapu Ahire

Infrastructure-As-Code-As-Software
Piyush Verma